
 redis内存淘汰策略
redis内存淘汰策略
# 了解一些命令
INFO memory 查看当前的redis服务的内存占用情况
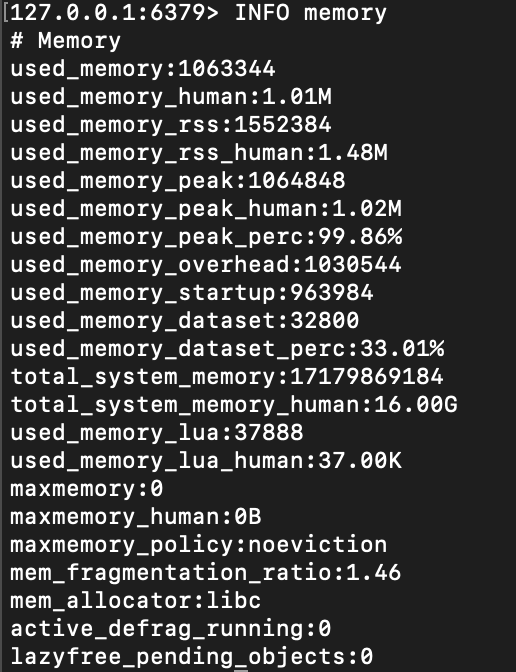
used_memory:表示Redis服务器当前使用的内存总量(以字节为单位)。used_memory_human:与used_memory相同的信息,但以人类可读的格式显示,例如使用MB或GB表示。used_memory_rss:表示Redis进程在操作系统中的常驻集大小(Resident Set Size),表示Redis使用的物理内存总量。used_memory_peak:表示Redis服务器历史上分配的最大内存峰值(以字节为单位)。used_memory_peak_human:与used_memory_peak相同的信息,但以人类可读的格式显示。used_memory_lua:表示Lua引擎使用的内存量(以字节为单位)。mem_fragmentation_ratio:表示Redis内存碎片的比率,即内存分配和释放的比率。total_system_memory:表示Redis运行所在系统的总内存大小(以字节为单位)。maxmemory:表示Redis服务器配置的最大可用内存大小。maxmemory_human:与maxmemory相同的信息,但以人类可读的格式显示。maxmemory_policy:表示Redis服务器配置的淘汰策略。evicted_keys:表示自Redis服务器启动以来因为内存不足而被驱逐的键的数量。
# 淘汰策略前提
我们看到我们启动后maxmemory显示为0,是什么意思呢?
如果在Redis中使用 INFO memory 命令后,maxmemory 字段的值显示为 0,表示你的Redis服务器当前未配置最大可用内存限制。
当 maxmemory 的值为 0 时,Redis将不会执行任何内存淘汰策略,而是允许数据无限增长,直到服务器的物理内存用尽。这意味着Redis将不会主动删除任何数据,而是将数据持续保存在内存中。
如果你希望配置最大可用内存限制,你可以通过修改Redis服务器的配置文件(通常是redis.conf)或者在启动Redis服务器时指定 maxmemory 参数来设置最大内存值。例如,可以使用以下方式启动Redis并设置最大内存为 1GB:
redis-server --maxmemory 1gb
请注意,为了使 maxmemory 配置生效,你需要重新启动Redis服务器。
所以想要进一步实现淘汰策略,我们需要将maxmemory进行配置。
注意:要启动缓存策略,必须设置maxmemory,否则redis可以占用无限大内存,从而无法触发缓存策略。
让我们在redis.conf中设置对应的maxmemory

