
 kafka之缓冲区
kafka之缓冲区
# 没有缓冲区的缺点
在没有缓冲区之前,生产者生产一条消息,就向broker发送一条消息,在数据量较小的情况下,看起来没有什么缺点,但是当数据量非常大时,每条信息都要进行一次网络io,这是非常消耗性能的。所以kafka相当将这些数据先缓存起来,当达到一定的量时,在以batch的方式发送出去。
每次数据发送出去,确认发生成功后,相应的数据就应该被垃圾回收,但是当数据量非常大了后,频繁地进行垃圾回收,非常影响用户线程的性能。
- 频繁的网络请求:如果没有缓冲区,每次发送消息都需要立即向 Kafka 服务器发送请求。这可能会导致频繁的网络请求,降低了整个系统的性能。
- 性能下降:如果没有缓冲区,生产者必须等待每个消息被写入 Kafka 服务器之后,才能继续发送下一个消息。这样可能会导致生产者的性能下降。
- 数据丢失:如果生产者发生错误或崩溃,那么它所发送的消息将会丢失。如果有缓冲区,则可以在生产者重新启动后重新发送未发送成功的消息。
- 资源浪费:如果没有缓冲区,生产者可能会不断发送大量的小数据包,这会浪费网络带宽和服务器资源。
# 加上缓冲区的优点
- 提高性能:生产者将消息写入缓冲区,而不是立即发送到 Kafka 服务器。这意味着生产者可以更有效地利用网络 I/O 和处理资源,提高整体系统性能。
- 减少网络流量:通过使用缓冲区,生产者可以批量发送多个消息,从而减少了网络流量。这降低了网络拥塞和带宽问题的风险。
- 提高可靠性:缓冲区可以存储未发送的消息,因此即使在发生一些故障的情况下,也可以保证消息不会丢失。如果某些消息发送失败,生产者会尝试重新发送它们,以确保所有消息都被正确处理。
- 提高吞吐量:通过缓冲区,生产者可以批量发送多个消息。这将极大地增加 Kafka 生产者的吞吐量,从而提高整个 Kafka 系统的性能。
- 提高灵活性:使用缓冲区还允许生产者控制消息发送的速率。生产者可以根据需要调整缓冲区大小、发送批处理大小等参数,以满足特定的需求。
# 缓冲区在整体流程中的位置
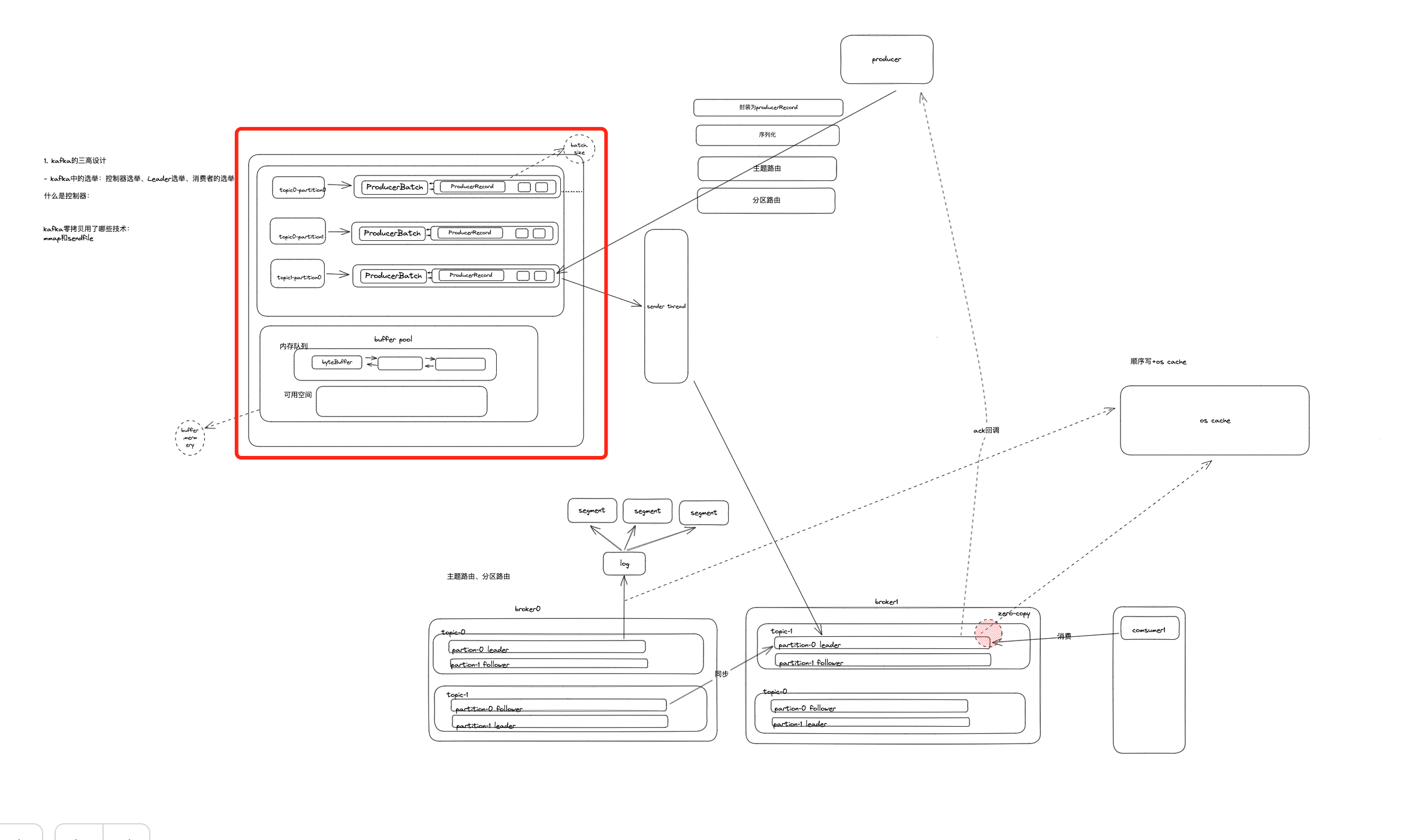
如果所示,生产者发送信息时,经历消息封装、序列化、分区器路由后,就会进入缓冲区进行累计缓冲。
# 缓冲区设计 结合源码
RecordAccumulator整体设计
# 成员变量
public final class RecordAccumulator {
private final Logger log;
private volatile boolean closed;
private final AtomicInteger flushesInProgress;
private final AtomicInteger appendsInProgress;
private final int batchSize;
private final CompressionType compression;
private final int lingerMs;
private final long retryBackoffMs;
private final int deliveryTimeoutMs;
private final BufferPool free;
private final Time time;
private final ApiVersions apiVersions;
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
private final IncompleteBatches incomplete;
private final Set<TopicPartition> muted;
private int drainIndex;
private final TransactionManager transactionManager;
private long nextBatchExpiryTimeMs = Long.MAX_VALUE; // the earliest time (absolute) a batch will expire.
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
①重点1 :batches
batches是一个CopyOnWriteMap类型的map,通过ConcurrentMap<TopicPartition, Deque<ProducerBatch>>可以得知java堆中存在一个map,其中key为主题分区,value是对应的producerBatch队列,当producer发送消息时,就会根据producerRecord对应的主题分区找到对应的deque队列,并加到deque队列的尾部batch中。
疑问:为什么使用的是CopyOnWriteMap呢?
