
 spark基础
spark基础
基础知识
小项目入门:word count
源文件:wikiOfSpark.txt
Apache Spark
From Wikipedia, the free encyclopedia
Jump to navigationJump to search
Apache Spark
Spark Logo
Original author(s) Matei Zaharia
Developer(s) Apache Spark
Initial release May 26, 2014; 6 years ago
Stable release
3.1.1 / March 2, 2021; 2 months ago
Repository Spark Repository
Written in Scala[1]
Operating system Microsoft Windows, macOS, Linux
Available in Scala, Java, SQL, Python, R, C#, F#
Type Data analytics, machine learning algorithms
License Apache License 2.0
Website spark.apache.org Edit this at Wikidata
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.
Contents
1 Overview
1.1 Spark Core
1.2 Spark SQL
1.3 Spark Streaming
1.4 MLlib Machine Learning Library
1.5 GraphX
1.6 Language support
2 History
2.1 Developers
3 See also
4 Notes
5 References
6 External links
Overview
Apache Spark has its architectural foundation in the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way.[2] The Dataframe API was released as an abstraction on top of the RDD, followed by the Dataset API. In Spark 1.x, the RDD was the primary application programming interface (API), but as of Spark 2.x use of the Dataset API is encouraged[3] even though the RDD API is not deprecated.[4][5] The RDD technology still underlies the Dataset API.[6][7]
Spark and its RDDs were developed in 2012 in response to limitations in the MapReduce cluster computing paradigm, which forces a particular linear dataflow structure on distributed programs: MapReduce programs read input data from disk, map a function across the data, reduce the results of the map, and store reduction results on disk. Spark's RDDs function as a working set for distributed programs that offers a (deliberately) restricted form of distributed shared memory.[8]
Spark facilitates the implementation of both iterative algorithms, which visit their data set multiple times in a loop, and interactive/exploratory data analysis, i.e., the repeated database-style querying of data. The latency of such applications may be reduced by several orders of magnitude compared to Apache Hadoop MapReduce implementation.[2][9] Among the class of iterative algorithms are the training algorithms for machine learning systems, which formed the initial impetus for developing Apache Spark.[10]
Apache Spark requires a cluster manager and a distributed storage system. For cluster management, Spark supports standalone (native Spark cluster, where you can launch a cluster either manually or use the launch scripts provided by the install package. It is also possible to run these daemons on a single machine for testing), Hadoop YARN, Apache Mesos or Kubernetes. [11] For distributed storage, Spark can interface with a wide variety, including Alluxio, Hadoop Distributed File System (HDFS),[12] MapR File System (MapR-FS),[13] Cassandra,[14] OpenStack Swift, Amazon S3, Kudu, Lustre file system,[15] or a custom solution can be implemented. Spark also supports a pseudo-distributed local mode, usually used only for development or testing purposes, where distributed storage is not required and the local file system can be used instead; in such a scenario, Spark is run on a single machine with one executor per CPU core.
Spark Core
Spark Core is the foundation of the overall project. It provides distributed task dispatching, scheduling, and basic I/O functionalities, exposed through an application programming interface (for Java, Python, Scala, .NET[16] and R) centered on the RDD abstraction (the Java API is available for other JVM languages, but is also usable for some other non-JVM languages that can connect to the JVM, such as Julia[17]). This interface mirrors a functional/higher-order model of programming: a "driver" program invokes parallel operations such as map, filter or reduce on an RDD by passing a function to Spark, which then schedules the function's execution in parallel on the cluster.[2] These operations, and additional ones such as joins, take RDDs as input and produce new RDDs. RDDs are immutable and their operations are lazy; fault-tolerance is achieved by keeping track of the "lineage" of each RDD (the sequence of operations that produced it) so that it can be reconstructed in the case of data loss. RDDs can contain any type of Python, .NET, Java, or Scala objects.
Besides the RDD-oriented functional style of programming, Spark provides two restricted forms of shared variables: broadcast variables reference read-only data that needs to be available on all nodes, while accumulators can be used to program reductions in an imperative style.[2]
A typical example of RDD-centric functional programming is the following Scala program that computes the frequencies of all words occurring in a set of text files and prints the most common ones. Each map, flatMap (a variant of map) and reduceByKey takes an anonymous function that performs a simple operation on a single data item (or a pair of items), and applies its argument to transform an RDD into a new RDD.
val conf = new SparkConf().setAppName("wiki_test") // create a spark config object
val sc = new SparkContext(conf) // Create a spark context
val data = sc.textFile("/path/to/somedir") // Read files from "somedir" into an RDD of (filename, content) pairs.
val tokens = data.flatMap(_.split(" ")) // Split each file into a list of tokens (words).
val wordFreq = tokens.map((_, 1)).reduceByKey(_ + _) // Add a count of one to each token, then sum the counts per word type.
wordFreq.sortBy(s => -s._2).map(x => (x._2, x._1)).top(10) // Get the top 10 words. Swap word and count to sort by count.
