
 索引失效的情况
索引失效的情况
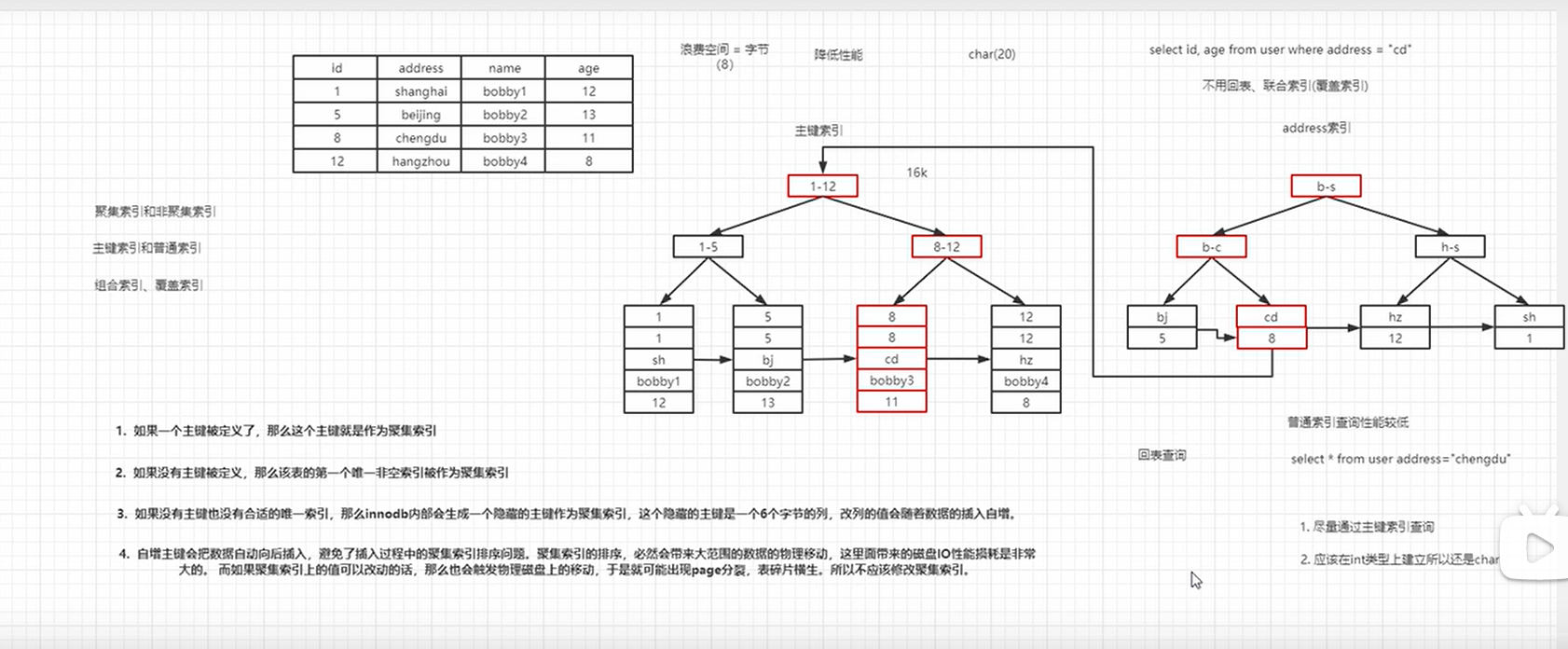
#
# 1.记住一些典型场景
- 违背最左前缀原则
like ’bob%‘可以使用索引like ’%bob‘ 、like ’%bob%‘不能走索引 (%后面的无序)- where条件中使用了函数运算:
select * from salaries where ABS(salary)<40000 - in不会造成索引失效 ,not in会造成索引失效
- or不会走索引
- 使用null和is not null不一定走索引
# 2. 失效的背后原理
关键作用是在优化器上
优化器主要有两个作用
# ①重写sql语句
这就意味着我们写的sql语句可能不是我们最开始写的sql。
会进行哪些重写呢?
移除不必要的括号、常量传递、等值传递、移除没用的条件