copyOnWrite即写时复制技术。
它内部的集合其实就是一个非线程安全的map,通过对这个map做一系列的包装按CopyOnWrite的思想实现了线程安全。
- 非线程安全的Map变量用volatile去修饰,保证了线程间的可见性,只要更新了map这个引用指向的对象地址那么别的线程可以立即看到。
- 读的时候完全不用加锁,因为读的是一个只读副本,写不会发生在只读副本上,这样读的性能就会非常高,N多线程不加锁读。
- 写的时候会多个线程调用加锁的putIfAbsent方法,这个方法保证了线程安全,同时所有的操作都用一个锁。如果有了这个元素存在就直接返回,不会再写入写的元素。
- 保证了KafkaProducer线程的总体线程安全。
②重点2:BufferPool
# 成员变量
public class BufferPool {
static final String WAIT_TIME_SENSOR_NAME = "bufferpool-wait-time";
private final long totalMemory;//默认大小32M
private final int poolableSize;//池化大小16k
private final ReentrantLock lock;
private final Deque<ByteBuffer> free; //池化内存
private final Deque<Condition> waiters;//阻塞线程对应的condition
private long nonPooledAvailableMemory;//非池化可使用的内存
private final Metrics metrics;
private final Time time;
private final Sensor waitTime;
private boolean closed;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Total available memory is the sum of nonPooledAvailableMemory and the number of byte buffers in free * poolableSize
bufferPool的总内存 = 所有池化的内存+未池化的内存
那么buffer pool中的内存是怎么进行申请和释放的呢?
这里的 size 即申请的内存大小,它等于 Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
//1.验证申请的内存是否大于总内存
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
ByteBuffer buffer = null;
//2.加锁,保证线程安全。
this.lock.lock();
if (this.closed) {
this.lock.unlock();
throw new KafkaException("Producer closed while allocating memory");
}
try {
//3.申请内存的大小是否是池化的内存大小,16k
if (size == poolableSize && !this.free.isEmpty())
//如果是就从池里Bytebuffer
return this.free.pollFirst();
// 池化内存空间的大小
int freeListSize = freeSize() * this.poolableSize;
//4.如果非池化空间加池化内存空间大于等于要申请的空间
if (this.nonPooledAvailableMemory + freeListSize >= size) {
// 如果申请的空间大小小于池化的大小,就从free队列里拿出一个池化的大小的Bytebuffer加到nonPooledAvailableMemory中
// 5.如果一个池化的大小的Bytebuffer不满足size,就持续释放池化内存Bytebuffer直到满足为止。
freeUp(size);
this.nonPooledAvailableMemory -= size;
//如果非池化可以空间加池化内存空间小于要申请的空间
} else {
int accumulated = 0;
//创建对应的Condition
Condition moreMemory = this.lock.newCondition();
try {
//线程最长阻塞时间
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
//放入waiters集合中
this.waiters.addLast(moreMemory);
// 没有足够的空间就一直循环
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
//空间不够就阻塞,并设置超时时间。
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
recordWaitTime(timeNs);
}
if (this.closed)
throw new KafkaException("Producer closed while allocating memory");
if (waitingTimeElapsed) {
this.metrics.sensor("buffer-exhausted-records").record();
throw new BufferExhaustedException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
remainingTimeToBlockNs -= timeNs;
// 当申请的空间的是池化大小且ByteBuffer池化集合里有元素
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
buffer = this.free.pollFirst();
accumulated = size;
} else {
//尝试给nonPooledAvailableMemory扩容
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -= got;
//累计分配了多少空间
accumulated += got;
}
}
accumulated = 0;
} finally {
this.nonPooledAvailableMemory += accumulated;//把已经分配的内存还回nonPooledAvailableMemory
this.waiters.remove(moreMemory);//删除对应的condition
}
}
} finally {
try {
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
lock.unlock();
}
}
if (buffer == null)
// 返回非池化ByteBuffer分配内存
return safeAllocateByteBuffer(size);
else
// 返回池化的ByteBuffer分配内存
return buffer;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
// 释放的空间是否是池化大小,如果是,free上加一个ByteBuffer对象
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
// 否则增加非池化空间大小
this.nonPooledAvailableMemory += size;
}
// 释放第一个wait();
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 缓冲区设计举一反三
参考:https://juejin.cn/post/7109099213111164942#heading-2 (opens new window)