
 rocketMq简介
rocketMq简介
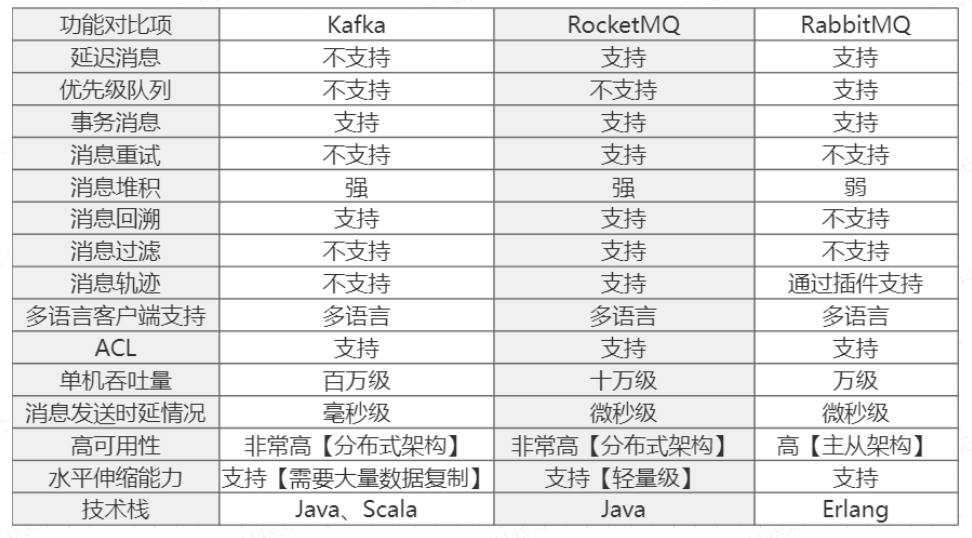
与kafka的不同点:
核心概念:Broker、NameServer、Producer、Consumer、MessageQueue、Topic
# 一.基本概念
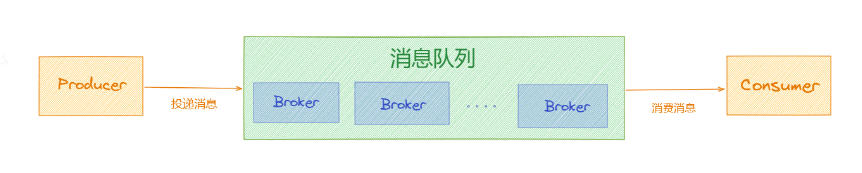
# Broker
「Broker」对于RocketMQ来说是「核心中的核心」,它负责接收「Producer」发送过来的消息,并持久化,同时它还负责处理「Consumer」的消费请求。
如果想要存储海量消息数据,那么「Producer」发送的消息会被「分散」的存储在这些「Broker」上,每台「Broker」机器上存储的消息内容都是不同的。将所有的「Broker」存储的消息全部加起来就是全部的数据,到这里,大家可能有个疑问?既然每台Broker存储的消息不同,那如果某台Broker 突然宕机了,那么这部分消息不就丢失了吗?还何谈高可用呢?
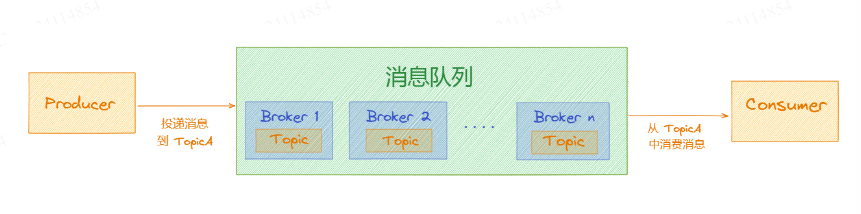
# topic
对于RocketMQ或者Kafka来说,「Topic」都是一个抽象概念,「Producer」在生产消息时候,会指定将消息投递到一个「Topic」,而「Consumer」消费消息的时候,也会指定一个「 Topic」进行消费,如下图所示:
# MessageQueue
我们知道在Kafka 中,为了实现「Topic」的扩展性,提高并发能力,内部是有个「Partition」的概念,那么对于RocketMQ来说,这里就是「MessageQueue」。 假如现在有「Topic A」,内部有3个「MessageQueue」,如下图所示:
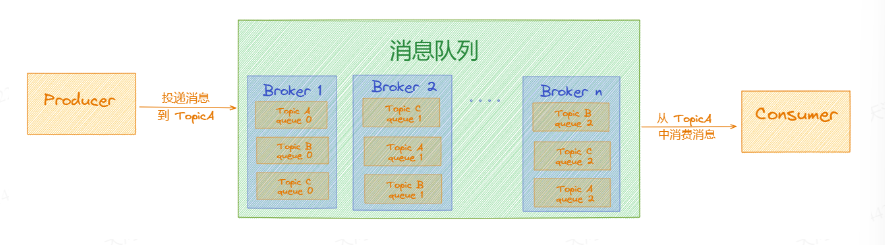
从上图得出,分散的「MessageQueue」一起组成一个完整的「Topic」。跟Topic一样,MessageQueue也是一个逻辑上的概念。但是最后消息还是要被持久化到Broker 所在机器的「磁盘」上的,这才是消息的最终归宿。 同一个「Topic」下的消息会分散存储在各个「Broker」上,这样有2个好处:「能够最大程度的进行数据容灾」、「能够防止数据倾斜问题」。 这就像俗话说的「鸡蛋不能放在一个篮子里」,数据被均衡的分散存储,出现数据倾斜问题的概率就降低了。 但是就算引入了「MessageQueue」,并对数据进行分散存储,如果Broker 2挂了后,数据还是会丢失的。 之前只会丢一个Topic的消息,而现在3个Topic的数据都丢失了,尴尬不?
