
 kafka个人技术分享
kafka个人技术分享
# kafka 生产者原理分享
# 一. 简介
# 1. 什么是kafka
Kafka是一种分布式的流处理平台,最初由LinkedIn开发。它被设计用来处理大规模的数据流,并具有高吞吐量、可靠性、可扩展性和容错性等特点。Kafka基于发布-订阅模型,通过将消息存储在一个或多个主题中,使得多个消费者可以同时从主题中读取消息并进行处理。Kafka还提供了一些高级功能,如支持消息的持久化、数据压缩和数据分区等。由于其高性能和可靠性,在现代数据架构中被广泛应用于消息队列、日志收集、流处理和事件驱动架构等方面。官网: Apache Kafka (opens new window)
# 2. kafka整体架构
● Broker
服务代理节点。其实就是一个kafka实例或服务节点,多个broker构成了kafka cluster。
● Producer
生产者。也就是写入消息的一方,将消息写入broker中。
● Consumer
消费者。也就是读取消息的一方,从broker中读取消息。
● Consumer Group
消费组。一个或多个消费者构成一个消费组,不同的消费组可以订阅同一个主题的消息且互不影响。
● ZooKeeper
kafka使用zookeeper来管理集群的元数据,以及控制器的选举等操作。
● Topic
主题。每一个消息都属于某个主题,kafka通过主题来划分消息,是一个逻辑上的分类。
● Partition
分区。同一个主题下的消息还可以继续分成多个分区,一个分区只属于一个主题。
● Replica
副本。一个分区可以有多个副本来提高容灾性。
● Leader and Follower
分区有了多个副本,那么就需要有同步方式。kafka使用一主多从进行消息同步,主副本提供读写的能力,而从副本不提供读写,仅仅作为主副本的备份。
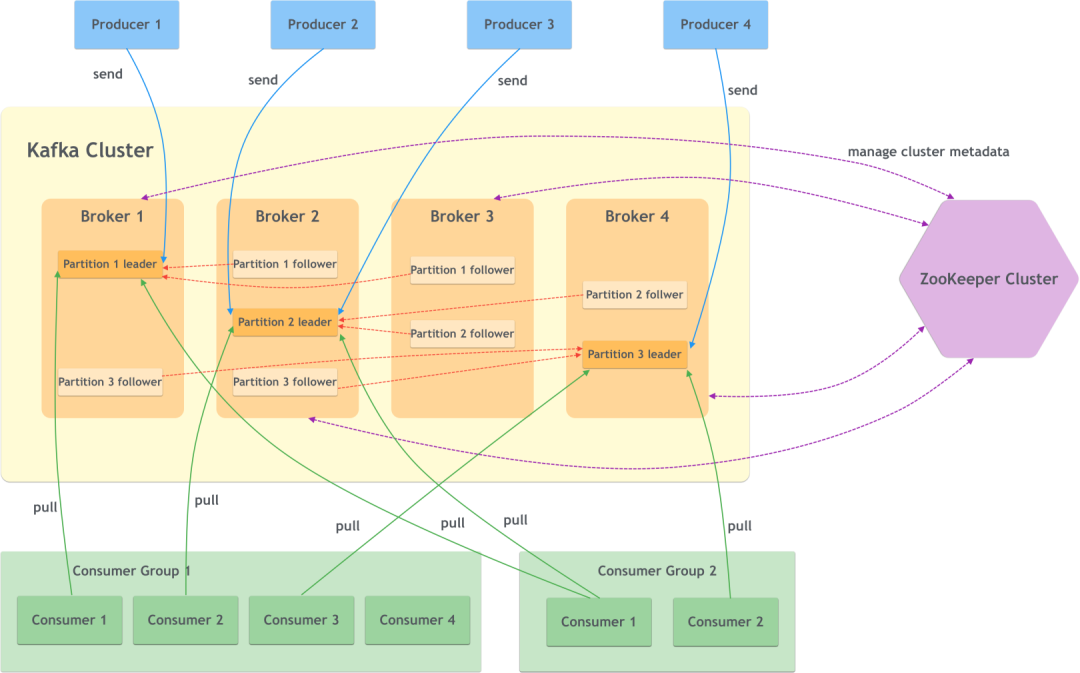
以下知识点讲解基于kafka 2.8.0
# 二. 消息发送流程
# 1. 一条消息发送过程中经历了什么
■ KafkaProducer创建一条消息
■ 生产者拦截器在消息发送之前做一些准备工作,比如过滤不符合要求的消息、修改消息的内容等