因为是我们在本地进行测试,我们设置为1300k吧。(其实是建议设置的更小的,因为当我们要测试LRU算法的时候,在海量数据中去看哪些数据丢失其实比较麻烦,这里我们可以把最大的maxmemory弄的更小,比如100B)
设置成功后重启redis即可。
bin/redis-server redis.conf
成功后,我们再看看内存信息:
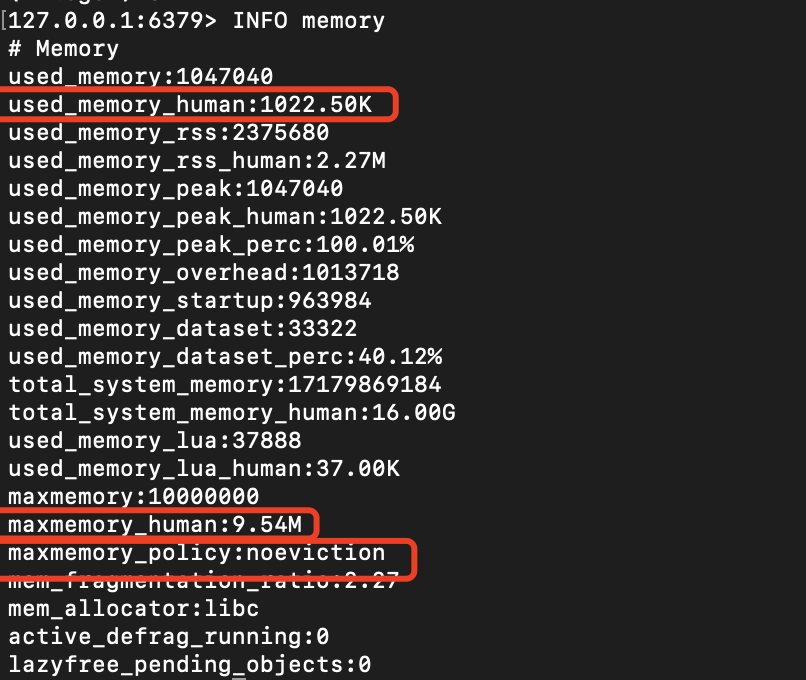
可以看到我们的最大内存已经设置成功了。而且在没有配置的情况下,默认的淘汰策略是noeviction
noeviction(不淘汰策略):当内存不足以容纳新写入的数据时,Redis会直接返回错误,并拒绝写入操作。
# 我们怎么知道一个key占用了多少的内存大小?
可以使用命令查看key对应的键值对占用了多大的内存
MEMORY USAGE keyName
# 快速构建一个springboot程序使用组件快速让redis达到最大值
因为我们后面还需要测试其他的淘汰策略,所以我们需要统一一下key的规范,以便后续可以快速分析一个key是否被淘汰
写入时间-是否设置过期 : 上次使用时间 需要保证时间在毫秒级别
0518-15-24-234 : 0518-15-24-234
参考github
思路是将不同的key set到redis中,当对应的数据占用内存达到maxmemory时,

此时,如果我们继续向redis set key,那么就是抛出异常:

使用 redisTemplate 也会抛出对相同的异常
Error in execution; nested exception is io.lettuce.core.RedisCommandExecutionException: OOM command not allowed when used memory > 'maxmemory'.
# 如果我们需要更改策略怎么办
同样的需要子配置文件中更改对应的配置,然后重启redis服务。(再此之间,我们可以把我们上面测试写入redis的数据给清除掉aof、rdb。)
- 修改配置文件:
- 删除落盘文件。
rm -rf dump.rdb
再次启动后,再次看内存相关的信息:
127.0.0.1:6379> INFO memory
# Memory
used_memory:1046912
used_memory_human:1022.38K
used_memory_rss:2453504
used_memory_rss_human:2.34M
used_memory_peak:1046912
used_memory_peak_human:1022.38K
used_memory_peak_perc:100.01%
used_memory_overhead:1013630
used_memory_startup:964000
used_memory_dataset:33282
used_memory_dataset_perc:40.14%
total_system_memory:17179869184
total_system_memory_human:16.00G
used_memory_lua:37888
used_memory_lua_human:37.00K
maxmemory:1500000
maxmemory_human:1.43M
maxmemory_policy:allkeys-lru
mem_fragmentation_ratio:2.34
mem_allocator:libc
active_defrag_running:0
lazyfree_pending_objects:0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
怎么来验证这个算法呢?
我们可以将key设置为 allKeys-lru:num
- 从0开始一直向上加,当内存满时,可以看看0是否还存在,不存在,则表示成功
- 从0开始一直向上加,内存没满时,获取一次0,后待内存满时,0不会被删除,但是1会被删除。
做的过程中遇到了什么问题:
- 数据量太大,导致插入redis的数据太多,不好分析数据
尽量调小maxmemory,使之在向redis加入较少数据就可以出发淘汰策略。
- redisTemplate怎么获取相关的内存信息?
Properties properties = (Properties)redisTemplate.execute((RedisCallback<Object>) connection -> connection.info());
long maxMemory = properties.getProperty("maxmemory") == null ? 0 : Long.parseLong(properties.getProperty("maxmemory"));
long usedMemory = properties.getProperty("used_memory") == null ? 0 : Long.parseLong(properties.getProperty("used_memory"));
2
3
- 我插入数据0-2000数据时,触发淘汰策略,此时我再插入100条数据,按理说0-100的数据将会被淘汰,但是实际上并没有,发现0-2000数据中随机有很多数据被淘汰,这么看来并不符合lru算法呀?
配置中有一个配置maxmemory samples配置:

可以看出redis做出了这种优化。那么试想一下,如果我们把这个配置调成10000,那么我们前面的猜想0-100数据淘汰可以吗?经测试,是这样的,0-100的数据因lru算法被成功淘汰,因为根据配置随机选择了10000的数据进行了淘汰算法。
- redis lru底层算法是怎么样的
https://www.bilibili.com/video/BV1LA4y1R7bT/?spm_id_from=333.337.search-card.all.click
- 手写一个lru算法
继续来测试一下volatile-lru算法:
volatile-lru:只对设定了过期时间的键进行淘汰,按照 LRU 算法进行淘汰。
测试思路:
- 所有的数据不包含ttl数据,那么怎么淘汰?0-2000全部是非ttl数据,测试怎么进行淘汰,是进行异常抛出?

可以看出,如果已经没有ttl的key,此时发生淘汰,是会直接抛出异常的。
- 设定0-2000的数据,其中10-100是ttl数据,且10-30是经常使用的数据,当我们触发了淘汰策略,应该淘汰的策略应该是31-100的数据
其实经测试,确实是ttl的数据进行了淘汰,但是因为可能淘汰的数量过多,我们10-30经常使用的数据在31-100的数据淘汰完之后,也会对10-30的数据进行淘汰。
至此,上面说的lru的数据就已经讲解完了。
下面我们来看看lfu算法
https://www.bilibili.com/video/BV1HB4y1S7xj/?spm_id_from=333.337.search-card.all.click
LRU(Least Recently Used)和LFU(Least Frequently Used)都是用于缓存淘汰策略的算法,它们的主要区别在于如何定义和计算“最近使用”和“频率”。
LRU算法将最近使用的数据放到链表尾部,最久未使用的数据放到链表头部。当缓存满时,优先淘汰链表头部的数据。这样可以保证最近访问的数据能够被频繁地使用,缓存命中率高。
LFU算法则是根据数据被访问的频率来进行淘汰。每个数据块都有一个计数器来记录被使用的次数,当缓存满时,淘汰计数器值最小的数据块。这样可以保证经常访问的数据能够被保留在缓存中,缓存命中率也会更高。
因此,LRU算法适合处理“热点数据”,即被频繁访问的数据,而LFU算法则适合处理“冷门数据”,即不太频繁访问的数据。
了解了上面的两大算法后,有机会可以自己实现一下:
https://leetcode.cn/problems/lru-cache/
https://leetcode.cn/problems/lfu-cache/
TODO: lfu的算法待最后进行实现
random算法
allkeys-random 和 volatile-random:从所有/过期键中随机选择进行淘汰。
为了更好的查看随机性,我们需要把我们把maxmemory调小一些,之前我们使用的大小是1100K,现在我们使用1030k吧(为什么要调小些?因为之前1100K可以插入2000多条数据,现在我们想看随机性,其实最好插入100多条数据时比较理想的)
对于allkeys-random,经过测试后,确实是在所有的数据当中随机选出key进行淘汰。
如何测试volatile-random呢?
例如我们插入 1 - 100条数据,我们设置过期数据在 10-20之间,那么后期10-20的数据将会被淘汰掉,且会抛出异常。
经过测试,当无限地向redis中插入数据,那么所有的ttl数据key将会被删除,剩下的全都是非过期的数据,这个时候再次插入数据的时候就会抛出异常

怎么测 volatile-ttl
插入1000条可过期数据,过期时间每隔5条设置过期时间为10min,其他过期时间设置为10000min。结果触发策略后,检查每隔5min的key是否被真正的删除了。
结果测试后符合预期,确实每间隔5min就会将其key给删除掉。