Spark SQL
Spark SQL is a component on top of Spark Core that introduced a data abstraction called DataFrames,[a] which provides support for structured and semi-structured data. Spark SQL provides a domain-specific language (DSL) to manipulate DataFrames in Scala, Java, Python or .NET.[16] It also provides SQL language support, with command-line interfaces and ODBC/JDBC server. Although DataFrames lack the compile-time type-checking afforded by RDDs, as of Spark 2.0, the strongly typed DataSet is fully supported by Spark SQL as well.
import org.apache.spark.sql.SparkSession
val url = "jdbc:mysql://yourIP:yourPort/test?user=yourUsername;password=yourPassword" // URL for your database server.
val spark = SparkSession.builder().getOrCreate() // Create a Spark session object
val df = spark
.read
.format("jdbc")
.option("url", url)
.option("dbtable", "people")
.load()
df.printSchema() // Looks the schema of this DataFrame.
val countsByAge = df.groupBy("age").count() // Counts people by age
//or alternatively via SQL:
//df.createOrReplaceTempView("people")
//val countsByAge = spark.sql("SELECT age, count(*) FROM people GROUP BY age")
Spark Streaming
Spark Streaming uses Spark Core's fast scheduling capability to perform streaming analytics. It ingests data in mini-batches and performs RDD transformations on those mini-batches of data. This design enables the same set of application code written for batch analytics to be used in streaming analytics, thus facilitating easy implementation of lambda architecture.[19][20] However, this convenience comes with the penalty of latency equal to the mini-batch duration. Other streaming data engines that process event by event rather than in mini-batches include Storm and the streaming component of Flink.[21] Spark Streaming has support built-in to consume from Kafka, Flume, Twitter, ZeroMQ, Kinesis, and TCP/IP sockets.[22]
In Spark 2.x, a separate technology based on Datasets, called Structured Streaming, that has a higher-level interface is also provided to support streaming.[23]
Spark can be deployed in a traditional on-premises data center as well as in the cloud.
MLlib Machine Learning Library
Spark MLlib is a distributed machine-learning framework on top of Spark Core that, due in large part to the distributed memory-based Spark architecture, is as much as nine times as fast as the disk-based implementation used by Apache Mahout (according to benchmarks done by the MLlib developers against the alternating least squares (ALS) implementations, and before Mahout itself gained a Spark interface), and scales better than Vowpal Wabbit.[24] Many common machine learning and statistical algorithms have been implemented and are shipped with MLlib which simplifies large scale machine learning pipelines, including:
summary statistics, correlations, stratified sampling, hypothesis testing, random data generation[25]
classification and regression: support vector machines, logistic regression, linear regression, naive Bayes classification, Decision Tree, Random Forest, Gradient-Boosted Tree
collaborative filtering techniques including alternating least squares (ALS)
cluster analysis methods including k-means, and latent Dirichlet allocation (LDA)
dimensionality reduction techniques such as singular value decomposition (SVD), and principal component analysis (PCA)
feature extraction and transformation functions
optimization algorithms such as stochastic gradient descent, limited-memory BFGS (L-BFGS)
GraphX
GraphX is a distributed graph-processing framework on top of Apache Spark. Because it is based on RDDs, which are immutable, graphs are immutable and thus GraphX is unsuitable for graphs that need to be updated, let alone in a transactional manner like a graph database.[26] GraphX provides two separate APIs for implementation of massively parallel algorithms (such as PageRank): a Pregel abstraction, and a more general MapReduce-style API.[27] Unlike its predecessor Bagel, which was formally deprecated in Spark 1.6, GraphX has full support for property graphs (graphs where properties can be attached to edges and vertices).[28]
GraphX can be viewed as being the Spark in-memory version of Apache Giraph, which utilized Hadoop disk-based MapReduce.[29]
Like Apache Spark, GraphX initially started as a research project at UC Berkeley's AMPLab and Databricks, and was later donated to the Apache Software Foundation and the Spark project.[30]
Language support
Apache Spark has built-in support for Scala, Java, R, and Python with 3rd party support for the .net languages,[31] Julia,[32] and more.
History
Spark was initially started by Matei Zaharia at UC Berkeley's AMPLab in 2009, and open sourced in 2010 under a BSD license.[33]
In 2013, the project was donated to the Apache Software Foundation and switched its license to Apache 2.0. In February 2014, Spark became a Top-Level Apache Project.[34]
In November 2014, Spark founder M. Zaharia's company Databricks set a new world record in large scale sorting using Spark.[35][33]
Spark had in excess of 1000 contributors in 2015,[36] making it one of the most active projects in the Apache Software Foundation[37] and one of the most active open source big data projects.
