
 数据库迁移设计
数据库迁移设计
# 背景
在公司大部分数据库都需要从mongodb迁移到mysql的前提下。现在对某些数据库中的表进行数据迁移。
# 确定要迁移的数据库的数据涉及到的服务有哪些?
首先即要确定我们修改代码的范围,如果所有关于数据库的数据的流量全部来自于同一个服务,那就没有问题,如果数据库的数据访问层可能来自于多个服务,那么问题可能会更复杂一些。以下是关于mongodb数据访问全部来自于一个account服务的解决方案。
# 确定迁移原因
- mongodb在数据量大的情况下,效率较慢。
- mongodb维护人员较少,当mongodb发生故障时,很难维护
# 确定迁移预期目标
- mongodb数据全量迁移至mysql数据库
- 迁移过程中不停机,对用户无感
- 迁移过程中出现问题可以进行降级或回滚。
# 确定方式
①首先需要考虑mongodb和mysql在数据结构上面的差异,mongodb中的数据结构和mysql差距很多,mongodb中可能会有JSON的格式,需要考虑迁移到mysql中对应的数据结构该怎么设计、索引应该怎么创建。
②考虑中途不宕机,怎实现呢?
思考:该目标是不是可以抽象为两个服务节点之间的数据传输,之前我们学习学习当中的节点间的大量数据传输有哪些呢?比如说redis、mysql,他们在集群下总是会有主副本的区分,主节点要将数据传输到副节点,是不是都实现过一套传输的方案,其方案基本上都是将数据的传输分为存量数据和增量数据的传递。首先我们要确定存量数据如何传输,在存量数据的传递过程中,我们也要进行增量数据的传输,在mysql和redis中,基本的实现方案都是在生成存量传输数据的过程中,接受客户端的请求,然后将增量数据写在一个缓存中,当存量数据传输完成,再将缓存中的数据进行传输。
上面的思考,其实就是在不宕机的情况下,完成数据的传输,其重点就是将数据分为存量数据和增量数据,这时关键,对于存量数据和增量数据如何进行传输,我们可以根据业务具体来实现。
存量数据:在数据开始迁移的那一刻,原数据库所拥有的数据。
增量数据:在数据开始迁移的那一刻,原数据库因为接受到请求新增的数据。
③如何保证出错了过后可以降级?
数据库迁移过程中,想要保证出错可以降级,其本质就是保证mongodb的数据业务上不丢失,与mongodb相关的代码不修改。所以这并不是说在代码版本上的降级,我们应该尽全力保证在数据迁移期间,mongodb的服务(增量数据)依然在进行当中。
如何实现呢?我们可以引入数据双写和开关的概念。
数据双写:在迁移过程中,mysql和mongodb都在进行数据的写,这样就算需要降级,mongodb的数据依然存在
开关:如果客户端发送过来读请求,为了保证的数据的一致性,我们必须保证业务只从一个数据库当中读。那么我们数据迁移过程中,读哪一个呢?
只读mysql:有些数据还在mongodb呢,可能因为读不到而出现错误,所以不能使用mysql
只读mongodb:mongo写同时进行着,那么读肯定是没有问题的。
所以在迁移过程中,我们可以只读mongodb,但是我们不能总读mongodb吧,因为我们的目标就是将mongodb下线,后面总是要将读流量切换到mysql的,而且还要保证不宕机。
这样就引入了开关的概念。
为了我们可以在迁移后平滑地将流量从mongodb切换到mysql,我们在项目中引入开关的概念。并配置在apollo中,通过修改apollo中的开关,动态修改在代码中的实现。
mongodb写开关:为true时,表示开启对mongdb的写
mysql写开关:为true时,表示开启对mysql的写
读开关:为true时,表示开启对mongodb读,否则对mysql读(mongodb读和mysql读是互斥的,所以这里只需要设置这一个互斥开关就可以了)
# 通过上面的方式的思考,我们就可以形成一个大致的实现方案
对于存量的数据,我们直接迁移(使用公司内部的工具:可以将mongodb对应的字段与目标表对应的字段设置相关的映射关系,然后进行数据的迁移)
对于增量数据,采用双写模式写到mysql。
①根据mongodb建立相应的mysql表结构,根据mongodb中repository层编写mysql repository层相关的代码。
②双写上线(读mongo,写mongo、mysql)
③开启dts存量同步(中途开始显现出bug,需要修改)
④存量同步完成后,逐步将读流量切换到Mysql,验证mysql业务逻辑是否有错(bug高峰期)
⑤读流量全量迁移到MySQL并验证完毕后,停止写MongoDB,迁移完成
| 上线阶段 | 数据库读写状态 | 流程 | |
|---|---|---|---|
| MongoDB | MySQL | ||
| 一 | 读/写 | 写 | 双写上线,DTS同步存量数据 |
| 二 | 写 | 读/写 | 读流量迁移至MySQL |
| 三 | 读/写 | 停写MongoDB |
# 细节思考
# 先考虑双写的具体实现
读:读我们的第一阶段都是先读mongodb,所以这一点都是毋庸置疑的。
增:增加,表示两个数据库都不存在该数据,所以新增是没有问题的,当做增量数据进行处理。
删:当要删除的数据未同步到mysql中时,mongodb中的数据可以成功删除,mysql因为数据不存在,执行了后语义正确,且后续不会出现该数据;当要删除的数据已经同步到mysql中时,mongodb中的数据可以删除,mysql中的数据也可以删除成功,语义正确