■ 序列化器将消息转换成字节数组的形式
■ 分区器计算该消息的目标分区,然后数据会存储在RecordAccumulator中
■ sender线程获取数据进行发送
■ 创建具体的请求
■ 如果请求过多,会将部分请求缓存起来
■ 将准备好的请求进行发送
■ 发送到kafka集群
■ 接收响应
■ 清理数据
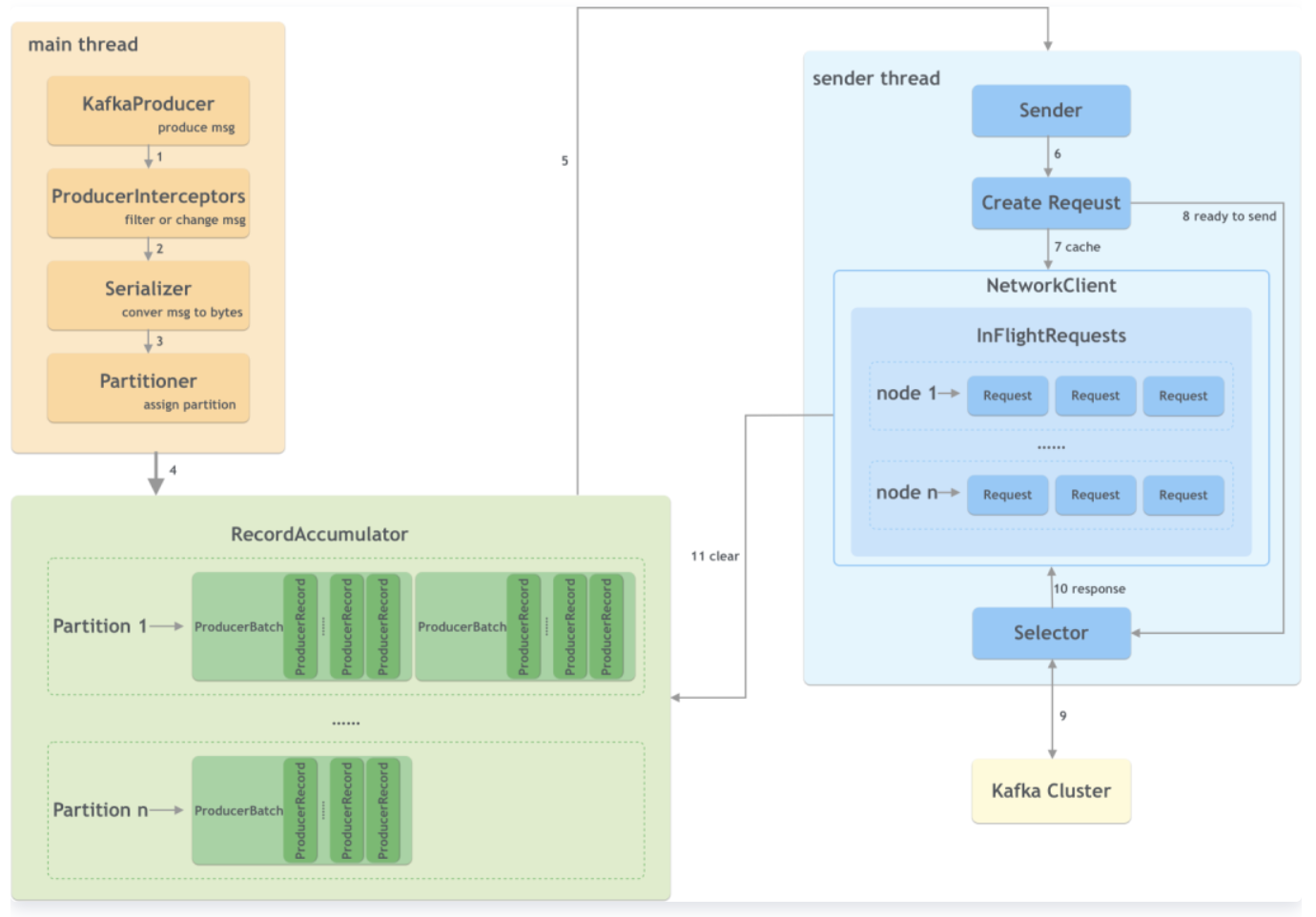
# 三. 生产者原理分析
# 1. 生产者初始化过程做了什么?
org.apache.kafka.clients.producer.KafkaProducer#KafkaProducer
1)、设置分区器(partitioner), 分区器是支持自定义的
2)、设置重试时间(retryBackoffMs)默认100ms
3)、设置序列化器(Serializer)
4)、设置拦截器(interceptors)
5)、初始化集群元数据(metadata),刚开始空的
6)、设置最大的消息为多大(maxRequestSize), 默认最大1M
7)、设置缓存大小(totalMemorySize) 默认是32M
8)、设置压缩格式(compressionType)
9)、初始化RecordAccumulator也就是缓冲区指定为32M
10)、定时更新(metadata.update)
11)、创建NetworkClient
12)、创建Sender线程
13)、KafkaThread将Sender设置为守护线程并启动
# 2. 主线程发送消息的过程中做了什么

# 重要组件
# ①partitioner 分区器
先看看kafka中的partitioner的接口是如何设计的。
org.apache.kafka.clients.producer.Partitioner
public interface Partitioner extends Configurable, Closeable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); //key可能为null
}
2
3
以为着消息发送到主题的哪个分区,可以由参数中的一个或者多个决定,返回int类型的分区下标。
kafka中实现的分区器有哪些?