Version Original release date Latest version Release date
0.5 2012-06-12 0.5.1 2012-10-07
0.6 2012-10-14 0.6.2 2013-02-07
0.7 2013-02-27 0.7.3 2013-07-16
0.8 2013-09-25 0.8.1 2013-12-19
0.9 2014-02-02 0.9.2 2014-07-23
1.0 2014-05-26 1.0.2 2014-08-05
1.1 2014-09-11 1.1.1 2014-11-26
1.2 2014-12-18 1.2.2 2015-04-17
1.3 2015-03-13 1.3.1 2015-04-17
1.4 2015-06-11 1.4.1 2015-07-15
1.5 2015-09-09 1.5.2 2015-11-09
1.6 2016-01-04 1.6.3 2016-11-07
2.0 2016-07-26 2.0.2 2016-11-14
2.1 2016-12-28 2.1.3 2018-06-26
2.2 2017-07-11 2.2.3 2019-01-11
2.3 2018-02-28 2.3.4 2019-09-09
2.4 LTS 2018-11-02 2.4.7 2020-10-12[38]
3.0 2020-06-18 3.0.2 2020-02-19[39]
3.1 2021-03-02 3.1.1 2021-03-02[40]
Legend:Old versionOlder version, still maintainedLatest versionLatest preview version
Developers
Apache Spark is developed by a community. The project is managed by a group called the "Project Management Committee" (PMC). The current PMC is Aaron Davidson, Andy Konwinski, Andrew Or, Ankur Dave, Robert Joseph Evans, DB Tsai, Dongjoon Hyun, Felix Cheung, Hyukjin Kwon, Haoyuan Li, Ram Sriharsha, Holden Karau, Herman van Hövell, Imran Rashid, Jason Dai, Joseph Kurata Bradley, Joseph E. Gonzalez, Josh Rosen, Jerry Shao, Kay Ousterhout, Cheng Lian, Xiao Li, Mark Hamstra, Michael Armbrust, Matei Zaharia, Xiangrui Meng, Nicholas Pentreath, Mosharaf Chowdhury, Mridul Muralidharan, Prashant Sharma, Patrick Wendell, Reynold Xin, Ryan LeCompte, Shane Huang, Shivaram Venkataraman, Sean McNamara, Sean R. Owen, Stephen Haberman, Tathagata Das, Thomas Graves, Thomas Dudziak, Takuya Ueshin, Marcelo Masiero Vanzin, Wenchen Fan, Charles Reiss, Andrew Xia, Yin Huai, Yanbo Liang, Shixiong Zhu.[41]
See also
List of concurrent and parallel programming APIs/Frameworks
Notes
Called SchemaRDDs before Spark 1.3[18]
References
"Spark Release 2.0.0". MLlib in R: SparkR now offers MLlib APIs [..] Python: PySpark now offers many more MLlib algorithms"
Zaharia, Matei; Chowdhury, Mosharaf; Franklin, Michael J.; Shenker, Scott; Stoica, Ion. Spark: Cluster Computing with Working Sets (PDF). USENIX Workshop on Hot Topics in Cloud Computing (HotCloud).
"Spark 2.2.0 Quick Start". apache.org. 2017-07-11. Retrieved 2017-10-19. we highly recommend you to switch to use Dataset, which has better performance than RDD
"Spark 2.2.0 deprecation list". apache.org. 2017-07-11. Retrieved 2017-10-10.
Damji, Jules (2016-07-14). "A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets: When to use them and why". databricks.com. Retrieved 2017-10-19.
Chambers, Bill (2017-08-10). "12". Spark: The Definitive Guide. O'Reilly Media. virtually all Spark code you run, where DataFrames or Datasets, compiles down to an RDD
"What is Apache Spark? Spark Tutorial Guide for Beginner". janbasktraining.com. 2018-04-13. Retrieved 2018-04-13.
Zaharia, Matei; Chowdhury, Mosharaf; Das, Tathagata; Dave, Ankur; Ma, Justin; McCauley, Murphy; J., Michael; Shenker, Scott; Stoica, Ion (2010). Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing (PDF). USENIX Symp. Networked Systems Design and Implementation.
Xin, Reynold; Rosen, Josh; Zaharia, Matei; Franklin, Michael; Shenker, Scott; Stoica, Ion (June 2013). "Shark: SQL and Rich Analytics at Scale" (PDF). arXiv:1211.6176. Bibcode:2012arXiv1211.6176X. Unknown parameter |conference= ignored (help);
Harris, Derrick (28 June 2014). "4 reasons why Spark could jolt Hadoop into hyperdrive". Gigaom.
"Cluster Mode Overview - Spark 2.4.0 Documentation - Cluster Manager Types". apache.org. Apache Foundation. 2019-07-09. Retrieved 2019-07-09.
Figure showing Spark in relation to other open-source Software projects including Hadoop
MapR ecosystem support matrix
Doan, DuyHai (2014-09-10). "Re: cassandra + spark / pyspark". Cassandra User (Mailing list). Retrieved 2014-11-21.
Wang, Yandong; Goldstone, Robin; Yu, Weikuan; Wang, Teng (May 2014). "Characterization and Optimization of Memory-Resident MapReduce on HPC Systems". 2014 IEEE 28th International Parallel and Distributed Processing Symposium. IEEE. pp. 799–808. doi:10.1109/IPDPS.2014.87. ISBN 978-1-4799-3800-1. S2CID 11157612.
dotnet/spark, .NET Platform, 2020-09-14, retrieved 2020-09-14
"GitHub - DFDX/Spark.jl: Julia binding for Apache Spark". 2019-05-24.
"Spark Release 1.3.0 | Apache Spark".
"Applying the Lambda Architecture with Spark, Kafka, and Cassandra | Pluralsight". www.pluralsight.com. Retrieved 2016-11-20.
Shapira, Gwen (29 August 2014). "Building Lambda Architecture with Spark Streaming". cloudera.com. Cloudera. Archived from the original on 14 June 2016. Retrieved 17 June 2016. re-use the same aggregates we wrote for our batch application on a real-time data stream
Chintapalli, Sanket; Dagit, Derek; Evans, Bobby; Farivar, Reza; Graves, Thomas; Holderbaugh, Mark; Liu, Zhuo; Nusbaum, Kyle; Patil, Kishorkumar; Peng, Boyang Jerry; Poulosky, Paul (May 2016). "Benchmarking Streaming Computation Engines: Storm, Flink and Spark Streaming". 2016 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE. pp. 1789–1792. doi:10.1109/IPDPSW.2016.138. ISBN 978-1-5090-3682-0. S2CID 2180634.