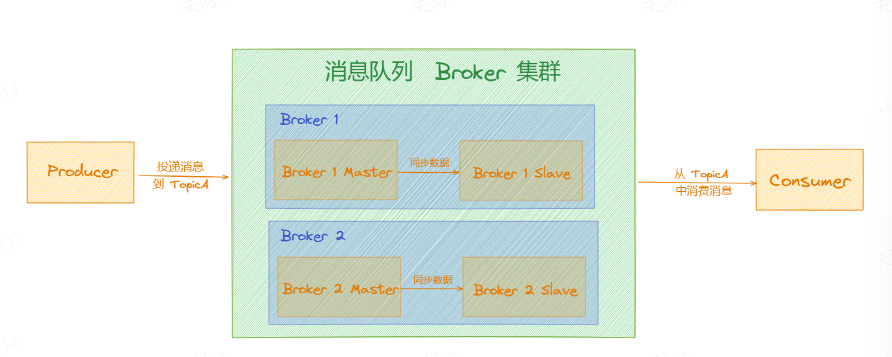
RocketMQ 4.5前
所以实际上在RocketMQ4.5版本之前提供了基于「主从架构」的高可用机制。即将Broker 分为「Master」 . 「Slave」 ,主从之间定期进行数据同步。
rocketMQ 4.5后:
而在RocketMQ 4.5之后提供了何用集群的实现「Dledger」 ,它会在集群发生故障时进行自动切换,不需要人工介入,会解决上面「主从架构」的缺陷,后面再讲它的实现原理。 我们再将视角切回来,虽然我们引入了「MessageQueue」 ,看似可以解决所有的问题, 但如果放到真实场景下来看,就会发现问题。 比如:有多台「Broker」 组成一个大集群对外提供服务,当「Producer」 建立连接发送数据时,应该选择往哪台[ Broker」.上发送数据呢?

看到上图是不是缺少类似「配置中心」这样一个组件,如果是配死在项目中的话,如果配置的这台Broker突然挂掉了或者在业务高峰期挂掉了,难道我们要去修改项目的配置文件重新发布吗?这明显不靠谱。
因此为了解决这个问题,我们还需要引入新的组件「NameServer」。
# NameServer
「NameServer」用于存储整个RocketMQ 集群的「元数据」,就像Kafka 会采用Zookeeper来存储、管理集群的元数据一样。 那么「NameServer」中存放的「元数据」都有哪些呢? 1.集群有哪些Topic。 2.这些Topic 的MessageQueue 分别在哪些Broker节点上。 3.集群中都有哪些活跃的 Broker节点。 那「NameServer」都是如何感知这些信息呢?这些信息不会凭空出现在「NameServer」中,而是注册进来的。
Broker在启动时会将自己注册到NameServer上,且通过心跳的方式持续地更新元数据。
Producer、Consumer都会和NameServer建立连接、进行交互来动态地获取集群中的数据,这样一来就知道自己该连接哪台Broker 了。 如下图所示:

这次看上去就比较完美了,「Broker」 . 「Producer」 . [Consumer」动态的将自己注册到|NameServer」 上,但是眼尖的同学就发现了这里「NameServer」还是个单点,既然说是RocktMQ集群的大脑,如果只有一个「NameServer」,挂掉了话,岂不是整个集群都无法正常工作了。 没错。所以实际的生产环境中,会部署多台NameServer组成一个集群对外提供服务,如下图所示:
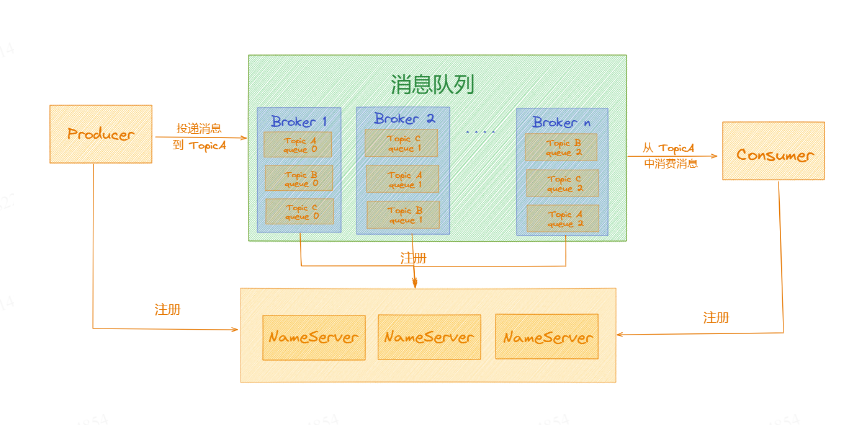
这里我们可以将「NameServer」理解成一个无状态的节点。 既然是要存储元数据,那么怎么还能是无状态呢?这是因为「Broker」会将自己注册到每一个「NameServer」 上,这样每个「NameServer」上都有完整完整的数据,所以我们可以将多个[NameServer」看成是一个无状态节点。所以这样的多实例部署保证了整个RocketMQ的高可用。