**改:**当要更改的数据(想不清楚了?)
工具思考:应该保证什么功能
# 数据量思考
在进行数据的迁移时,我们必须考虑数据量的大小,是否需要进行分表。因为每个数据库系统,一张表存储的数据量可能不一样,所以我们需要考虑是否要进行分表,如果要进行分表,由要怎么来使用方案,都是要考虑的方案。
# 开关具体实现思考
我们的重点就是在不宕机的请况下,切换开关。首先我们现在已知的是有3种开关。
读切换开关、mongodb写开关、mysql写开关。
既然要实现机器不宕机,我们就需要对开关实现动态开关。所以我们要借助注册中心,实现对配置文件的动态修改。因为公司对于配置中心使用的也是apollo,所以我们配置中心使用apollo其实也是听不懂的,这样我们在apollo上修改了配置就可以在java代码中及时得到更新。那么我们在springboot中怎么读取这个配置呢?
@Value("${mongo2mysqlMigration.reader.mongo}")
private Boolean mongoReaderEnabled;
@Value("${mongo2mysqlMigration.writer.mysql}")
private Boolean mysqlWriterEnabled;
@Value("${mongo2mysqlMigration.writer.mongo}")
private Boolean mongoWriterEnabled;
2
3
4
5
6
7
8
如图所示,我们使用@Value注解读取yaml文件,当apollo重新更新了配置过后,这里就可以将对应的数据重新注入到成员变量中。
至于@Value注解的原理,可以看看这篇文章https://blog.csdn.net/qq_29717181/article/details/99872792
在代码中,我们就根据开关用if else来对流量进行切换。
# 平滑卸掉mongodb思考
未迁移前我们的代码处于以下这个层次
service层依赖于repository层