Kharbanda, Arush (17 March 2015). "Getting Data into Spark Streaming". sigmoid.com. Sigmoid (Sunnyvale, California IT product company). Archived from the original on 15 August 2016. Retrieved 7 July 2016.
Zaharia, Matei (2016-07-28). "Structured Streaming In Apache Spark: A new high-level API for streaming". databricks.com. Retrieved 2017-10-19.
Sparks, Evan; Talwalkar, Ameet (2013-08-06). "Spark Meetup: MLbase, Distributed Machine Learning with Spark". slideshare.net. Spark User Meetup, San Francisco, California. Retrieved 10 February 2014.
"MLlib | Apache Spark". spark.apache.org. Retrieved 2016-01-18.
Malak, Michael (14 June 2016). "Finding Graph Isomorphisms In GraphX And GraphFrames: Graph Processing vs. Graph Database". slideshare.net. sparksummit.org. Retrieved 11 July 2016.
Malak, Michael (1 July 2016). Spark GraphX in Action. Manning. p. 89. ISBN 9781617292521. Pregel and its little sibling aggregateMessages() are the cornerstones of graph processing in GraphX. ... algorithms that require more flexibility for the terminating condition have to be implemented using aggregateMessages()
Malak, Michael (14 June 2016). "Finding Graph Isomorphisms In GraphX And GraphFrames: Graph Processing vs. Graph Database". slideshare.net. sparksummit.org. Retrieved 11 July 2016.
Malak, Michael (1 July 2016). Spark GraphX in Action. Manning. p. 9. ISBN 9781617292521. Giraph is limited to slow Hadoop Map/Reduce
Gonzalez, Joseph; Xin, Reynold; Dave, Ankur; Crankshaw, Daniel; Franklin, Michael; Stoica, Ion (Oct 2014). "GraphX: Graph Processing in a Distributed Dataflow Framework" (PDF). Unknown parameter |conference= ignored (help);
[1]
[2]
Clark, Lindsay. "Apache Spark speeds up big data decision-making". ComputerWeekly.com. Retrieved 2018-05-16.
"The Apache Software Foundation Announces Apache™ Spark™ as a Top-Level Project". apache.org. Apache Software Foundation. 27 February 2014. Retrieved 4 March 2014.
Spark officially sets a new record in large-scale sorting
Open HUB Spark development activity
"The Apache Software Foundation Announces Apache™ Spark™ as a Top-Level Project". apache.org. Apache Software Foundation. 27 February 2014. Retrieved 4 March 2014.
"Spark News". apache.org.
"Spark News". apache.org.
"Spark News". apache.org.
https://projects.apache.org/committee.html?spark
External links
Official website Edit this at Wikidata
vte
Apache Software Foundation
vte
Parallel computing
Categories: Apache Software Foundation projectsBig data productsCluster computingData mining and machine learning softwareFree software programmed in ScalaHadoopJava platformSoftware using the Apache licenseUniversity of California, Berkeley
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
# 1.安装spark
下载spark Spark 3.4.2 (opens new window):
①下载安装包:从Spark 官网下载安装包,选择最新的预编译版本即可;https://spark.apache.org/downloads.html
②解压:解压 Spark 安装包到任意本地目录;
③配置:将“${解压目录}/bin”配置到 PATH 环境变量。
spark-shell --version
使用spark-shell前提,需要安装java和scala Scala 2.13.
# 2. 基本使用
word count 业务就是对一串文本中单词出现频率最高的单词进行排序。
首先我们文本的读取都是以行来读取的。
大概分为以下步骤:
①读取内容:调用 Spark 文件读取 API,加载 wikiOfSpark.txt 文件内容;
②分词:以行为单位,把句子打散为单词;
③分组计数:按照单词做分组计数。
scala代码:
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = "/Users/zhengjian/Documents"
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
怎么执行?
应用开发完成之后,我们就可以把代码丢进已经准备好的本地 Spark 部署环境里啦。首先,我们打开命令行终端(Terminal),敲入“spark-shell”,打开交互式运行环境,如下图所示。
spark-shell启动界面然后,把我们开发好的代码,依次敲入 spark-shell。

在 Wikipedia 的 Spark 介绍文本中,词频最高的单词分别是 the、Spark、a、and 和 of,除了“Spark”之外,其他 4 个单词都是常用的停用词(Stop Word),因此它们几个高居榜首也就不足为怪了。
在 Word Count 的代码实现中,我们用到了多种多样的 RDD 算子,如 map、filter、flatMap 和 reduceByKey,除了这些算子以外,你知道还有哪些常用的 RDD 算子吗?(提示,可以结合官网去查找)。
- 什么是算子?