● RoundRobinPartitioner 轮询分区器
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
让每个partition都有分配到消息的机会
● UniformStickyPartitioner 粘性分区器
org.apache.kafka.clients.producer.UniformStickyPartitioner
什么是粘性分区器?
首先,我们知道,Producer在发送消息的时候,会将消息放到一个ProducerBatch中, 这个Batch可能包含多条消息,然后再将Batch打包发送。这样做的好处就是能够提高吞吐量,减少发起请求的次数。但是有一个问题就是, 因为消息的发送要一个Batch满了或者linger.ms时间到了(当然具体的条件会更多),才会发送。如果生产的消息比较少的话,迟迟难以让Batch塞满,那么就意味着更高的延迟。
在之前的消息发送中,就将消息轮询到各个分区的,本来消息就少,还给所有分区遍历的分配,那么每个ProducerBatch都很难满足条件。粘性分区器的思路就是将一个ProducerBatch塞满之后,再对其他的分区进行分配。
如下图:
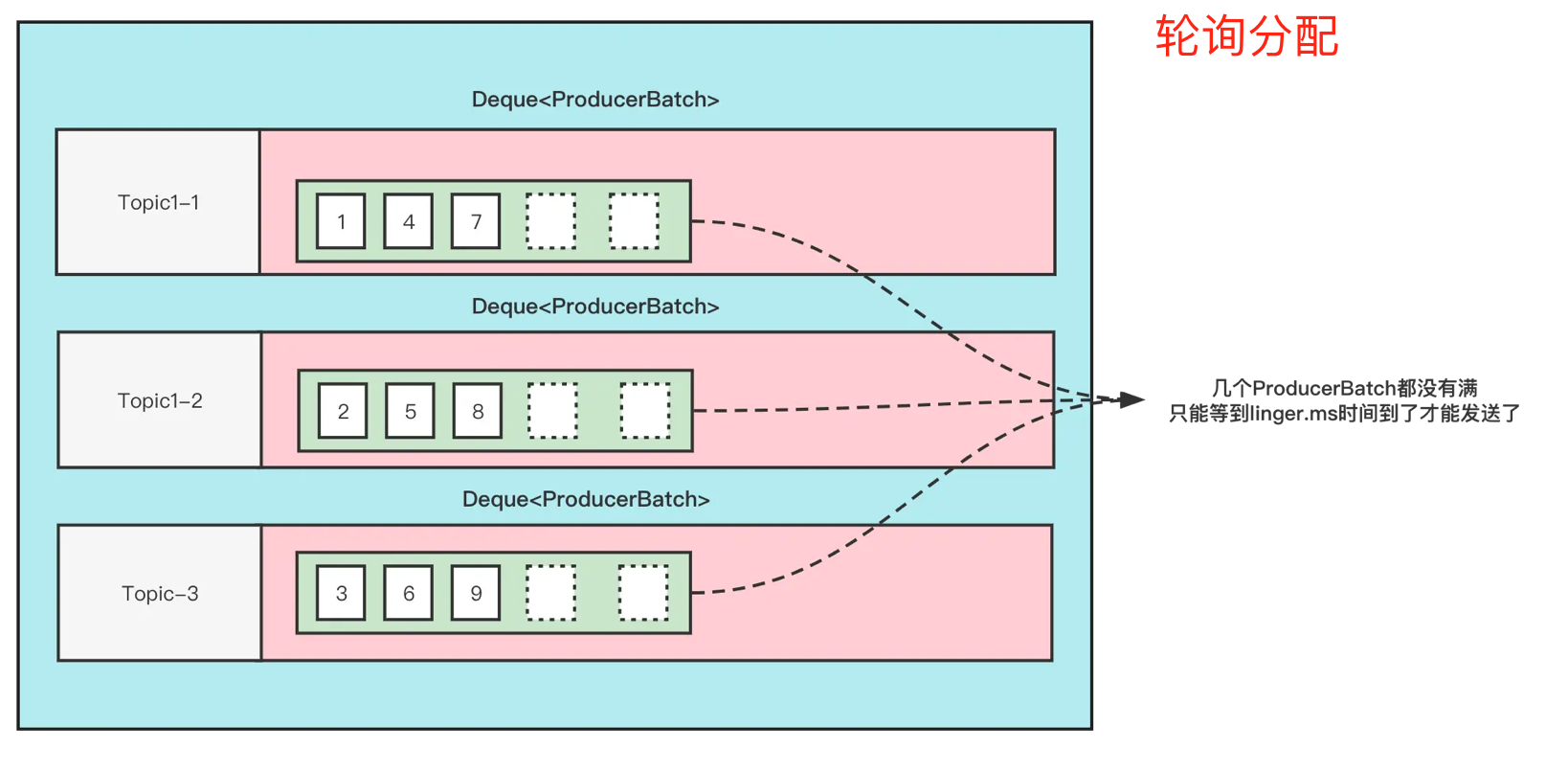
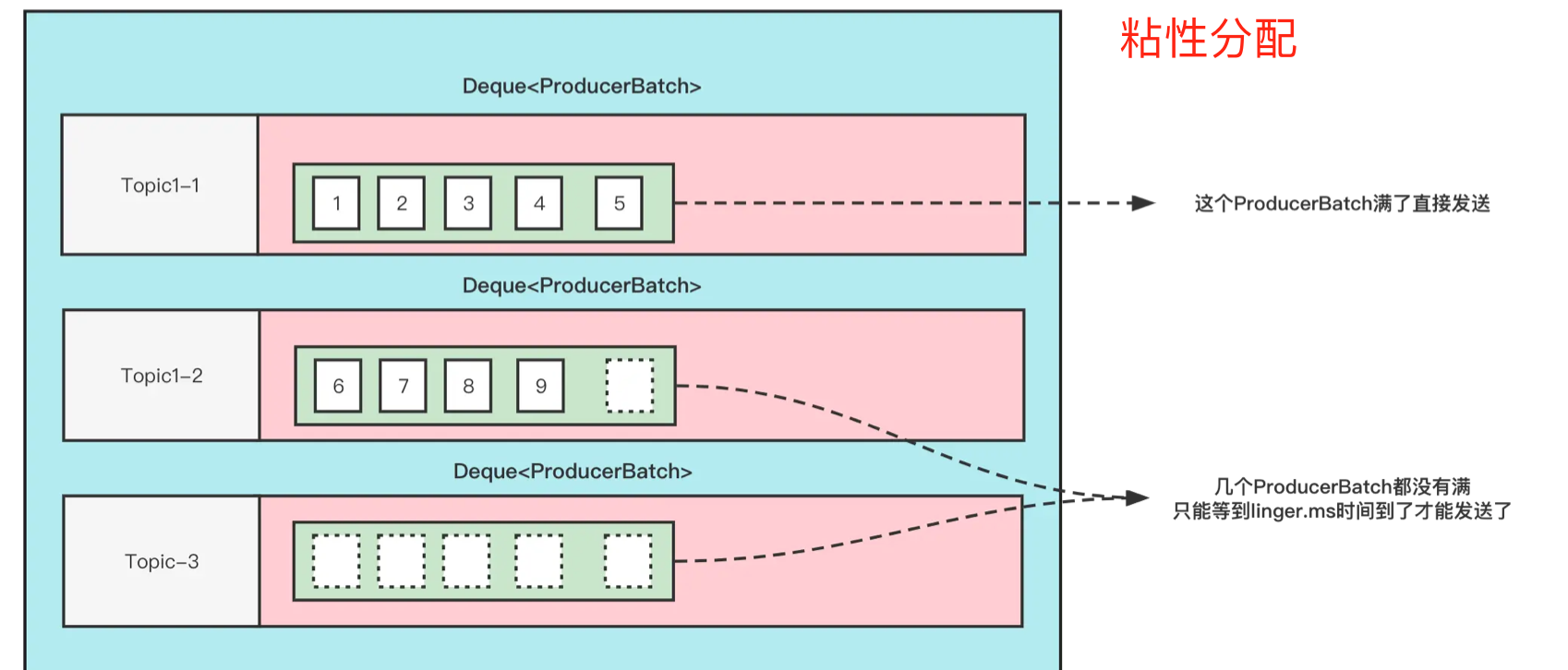
● DefaultPartitioner
org.apache.kafka.clients.producer.internals.DefaultPartitioner
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
2
3
4
5
6
7
8
如果消息带key,则对key进行hash后取模对应到partition。如果不带key,则走粘性分区的相关逻辑。
● 自定义分区器
实现接口Partitioner并实现其中的方法,并在初始化Producer时指定对应的分区器:
Properties props = new Properties();
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
Producer<String, String> producer = new KafkaProducer<>(props);
2
3
# ②RecordAccumulator
org.apache.kafka.clients.producer.internals.RecordAccumulator
kafka性吞吐量更高主要是由于Producer端将多个小消息合并,批量发向Broker。kafka采用异步发送的机制,当发送一条消息时,消息并没有发送到broker而是缓存起来,然后直接向业务返回成功,当缓存的消息达到一定数量时再批量发送。
此时减少了网络io,从而提高了消息发送的性能,但是如果消息发送者宕机,会导致消息丢失,业务出错,所以理论上kafka利用此机制提高了io性能却降低了可靠性。

public final class RecordAccumulator {
private final int batchSize;
private final int lingerMs;
private final long retryBackoffMs;
private final int deliveryTimeoutMs;
private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches;
private final BufferPool free;
private final IncompleteBatches incomplete;
// The following variables are only accessed by the sender thread, so we don't need to protect them.