service层主要是一些复杂的业务,而repository层主要是直接与数据库交互的层。我们的目的是并不想修改service层的东西,做到对servcie无感。
虽然这个时候就会疑惑了
service中的依赖注解(@Resource(name="UserRepositoryImpl")) 在切换的时候我们不修改这个么?
其实确实不用,我们把mysql的repository 名字改成UserRepositoryImpl,mongodb 的Repository改成其他的就可以了。
这样就可以做到对service层无感知。
这个时候问题又来了,我们有了mysql的repository和mongodb的repository,这个时候怎么做流量的转发呢?这个时候我们要引入另外一个代理层proxy,专门来做我们的代理转发的业务,根据开关配置的真与否来进行流量的分发操作,这个时候我们的框架其实就基本出来了。
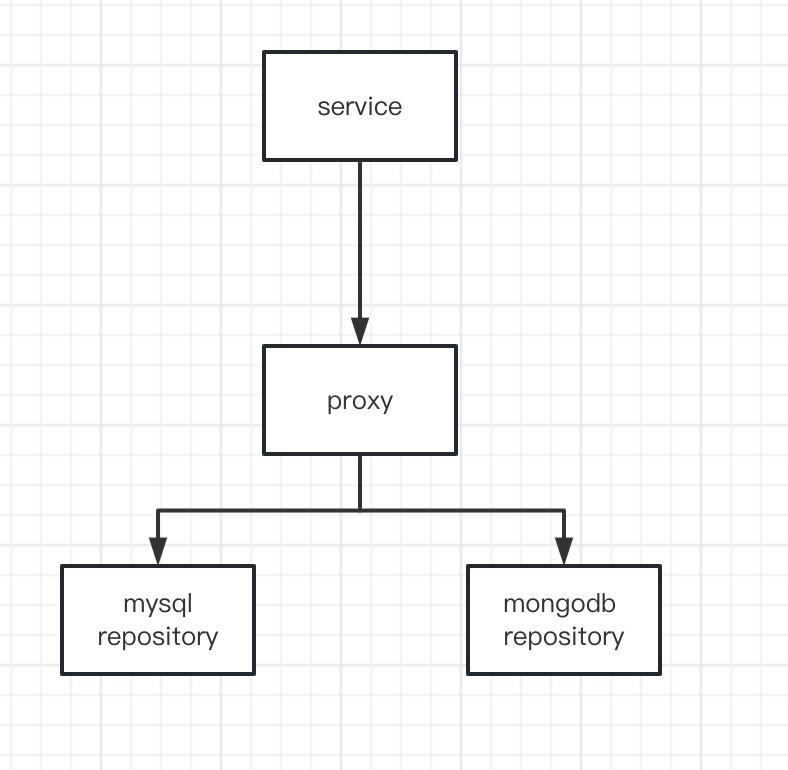
这时,我们只需要将相关的数据层依赖换为proxy,而proxy又依赖mysql和mongodb就可以实现流量的分发。
以下使我们的各个组件的名字,可以做到对service无感。
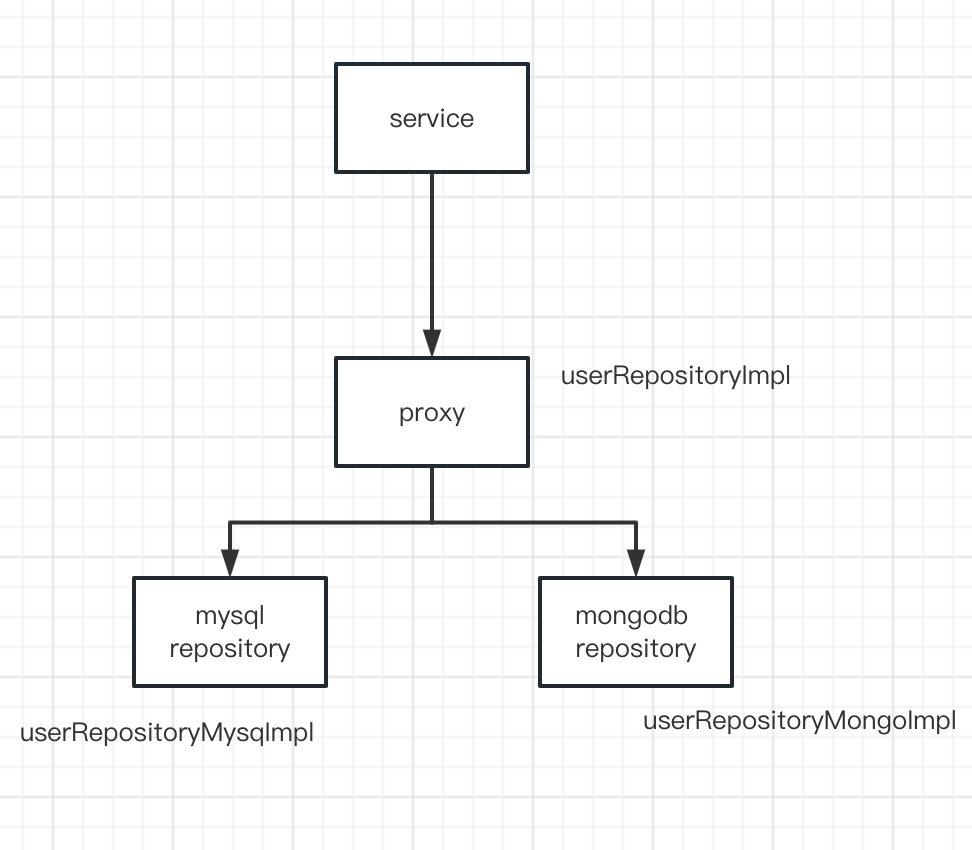
在proxy中根据开关的真假,就可以完成流量的切换了。
# 关注读写界限思考
mongodb中一些userRepository可能只是纯粹的读或者写,这种对我们是非常友好的,开关切换时就直接切换就好。但是在方法中可能有些不纯粹的操作,比如一个方法中可能既有查询方法,又有修改方法,就感觉向一个service业务方法似得,这种就需要我们手动在proxy中进行拆解,将其中的写方法和读方法正确的进行拆分,这样才不会出错(对于一个不纯粹的方法,如果我们将其定义写操作,那么当我们开启mysql的读时,会执行该方法,那么其中的读mysql操作也会同时执行,这是不符合我们含义的。所以这里我们要划分好读写的界限,要让方法更加纯粹)