通常指的是在数据处理过程中,对数据进行操作的函数或方法。这些函数或方法可以对数据进行各种操作,如映射、过滤、聚合、排序等。
例如,在Apache Spark这样的大数据处理框架中,就定义了很多算子,如map、filter、reduce、join等。这些算子可以对大规模的数据进行并行处理,实现各种复杂的数据分析任务。
# 3. RDD
什么是rdd:
RDD 是一种抽象,是 Spark 对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体(Resilient Distributed Datasets,弹性分布式数据集)是其核心的数据结构。
RDD是一个容错的、并行的数据对象,可以在Spark集群中的节点间进行分布式计算。每个RDD都被分为多个分区,每个分区的数据都会被处理成一个任务,分配到各个工作节点上并行计算。
- rdd四大属性:
partitions:数据分片
partitioner:分片切割规则
dependencies:RDD 依赖
compute:转换函数

拿 Word Count 当中的 wordRDD 来举例,它的父 RDD 是 lineRDD,因此,它的 dependencies 属性记录的是 lineRDD。从 lineRDD 到 wordRDD 的转换,其所依赖的操作是 flatMap,因此,wordRDD 的 compute 属性,记录的是 flatMap 这个转换函数。
# 4. RDD 的编程模型和延迟计算
在 RDD 的编程模型中,一共有两种算子,Transformations 类算子和 Actions 类算子。开发者需要使用 Transformations 类算子,定义并描述数据形态的转换过程,然后调用 Actions 类算子,将计算结果收集起来、或是物化到磁盘。
在这样的编程模型下,Spark 在运行时的计算被划分为两个环节。
- 基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph);
- 通过 Actions 类算子,以回溯的方式去触发执行这个计算流图。
换句话说,开发者调用的各类 Transformations 算子,并不立即执行计算,当且仅当开发者调用 Actions 算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式有个专门的术语,叫作“延迟计算”(Lazy Evaluation)。
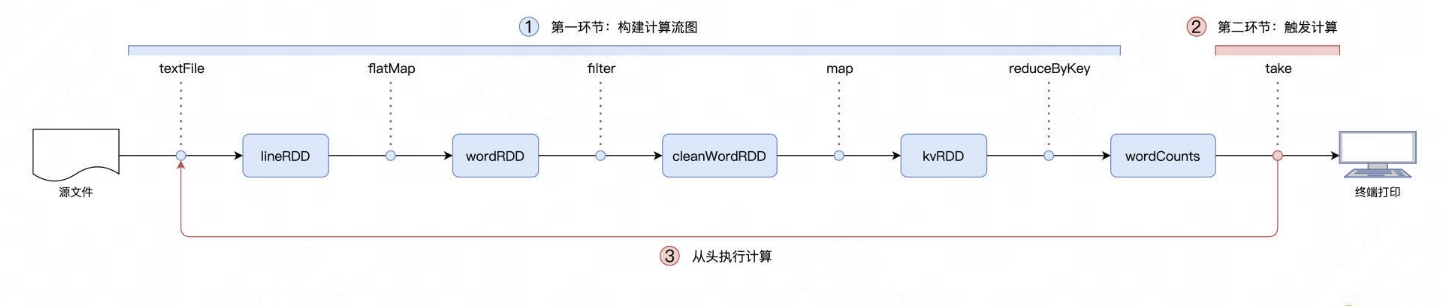
那么spark采用这种延迟计算的优缺点在什么地方呢?
在Spark中,延迟计算(也称为惰性计算)是其核心特性之一。这意味着当你对RDD进行转换操作(如map、filter等)时,这些操作并不会立即执行,而是会记录下来,形成一个转换操作的序列,也就是RDD的血统信息(Lineage)。只有当遇到行动操作(如count、collect等)时,这些转换操作才会真正执行。
采用延迟计算,有以下优点:
- 效率:通过延迟计算,Spark可以优化整个计算过程,避免不必要的计算和数据传输。例如,如果你只需要数据集的前10个元素,那么Spark只会计算这10个元素,而不是整个数据集。
- 容错:延迟计算使得Spark可以在节点失败时,通过血统信息重新计算丢失的数据,而不需要进行数据的备份和恢复。
- 简化编程:用户只需要关心数据的逻辑处理流程,而不需要关心何时执行这些操作,这使得编程更加简单。
但是,延迟计算也有一些缺点:
- 调试困难:由于转换操作不会立即执行,因此在调试代码时,可能会遇到一些困难,例如,你无法立即看到转换操作的结果。
- 难以预测性能:由于计算是延迟执行的,所以在编写代码时,可能难以预测程序的性能。
- 常见的transformation和action算子如下:
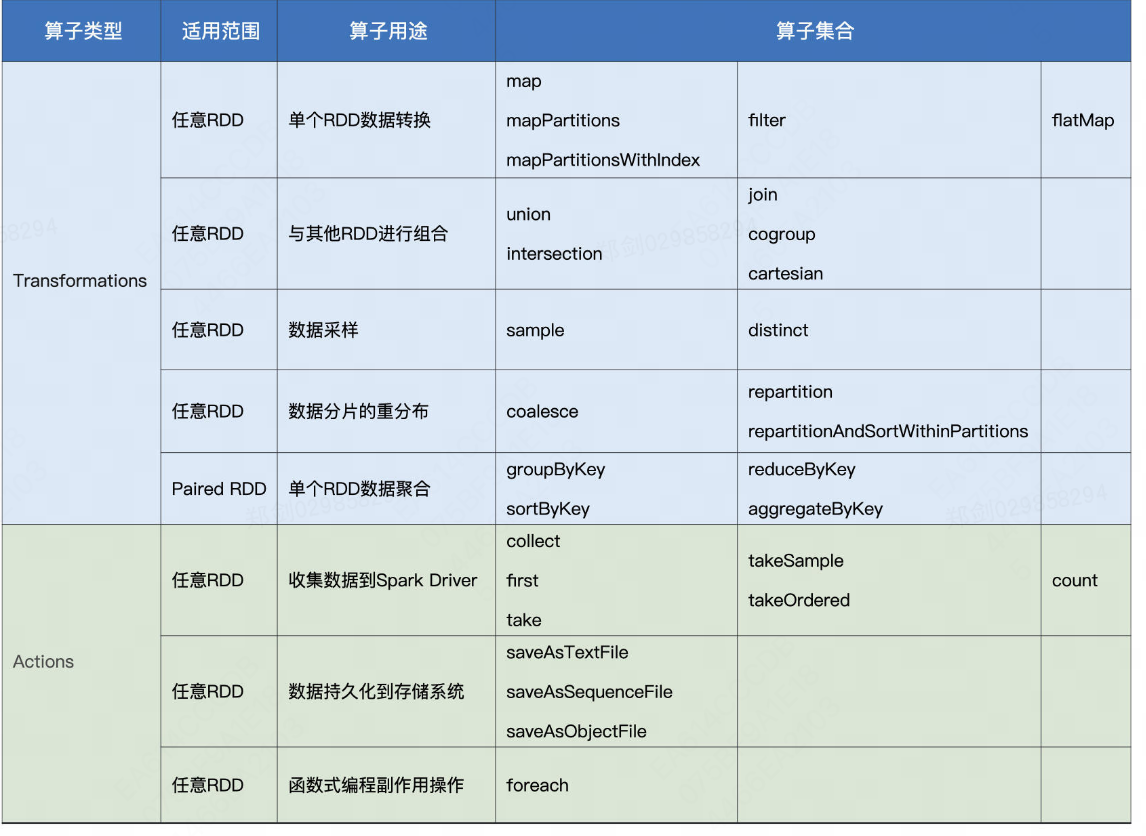
# 5. 常用算子
# 如何创建RDD:
通过 SparkContext.parallelize 在内部数据之上创建 RDD。
import org.apache.spark.rdd.RDD
val words: Array[String] = Array("Spark", "is", "cool")
val rdd: RDD[String] = sc.parallelize(words)
2
3