# ②根据成本分析,生成执行计划
要不要走索引或全表扫描
使用什么索引等
mysql成本分析有两个关键因素需要考虑:
io成本:从磁盘加载内存过程中所消耗的时间成本
cpu成本:读取记录及检查记录是否满足对应的搜索条件、对结果进行排序等这些操作所消耗的时间成为cpu成本。
# 3. 基于成本的优化
在真正执行一条单表查询语句之前,My8QL的优化器会找出所有可以用来执行该语句的方案,并在对比这些方案之后找出成本最低的方案.这个成本最低的方案就是所谓的执行计划.之后才会调用存储引擎提供的接口真正地执行查询.这个过程总结一下就是下面这样.
- 根据搜索条件,找出所有可能使用的索引.
- 计算全表扫描的代价。
- 计算使用不同索引执行查询的代价.
- 对比各种执行方案的代价,找出成本最低的那个方案.
实际使用过程中,=、in、not in、> 会影响成本的计算
# 4.成本计算实例
首先给出以下表:
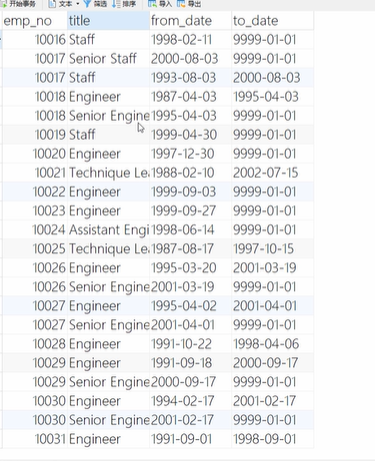
title上建立的二级索引、emp_no是二级索引、date没有索引
假设我们我们使用sql语句select * from employ where emp_no>10016 and emp_no <10116
此时就有两种执行方法:走全表扫描还是走emp_no二级索引
- 全表扫描的代价
mysql默认的页是16k,mysql一次性读数据是读一页
show table status like 'titles'可以展示一个表中相关的数据

rows 表中有多少行数据442486
data_length 聚簇索引叶子节点总长度20512768
计算成本必须定义好一次io和cpu计算的成本比是多少
在mysql中,我们假设(其实每个mysql版本都不同):一次io的成本是1.0 (将数据从磁盘加载到内存) 一次cpu的成本 0.2(将在内存中的数据拿出来进行对比消耗的cpu成本)每个mysql版本不一定相等
该表的聚簇索引叶子节点共有:20512768/1024/16=1252个页
全表扫描:
io成本:1252*1.0=1252 (加载叶子节点的每个页)
cpu成本:记录行数442486*0.2=88498 (在内存中的数据需要通过对比每条数据来看是否符合查询条件)
总成本:1252+88498=89749
走idx_emp_no索引
使用二级索引时,注意是否有回表
总成本=二级索引查询成本+回表查询成本
二级查询:1.0 (二级索引查找成本很低,很快,可以看做是1.0)
回表的成本:回表时查询一个数据也很快,也可以看做是1.0。但是注意,回表的数据集中不是按照索引排好序的,所以需要根据数据集中的每一条数据去回表查询,索引影响成本的因素是回表的数量。
- mysql如何在没有真正执行sql就知道有多少条数据呢?其实mysql是根据索引来评估大概有多少条的,不是真正准确的记录。

页1可以根据其父节点知晓1到2之间有多少页
页3可以通过父节点知晓节点3之前有多少数据,这样就
可以估算出页1到页3之间有多少条数据,然后mysql
就可以根据页数估算出共有多少条数据行,从而判断出
页1到页3范围有多少数据
2
3
4
5
假如说根据二级索引查询出的数据有100条:
io成本:100*1.0+1.0(表示 100条数据回表查询成本+二级索引查询成本)=101
cpu成本:100*0.2(二级索引成本)+100*0.2(回表索引成本)=40
总成本:101+40=141
假如有10000条数据呢,就可能走全表扫描(不在男女上建立索引的原因:二级索引返回的数据集过大,导致回表所产生的成本过大,导致索引失效)
可以通过optimizer trace看具体的mysql计算成本
可参考文章:
https://blog.csdn.net/weixin_42437633/article/details/122016723