private final Set<TopicPartition> muted;
……
}
2
3
4
5
6
7
8
9
10
11
12
CopyOnWriteMap
org.apache.kafka.common.utils.CopyOnWriteMap
kafka自定义CopyOnWriteMap类型,保存了topicPartition与队列的关系。队列里有一个个的小批次,里面是很多消息。这样好处就是可以一次性的把消息发送出去,不至于来一条发送一条,浪费网络资源。
为什么用CopyOnWriteMap类型?可以先看看kafka是如何定义的。
public class CopyOnWriteMap<K, V> implements ConcurrentMap<K, V> {
private volatile Map<K, V> map; //保证线程的可见性
public CopyOnWriteMap() {
this.map = Collections.emptyMap();
}
public V get(Object k) { //读操作线程安全
return map.get(k);
}
public synchronized V put(K k, V v) { //更改操作保证线程安全
Map<K, V> copy = new HashMap<K, V>(this.map);
V prev = copy.put(k, v);
this.map = Collections.unmodifiableMap(copy);
return prev;
}
public synchronized V putIfAbsent(K k, V v) {
if (!containsKey(k))
return put(k, v);
else
return get(k);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
从上面可以看出来进行put修改操作时,会对当前的map进行复制操作,并在复制的map上进行修改操作。修改期间,其他线程会读取未复制的map,保证了线程的安全。
同时,因为读操作不会加锁,所以CopyOnWriteMap适合读多写少的场景。对于kafka来说,对于读操作,每生产一条消息,都需要从这个map中读取;对于写操作,假设有10个分区,就会向这个map中插入10条数据。综上来看,读操作是远远大于写操作的。
可见CopyOnWriteMap这个结构在高并发下是线程安全的
但由此也带来了问题,生产者端消息这么多,一个批次发送完了就不管了去等待 JVM 的垃圾回收的时候,很有可能会触发 full gc。一次 full gc,整个 Producer 端的所有线程就都停了,所有消息都无法发送了,由此带来的损耗也是不可小觑。
kafka设计了内存池,用来反复利用被发送出去 RecordBatch,以减少 full gc。
bufferPool

public class BufferPool {
private final long totalMemory;
private final int poolableSize;
private final ReentrantLock lock;
private final Deque<ByteBuffer> free;
private final Deque<Condition> waiters;
/** Total available memory is the sum of nonPooledAvailableMemory and the number of byte buffers in free * poolableSize. */
private long nonPooledAvailableMemory;
……
}
2
3
4
5
6
7
8
9
10
当CopyOnWriteMap的队列中的ProducerBatch不够时,会向bufferPool申请新的ProducerBatch空间。当ProducerBatch发送成功后,会向bufferPool归还空间。

org.apache.kafka.clients.producer.internals.BufferPool#allocate
可以看出,就算是使用异步的发送方式,如果没有设置好缓存大小的话,也是会出现阻塞的。
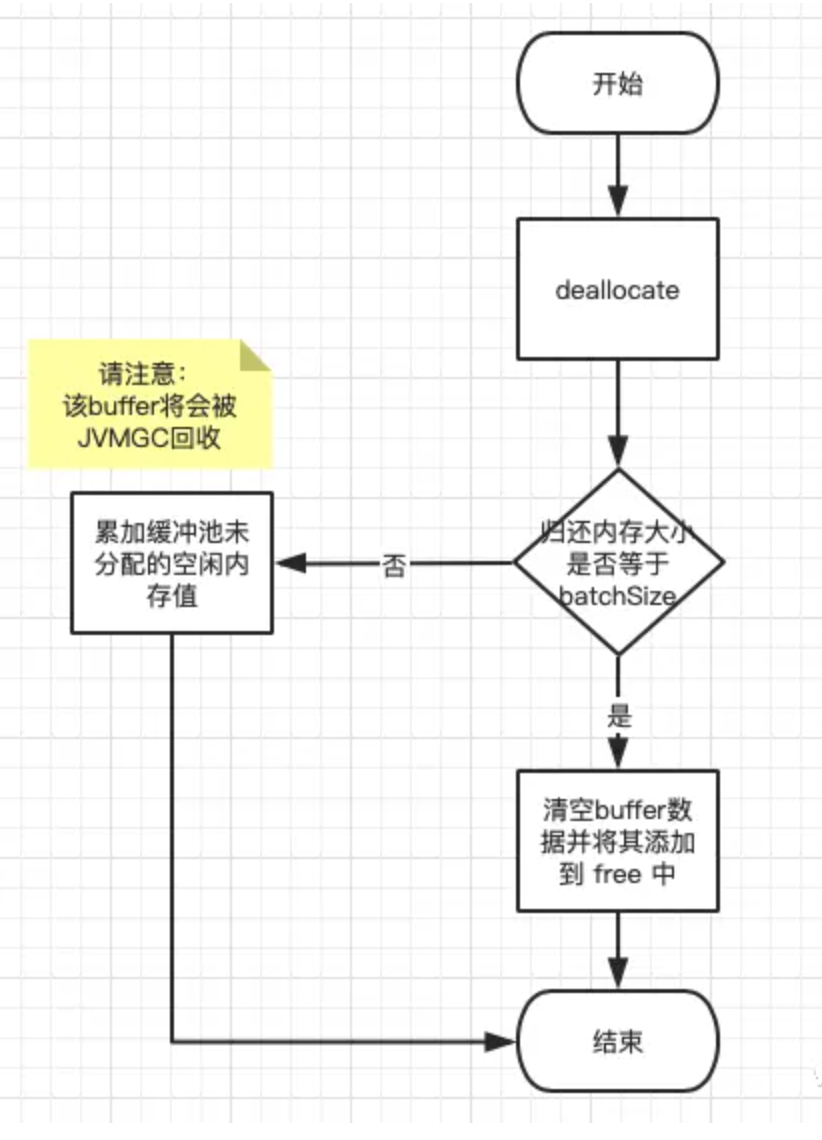
org.apache.kafka.clients.producer.internals.BufferPool#deallocate(java.nio.ByteBuffer, int)