通过 SparkContext.textFile 等 API 从外部数据创建 RDD。
// 把普通RDD转换为Paired RDD
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
2
3
开发者在 Spark 应用中自定义的各类数据结构,如数组、列表、映射等,都属于“内部数据”;而“外部数据”指代的,是 Spark 系统之外的所有数据形式,如本地文件系统或是分布式文件系统中的数据,再比如来自其他大数据组件(Hive、Hbase、RDBMS 等)的数据。因为我们本来使用就应该用大量的数据集,所以我们常用 SparkContext.textFile 等 API 来创建RDD数据集。
# ①map
内部数据转换
map:以元素为粒度的数据转换
给定映射函数 f,map(f) 以元素为粒度对 RDD 做数据转换
其中f可以是匿名函数,也可以是定义好的函数签名
// 把普通RDD转换为Paired RDD
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 把RDD元素转换为(Key,Value)的形式
// 定义映射函数f
def f(word: String): (String, Int) = {
return (word, 1)
}
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(f)
2
3
4
5
6
7
8
9
10
11
12
13
14
上面的map都是以rdd的元素作为粒度进行计算的。但是有时候如果使用元素为粒度进行计算,可能会出现一些问题。例如下方代码:
// 把普通RDD转换为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map{ word =>
// 获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
// 使用MD5计算哈希值
val hash = md5.digest(word.getBytes).mkString
// 返回哈希值与数字1的Pair
(hash, 1)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
这里可以看到,以元素为粒度进行转换,每次装换都需要获得一个md5对象,那么当我们数据量非常大时,那岂不是内存直接吃爆了?所以这里我们可用把md5设置成公用的,这个时候,mapPartitions就可以以分区的粒度来进行计算了。
# ②mapPartitions
// 把普通RDD转换为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => {
// 注意!这里是以数据分区为粒度,获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
val newPartition = partition.map( word => {
// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象
(md5.digest(word.getBytes()).mkString,1)
})
newPartition
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
这里可以看到,我们会现在每一个分区中,先得到对应的md5,再在map中以元素粒度去进行计算,这样的话可以大幅度提升效率。像这种公用的属性、connection连接池等,都可以放到mapPartition中进行提前获取。
map和mapPartition在md5的获取上,有如下的优化点:
以数据分区为单位,mapPartitions 只需实例化一次 MD5 对象,而 map 算子却需要实例化多次,具体的次数则由分区内数据记录的数量来决定。

# ③mapPartitionsWithIndex
和mapPartitions差不多,不过在其f函数中,其入参增加了一个index表示当前的分区,用户可以在计算时知道自己当前属于哪一个分区:
举例:
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
val result = rdd.mapPartitionsWithIndex((index, iter) => {
iter.map(x => "[partID:" + index + ", val: " + x + "]")
})
result.collect().foreach(println)
2
3
4
5
在这个例子中,我们首先创建了一个包含9个元素的RDD,然后将这个RDD分为3个分区。然后我们使用mapPartitionsWithIndex对每个分区的数据进行处理,我们将每个元素的值和它所在的分区ID一起返回。最后,我们将处理后的数据收集到驱动程序,并打印出来。
你将看到类似以下的输出:
[partID:0, val: 1]
[partID:0, val: 2]
[partID:0, val: 3]
[partID:1, val: 4]
[partID:1, val: 5]
[partID:1, val: 6]
[partID:2, val: 7]
[partID:2, val: 8]
[partID:2, val: 9]
2
3
4
5
6
7
8
9
这个输出显示了每个元素的值和它所在的分区ID,你可以看到元素1、2、3在分区0,元素4、5、6在分区1,元素7、8、9在分区2。
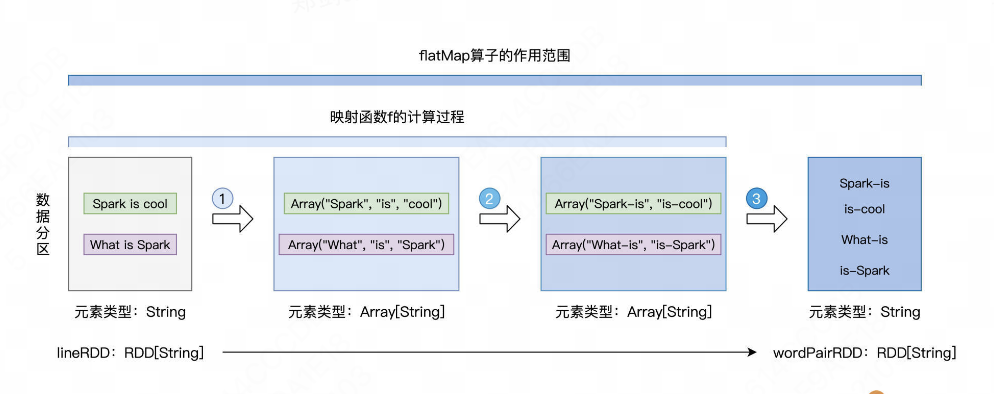
# ④flatMap
先从例子说起:
首先,我们创建了一个包含两个字符串的RDD:
val rdd = sc.parallelize(List("Hello world", "I am learning Spark"))
这个RDD包含两个元素,分别是"Hello world"和"I am learning Spark"。
然后,我们对这个RDD应用了flatMap操作:
val result = rdd.flatMap(line => line.split(" "))
这个split将一个元素转化成了数组,例如array["Hello","world"]和["I", "am" ,"learning", "Spark"]
紧接着,flatMap会把这个数组给扁平化,即去掉外层的数组,这意味着,原本属于同一个元素的多个单词现在都成为了新RDD的独立元素。所以,新的RDD中的元素会比原RDD中的元素多。
最终rdd数据的元素为:
result.collect().foreach(println)
Hello
world
I
am
learning
Spark
2
3
4
5
6
总结:flatMap可以看做两个部分:
以元素为单位,创建集合;
去掉集合“外包装”,提取集合元素。
# ⑤filter
// 定义特殊字符列表
val list: List[String] = List("&", "|", "#", "^", "@")
// 定义判定函数f
def f(s: String): Boolean = {
val words: Array[String] = s.split("-")
val b1: Boolean = list.contains(words(0))
val b2: Boolean = list.contains(words(1))
return !b1 && !b2 // 返回不在特殊字符列表中的词汇对
}
// 使用filter(f)对RDD进行过滤
val cleanedPairRDD: RDD[String] = wordPairRDD.filter(f)
2
3
4
5
6
7
8
9
10
11
12
13
函数f为入参为rdd元素,返回值为boolean,返回true即为要保留的元素,false就是需要过滤掉的元素
# 6. 进程模型
在 Spark 的应用开发中,任何一个应用程序的入口,都是带有 SparkSession 的 main 函数。SparkSession 包罗万象,它在提供 Spark 运行时上下文的同时(如调度系统、存储系统、内存管理、RPC 通信),也可以为开发者提供创建、转换、计算分布式数据集(如 RDD)的开发 API。
不过,在 Spark 分布式计算环境中,有且仅有一个 JVM 进程运行这样的 main 函数,这个特殊的 JVM 进程,在 Spark 中有个专门的术语,叫作“Driver”。Driver 最核心的作用在于,解析用户代码、构建计算流图,然后将计算流图转化为分布式任务,并把任务分发给集群中的执行进程交付运行。