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
this.nonPooledAvailableMemory += size;
}
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
从deallocate可以看出:如果要释放的batch的size大于poolableSize的话,是不会进入free进行内存重复利用的,反而是等待 垃圾回收器来进行回收。如果因为batch.size设置不当,则会导致频繁的GC。
# 3. SenderThread 线程做了什么
重要的成员
public class Sender implements Runnable {
private final KafkaClient client; // 为 Sender 线程提供管理网络连接进行网络读写
private final RecordAccumulator accumulator; // 消息累加器
private final ProducerMetadata metadata; // 生产者元数据
private final int maxRequestSize; //发送消息最大字节数。
private final short acks; // 生产者的消息发送确认机制
private final int retries; // 发送失败后的重试次数,默认为0次
private volatile boolean running; // Sender 线程是否还在运行中
private volatile boolean forceClose; // 是否强制关闭,此时会忽略正在发送中的消息。
private final int requestTimeoutMs; // 等待服务端响应的最大时间,默认30s
private final long retryBackoffMs; // 失败重试退避时间
private final ApiVersions apiVersions; // 所有 node 支持的 api 版本
private final Map<TopicPartition, List<ProducerBatch>> inFlightBatches; // 正在执行发送相关的消息批次集合, key为分区,value是 list<ProducerBatch> 。
2
3
4
5
6
7
8
9
10
11
12
13
14
Sender 线程实现了 Runnable 接口,会不断的调用 runOnce(),这是一个典型的循环事件机制。
public void run() {
……
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
……
}
void runOnce() {
……
// 1. 获取当前时间的时间戳。
long currentTimeMs = time.milliseconds();
// 2. 调用 sendProducerData 发送消息,但并非真正的发送,而是把消息缓存在 把消息缓存在inflightBatches中
long pollTimeout = sendProducerData(currentTimeMs);
// 3. 读取消息实现真正的网络发送
client.poll(pollTimeout, currentTimeMs);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# sender线程整体流程
\1. 首先获取元数据,主要是根据元数据的更新机制来保证数据的准确性。
\2. 获取已经准备好的节点。这里会遍历accumulate中的batches,并找出满足发送条件的batch,并统计其所在partition的leader所在node节点。返回集合readyNodes
org.apache.kafka.clients.producer.internals.RecordAccumulator#ready
\3. 如果主题 Leader 分区对应的节点不存在,则强制更新元数据。
\4. 循环 readyNodes 并检查客户端与要发送节点的网络是否已经建立好了。在 NetworkClient 中维护了客户端与所有节点的连接,这样就可以通过连接的状态判断是否连接正常。
怎么检查一个node是否有没有与客户端建立好连接?
org.apache.kafka.clients.NetworkClient#ready
\5. 获取上面返回的已经准备好的节点上要发送的 ProducerBatch 集合。accumulator#drain() 方法就是将 「TopicPartition」-> 「ProducerBatch 集合」的映射关系转换成 「Node 节点」->「ProducerBatch 集合」的映射关系,如下图所示,这样的话按照节点方式只需要2次就完成,大大减少网络的开销。
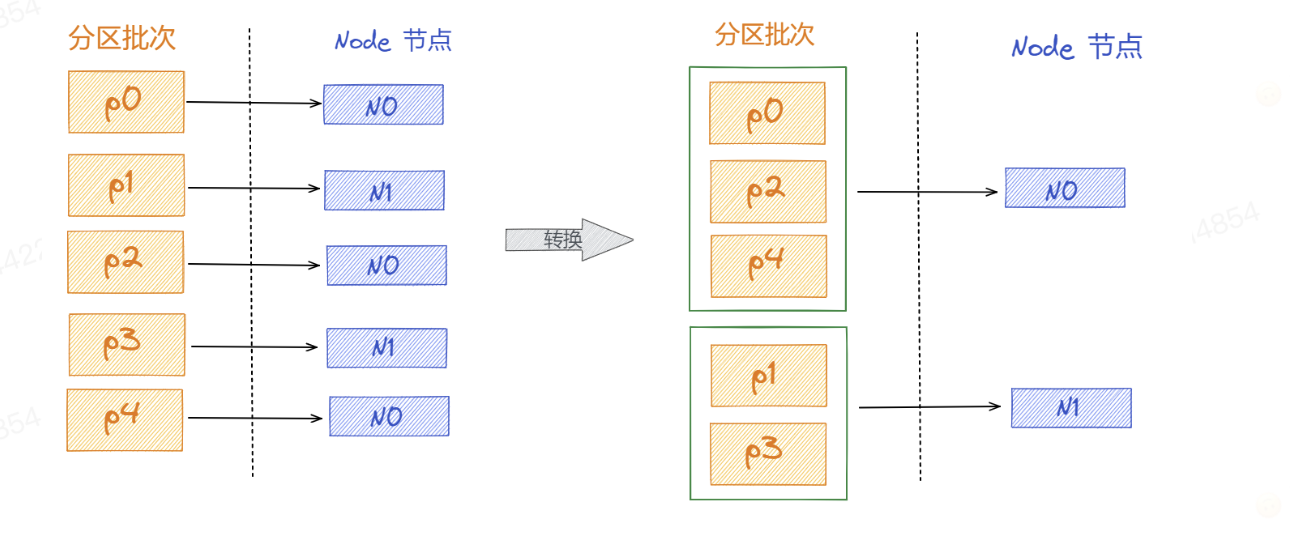
Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区,Deque<ProducerBatch>>的保存形式转变成<Node,List< ProducerBatch>的形式,其中Node表示Kafka集群的broker节点。对于网络连接来说,生产者客户端是与具体的broker节点建立的连接,也就是向具体的 broker 节点发送消息,而并不关心消息属于哪一个分区;而对于 KafkaProducer的应用逻辑而言,我们只关注向哪个分区中发送哪些消息,所以在这里需要做一个应用逻辑层面到网络I/O层面的转换。
\6. 将从消息累加器中读取的数据集,放入正在执行发送相关的消息批次集合中inFlightBatches。
\7. 发送消息暂存到 NetworkClient inflightRequests 里。inflightRequests 对已经被发送或正在被发送但是均未接收到响应的客户端请求集合的一个封装。
org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest
# 什么是满足发送要求的batch
org.apache.kafka.clients.producer.internals.RecordAccumulator#ready
boolean full = deque.size() > 1 || batch.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
}
2
3
4
5
6
# 生产者如何进行消息重试
sendProducerData ->sendProduceRequests ->handleProduceResponse->completeBatch->canRetry
org.apache.kafka.clients.producer.internals.Sender#handleProduceResponse
在消息发送完成后,producer会接受到broker的响应信息,handleProduceResponse 就用于对响应的消息进行处理
org.apache.kafka.clients.producer.internals.Sender#canRetry
通过源码来看,如果返回的错误是 Errors.NONE 错误,则可以进行进行是否消息可重试的检测
private boolean canRetry(ProducerBatch batch, ProduceResponse.PartitionResponse response, long now) {
return !batch.hasReachedDeliveryTimeout(accumulator.getDeliveryTimeoutMs(), now) &&
batch.attempts() < this.retries &&
!batch.isDone() &&
(transactionManager == null ?
response.error.exception() instanceof RetriableException :
transactionManager.canRetry(response, batch));
}
2
3
4
5
6
7
8
可以进行重试的条件:
● 重试的次数,这个就是我们的客户端的配置
● 异常是不是可重试异常response.error.exception() instanceof RetriableException),下面就是全部的可重试异常
org.apache.kafka.common.errors.RetriableException
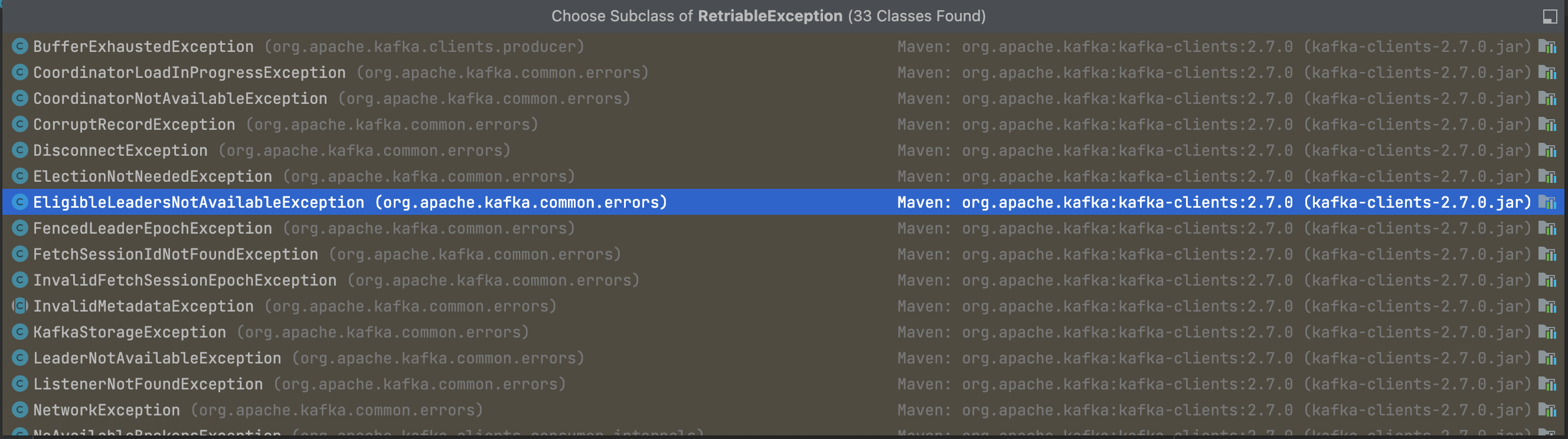
如果发现batch是可以被重试的,则将这个batch重新加到RecordAccumulate累加器中。需要注意的是重试添加的batch是添加在duque的头部,而主线程发送消息是添加在batch的尾部。
加到deque的头部后,sender什么时候对这个重试的batch进行发送呢?
org.apache.kafka.clients.producer.internals.RecordAccumulator#ready
long waitedTimeMs = batch.waitedTimeMs(nowMs);
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
boolean full = deque.size() > 1 || batch.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
}
2
3
4
5
6
7
8
9
从上面的代码可以看出,重试的代码并没有进行 partitioner 分区器的重新分配,重试的消息会发送到相同的分区。保证了幂等性
# 生产者callback机制
发送一条消息的流程
String value = " this is another message_" + i;
ProducerRecord<String,String> record = new ProducerRecord<String, String>(topic,i+"",value);
procuder.send(record,new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println("message send to partition " + metadata.partition() + ", offset: " + metadata.offset());
}
});
2
3
4
5
6
7
8
CallBack.class
public interface Callback {
void onCompletion(RecordMetadata metadata, Exception exception);
}
2
3
CallBack只有一个onCompletion方法,传入两个参数metadata和exception。
那么在一个消息的发送过程中,他的一个子实现对象的是如何进行保存,又如何进行调用的呢?
首先,用户自定义的Callback对象会在org.apache.kafka.clients.producer.KafkaProducer#doSend 中进行一次封装
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
2
封装后可以在回调时同时调用拦截器的onAcknowledgement方法和用户自定义的onCompletion方法
后续主线程将信息追加到RecordAccumate中的时候,会将interceptCallback 添加到ProducerBatch中:
org.apache.kafka.clients.producer.internals.ProducerBatch#tryAppend
thunks.add(new Thunk(callback, future));
至此,主线程对回调函数的干预就到此为止了。
以上其实是对batch中每个record的回调函数的讲解.后续batch会被封装为ClientRequest对象存放inflightRequests中。在其实对于每个ClientRequest本身也会存在一个回调函数。具体代码位置为:
org.apache.kafka.clients.producer.internals.Sender#sendProduceRequest
RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
2
3
4
5
为什么ClientRequest 也会需要一个回调函数?因为producer与broker的交互最终是落实到与clientRequest进行交互的,最终进行回调的时候,broker会返回给producer clientResponse,通过clientResponse中的回调函数就可以进行相应的函数调用:
具体的回调函数可以从代码 org.apache.kafka.clients.NetworkClient#poll 开始
poll -> completeResponses -> clientResponse.onComplete -> handleProduceResponse -> completeBatch -> done -> completeFutureAndFireCallbacks
# 四. 总结
#
参考:
● Apache Kafka (opens new window)
● 《深入理解kafka核心设计与实践原理》