换句话说,Driver 的角色是拆解任务、派活儿,而真正干活儿的“苦力”,是执行进程。在 Spark 的分布式环境中,这样的执行进程可以有一个或是多个,它们也有专门的术语,叫作“Executor”。
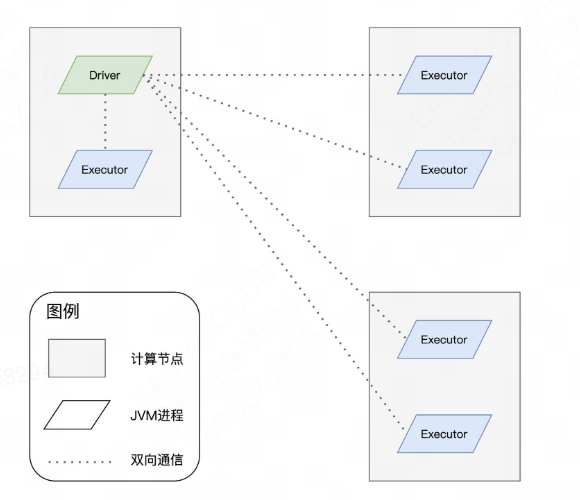
分布式计算的核心是任务调度,而分布式任务的调度与执行,仰仗的是 Driver 与 Executors 之间的通力合作
在Driver进程中有3个比较核心的组件:
- 根据用户代码构建计算流图;DAGScheduler
- 根据计算流图拆解出分布式任务;TaskScheduler
- 将分布式任务分发到 Executors 中去;SchedulerBackend
- wordCount按理解析:
当我们使用spark-shell命令时,一般会是下面的默认命令:
spark-shell --master local[*]
第一层含义是部署模式,其中 local 关键字表示部署模式为 Local,也就是本地部署;第二层含义是部署规模,也就是方括号里面的数字,它表示的是在本地部署中需要启动多少个 Executors,星号则意味着这个数量与机器中可用 CPU 的个数相一致。假设你的笔记本电脑有 4 个 CPU,那么当你在命令行敲入 spark-shell 的时候,Spark 会在后台启动 1 个 Driver 进程和 3 个 Executors 进程。
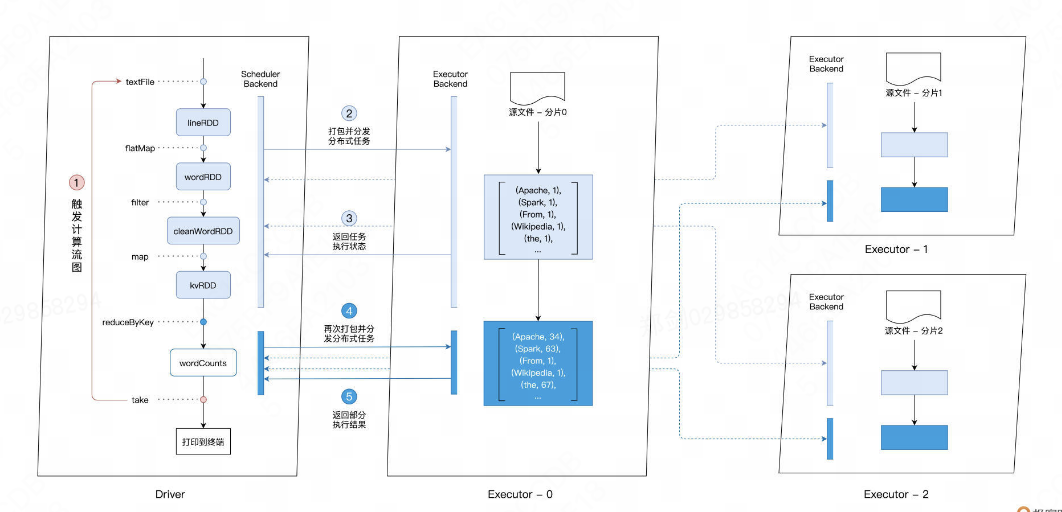
首先,Driver 通过 take 这个 Action 算子,来触发执行先前构建好的计算流图。沿着计算流图的执行方向,也就是图中从上到下的方向,Driver 以 Shuffle 为边界创建、分发分布式任务。Shuffle 的本意是扑克牌中的“洗牌”,在大数据领域的引申义,表示的是集群范围内跨进程、跨节点的数据交换。
在 reduceByKey 算子之前,同一个单词,比如“spark”,可能散落在不用的 Executors 进程,比如图中的 Executor-0、Executor-1 和 Executor-2。换句话说,这些 Executors 处理的数据分片中,都包含单词“spark”。那么,要完成对“spark”的计数,我们需要把所有“spark”分发到同一个 Executor 进程,才能完成计算。而这个把原本散落在不同 Executors 的单词,分发到同一个 Executor 的过程,就是 Shuffle。
对于 reduceByKey 之前的所有操作,也就是 textFile、flatMap、filter、map 等,Driver 会把它们“捏合”成一份任务,然后一次性地把这份任务打包、分发给每一个 Executors。三个 Executors 接收到任务之后,先是对任务进行解析,把任务拆解成 textFile、flatMap、filter、map 这 4 个步骤,然后分别对自己负责的数据分片进行处理。
为了方便说明,我们不妨假设并行度为 3,也就是原始数据文件 wikiOfSpark.txt 被切割成了 3 份,这样每个 Executors 刚好处理其中的一份。数据处理完毕之后,分片内容就从原来的 RDD[String]转换成了包含键值对的 RDD[(String, Int)],其中每个单词的计数都置位 1。
此时 Executors 会及时地向 Driver 汇报自己的工作进展,从而方便 Driver 来统一协调大家下一步的工作。这个时候,要继续进行后面的聚合计算,也就是计数操作,就必须进行刚刚说的 Shuffle 操作。在不同 Executors 完成单词的数据交换之后,Driver 继续创建并分发下一个阶段的任务,也就是按照单词做分组计数。数据交换之后,所有相同的单词都分发到了相同的 Executors 上去,这个时候,各个 Executors 拿到 reduceByKey 的任务,只需要各自独立地去完成统计计数即可。完成计数之后,Executors 会把最终的计算结果统一返回给 Driver。这样一来,spark-shell 便完成了 Word Count 用户代码的计算过程。经过了刚才的分析,对于 Spark 进程模型、Driver 与 Executors 之间的关联与联系,想必你就有了更清晰的理解和把握。
# 7. 分布式环境搭建
后续待使用虚拟机进行搭建
# 8. Driver组件
分布式计算的精髓,在于如何把抽象的计算图,转化为实实在在的分布式计算任务,然后以并行计算的方式交付执行
Driver中的核心组件: