kafka存储结构
kafka存储结构
https://articles.zsxq.com/id_d912swekk0we.html
# kafka如何存储数据
首先,kafka是一个流式处理平台,会有很多的数据源源不断地向kafka发送数据,所有会有大量的数据存放到kafka中。如果我们将说句存放到内存中,这肯定是不行的很有可能会造成oom。所以我们最开始的目标肯定是将数据放在磁盘中。
那么如果存放在磁盘中,消费者要进行消费,从磁盘中取出数据会不会非常慢呢?
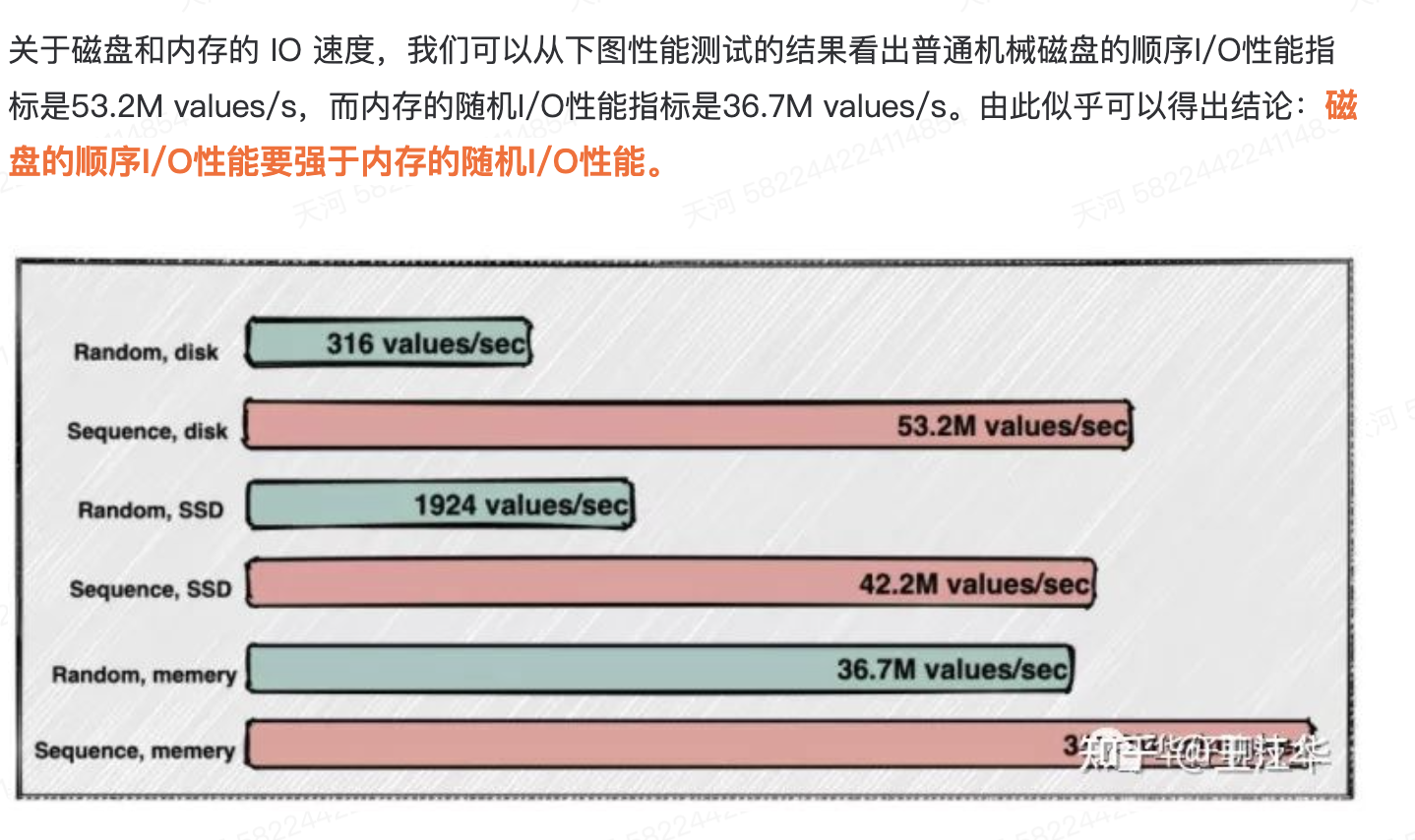
这么看来,想要实现磁盘的读取速率和磁盘相当,一个很好的办法就是在磁盘中采用顺序读写,这时就可以用到日志log,日志log就是采用顺序读写的方式。
# 从kafka特性看存储特性
kakfa操作有哪些特性呢?
- 写操作:写并发要求非常高,基本得达到百万级 TPS,顺序追加写日志即可,无需考虑更新操 作
- 读操作:相对写操作来说,比较简单,只要能按照一定规则高效查询即可 (offset或者时间 戳)
对于写操作,因为我们才用的顺序写入,速度还是比较快的,可以和内存操作相媲美。
对于查询操作,我们想要从海量的数据中找到我们想要的offset,这个时候肯定是要用到索引的。那么应该用哪种索引呢?
# b+树
B+树索引需要维护平衡,保持树的结构。在插入和删除数据时,可能需要对树进行重排和平衡操作,确保树的高度不会过高,从而保持搜索性能。这涉及到节点的拆分和合并,可能会导致频繁的磁盘读写。
如果使用B+树,那么每次写入操作都要维护这个索引,还需要有额外的空间来存储这个索引,还有可能会出现“数据页分裂”等操作,对于kafka这种高并发写操作,设计太重了,所以并不适用。
那么有没有什么索引没有那么高的维护成本呢?可以试试hash索引
# hash
我们可以在内存中维护一个map结构,key为offset,value为对应的offset在日志中的物理日志。每次根据offset查询消息的时候,从hash表中得知偏移量,再去读log文件就可以快速定位到要读的数据位置。但是hash索引通常要常驻内存,对于kafka这种大量数据的结构来说,可能会出现OOM。
怎么解决索引太多造成占用空间太大的问题呢?
- 在操作系统虚拟分页中,有种二级页表的概念可以借鉴。这里就不讲解了
- 使用稀疏索引。
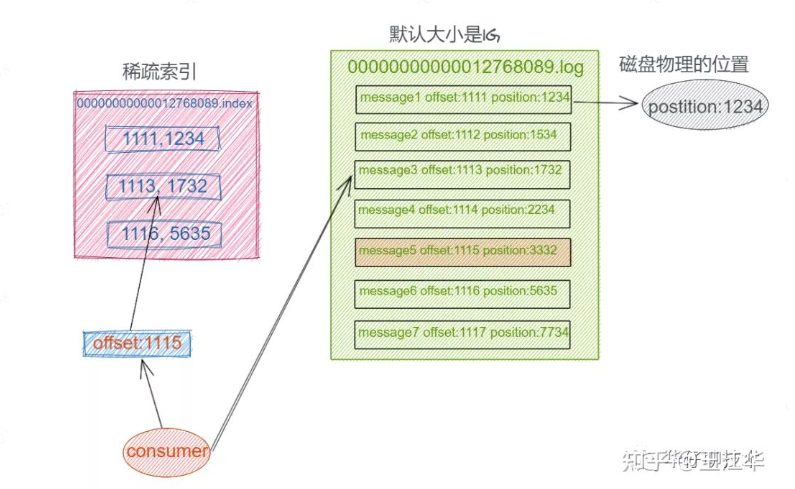
这时候我们可以设想把消息的offset设计成一个有序的字段,这样消息在日志文件中也就有序存放了,也不需要额外引入哈希表结构,可以直接将消息划分成若干个块,对于每个块,我们只需要索引当前块的第一条消息的Offset,这个是不是有点二分查找算法的意思。**即先根据Offset大小找到对应的块,然后再从块中顺序遍历查找。**如下图所示:
# kafka日志结构
日志架构:顺序追加写日志+稀疏哈希索引
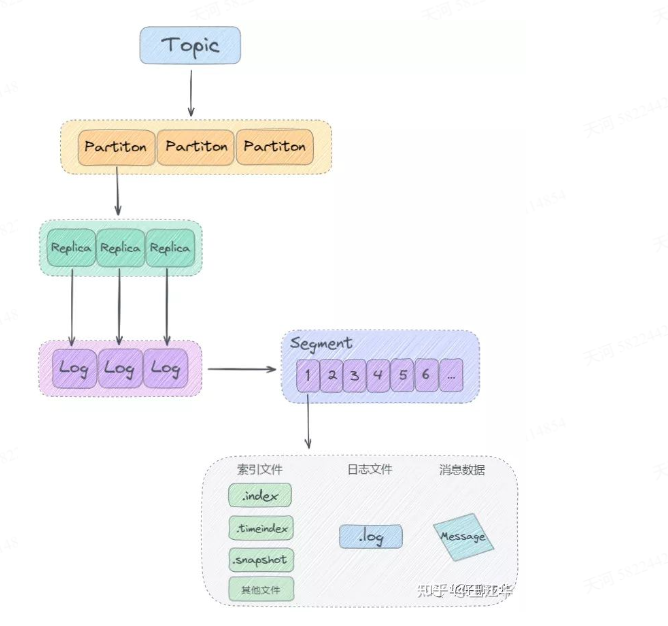

即每个partition有自己的一套日志,生产者发了的message就根据一定的算法分配到这些partition当中
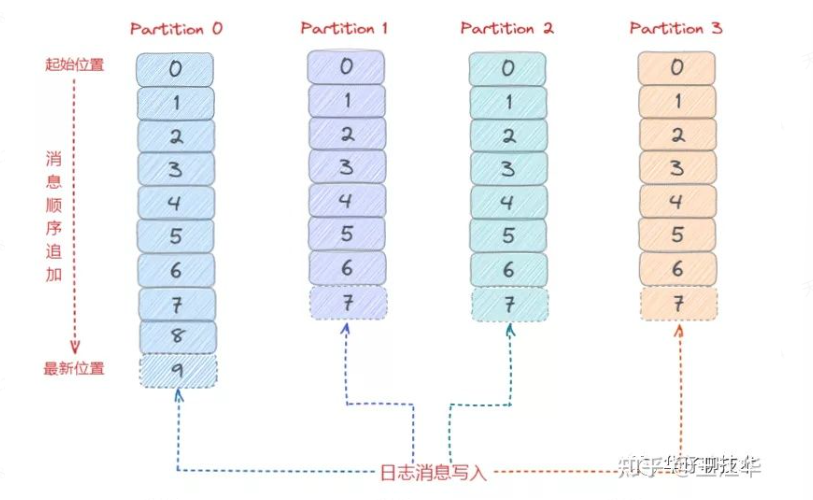
# 目录结构
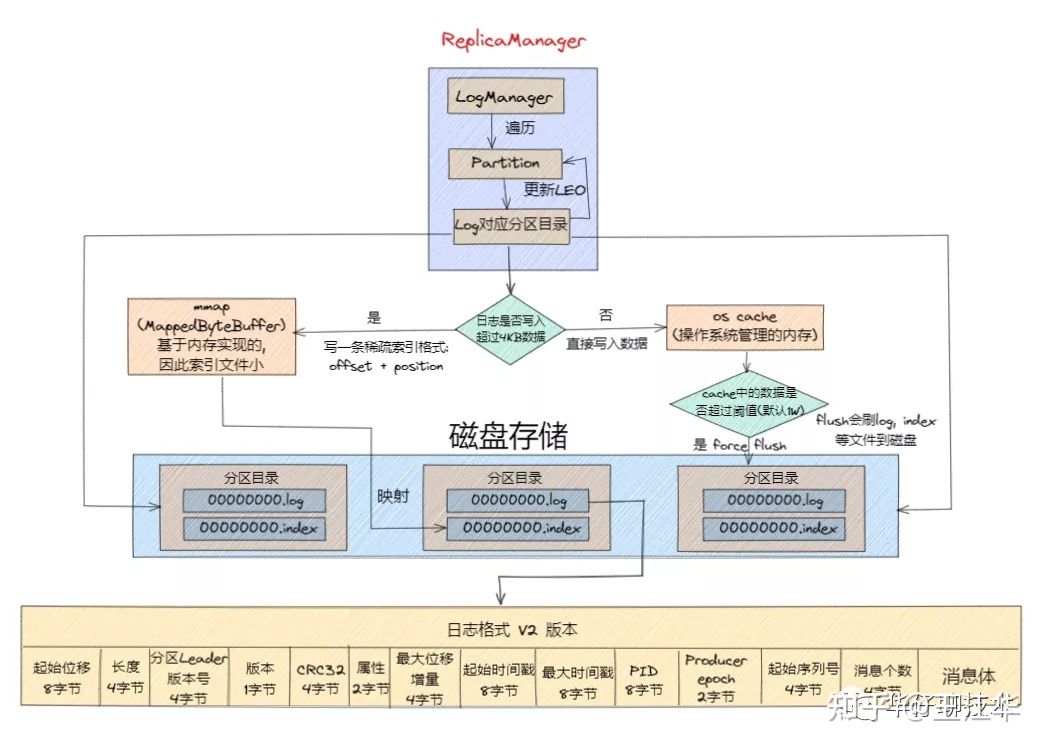
那么Kafka消息写入到磁盘的日志目录布局是怎样的? Log对应了一个命名为<topic>-<partition>的文件夹。
假设现在有一个名为"topic-order"的Topic,该 Topic 中有4个Partition,那么在实际物理存储上表现为"topic-order-0"、“topic-order-1”、“topic-order-2"、“topic-order-3”这4个文件夹。
看上图我们知道首先向Log 中写入消息是顺序写入的。但是只有最后一个LogSegement 才能执行写入操作,之前的所有LogSegement都不能执行写入操作。为了更好理解这个概念,我们将最后一个LogSegement称为""activesegement",即表示当前活跃的日志分段。随着消息的不断写入,当activeSegement满足一定的条件时,就需要创建新的 activeSegement,之后再追加的消息会写入新的activeSegement。

为了更高效的进行消息检索,每个LogSegment 中的日志文件(以".log"为文件后缀)都有对应的几个索引文件:偏移量索引文件(以".index"为文件后缀)、时间戳索引文件(以".timeindex”为文件后缀)、快照索引文件(以".snapshot"为文件后缀)。
其中每个LogSegment都有一个offset来作为基准偏移量(baseOffset),用来表示当前LogSegment中第一条消息的Offset。偏移量是一个64位的Long长整型数,日志文件和这几个索引文件都是根据基准偏移量(baseOffiset)命名的,名称固定为20位数字,没有达到的位数前面用0填充。比如第一个LogSegment的基准偏移量为0,对应的日志文件为00000000000000000000.log。 我们来举例说明,向主题topic-order中写入一定量的消息,某一时刻topic-order-0目录中的布局如下所示:

上面例子中LogSegment对应的基准位移是12768089,也说明了当前LogSegment中的第一条消息的偏移量为12768089,同时可以说明当前LogsSegment中共有12768089条消息(偏移量从0至12768089的消息)。
注意每个LogSegment中不只包含".log".".index"、".timeindex"这几种文件,还可能包含".snapshot"、".txnindex"、“leader-epoch-checkpoint"等文件,以及 ".deleted"、".cleaned"、“.swap"等临时文件。
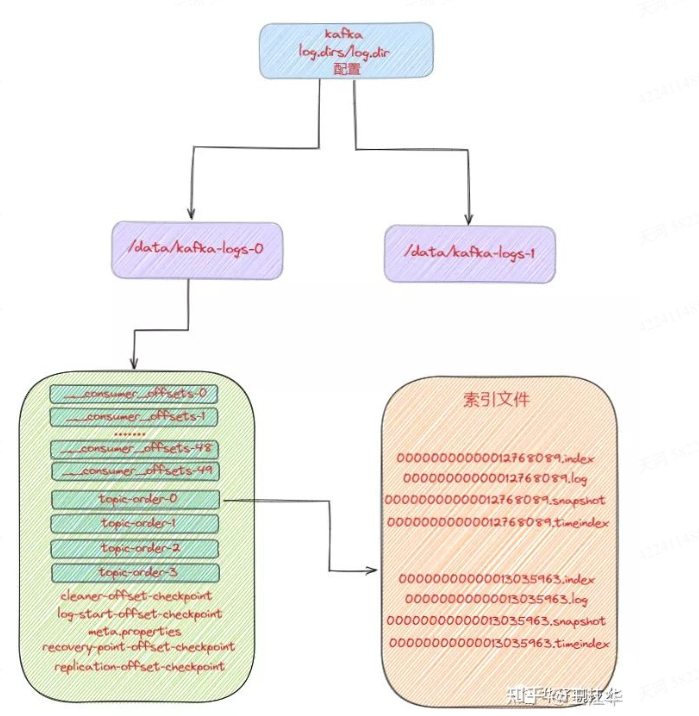
# 分析索引文件工具
kafka-dump-log工具
log文件的文件名都是64位整形,表示这个log文件内存储的第一条消息的offset值减去1(也就是上一个log文件最后一条消息的offset值)。每个log文件都会配备两个索引文件——index和timeindex,分别对应偏移量索引和时间戳索引,且均为稀疏索引。
可以通过Kafka提供的DumpLogSegments小工具来查看索引文件中的信息。
kafka-dump-log.sh --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.index
offset: 197971551 position: 5207
offset: 197971558 position: 9927
offset: 197971565 position: 14624
offset: 197971572 position: 19338
offset: 197971578 position: 23509
offset: 197971585 position: 28392
offset: 197971592 position: 33174
offset: 197971599 position: 38036
offset: 197971606 position: 42732
......
kafka-dump-log.sh --files /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
Dumping /data4/kafka/data/ods_analytics_access_log-3/00000000000197971543.timeindex
timestamp: 1593230317565 offset: 197971551
timestamp: 1593230317642 offset: 197971558
timestamp: 1593230317979 offset: 197971564
timestamp: 1593230318346 offset: 197971572
timestamp: 1593230318558 offset: 197971578
timestamp: 1593230318579 offset: 197971582
timestamp: 1593230318765 offset: 197971592
timestamp: 1593230319117 offset: 197971599
timestamp: 1593230319442 offset: 197971606
......
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
可见,index文件中存储的是offset值与对应数据在log文件中存储位置的映射,而timeindex文件中存储的是时间戳与对应数据offset值的映射。有了它们,就可以快速地通过offset值或时间戳定位到消息的具体位置了。并且由于索引文件的size都不大,因此很容易将它们做内存映射(mmap),存取效率很高。
以index文件为例,如果我们想要找到offset=197971577的消息,流程是:
- 通过二分查找,在index文件序列中,找到包含该offset的文件(00000000000197971543.index);
- 通过二分查找,在上一步定位到的index文件中,找到该offset所在区间的起点(197971592);
- 从上一步的起点开始顺序查找,直到找到目标offset。
最后,稀疏索引的粒度由log.index.interval.bytes参数来决定,默认为4KB,即每隔log文件中4KB的数据量生成一条索引数据。调大这个参数会使得索引更加稀疏,反之则会更稠密
# kafka的日志格式
https://blog.51cto.com/u_15127513/2682934
# 日志的清理
# 日志的压缩
# 零拷贝(sendfile+DMA)
https://blog.csdn.net/funnyrand/article/details/125513774?ydreferer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS5oay8%3D https://www.jianshu.com/p/0af1b4f1e164
在不使用零拷贝的情况下,consumer来消费数据,log保存在broker的磁盘中,此时就需要我们log磁盘通过DMA拷贝到内核,cpu再拷贝到用户空间,之后再拷贝到内核态,在传输到网卡当中。这样就会经历4次上下文切换,2次cpu拷贝,2次DMA拷贝。
使用零拷贝过后,指将数据在内核空间直接从磁盘文件复制到网卡中,而不需要经由用户态的应用程序之手。这样既可以提高数据读取的性能,也能减少核心态和用户态之间的上下文切换,提高数据传输效率。
首先,一个零拷贝的基石需要直接内存访问单元DMA: DMA,又称之为直接内存访问,是零拷贝技术的基石。DMA 传输将数据从一个地址空间复制到另外一个地址空间。当CPU 初始化这个传输动作,传输动作本身是由 DMA 控制器来实行和完成。因此通过DMA,硬件则可以绕过CPU,自己去直接访问系统主内存。很多硬件都支持DMA,其中就包括网卡、声卡、磁盘驱动控制器等。 有了DMA技术的支持之后,网卡就可以直接区访问内核空间的内存,这样就可以实现内核空间和应用空间之间的零拷贝了,极大地提升传输性能。
之后,kafka从log中传输数据的流程就变为:
**(1)**操作系统将数据从磁盘中加载到内核空间的Read Buffer(页缓存区)中。 **(2)**操作系统之间将数据从内核空间的Read Buffer(页缓存区)传输到网卡中,并通过网卡将数据发送给接收方。 **(3)**操作系统将数据的描述符拷贝到Socket Buffer中。Socket 缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到 Socket 缓存。
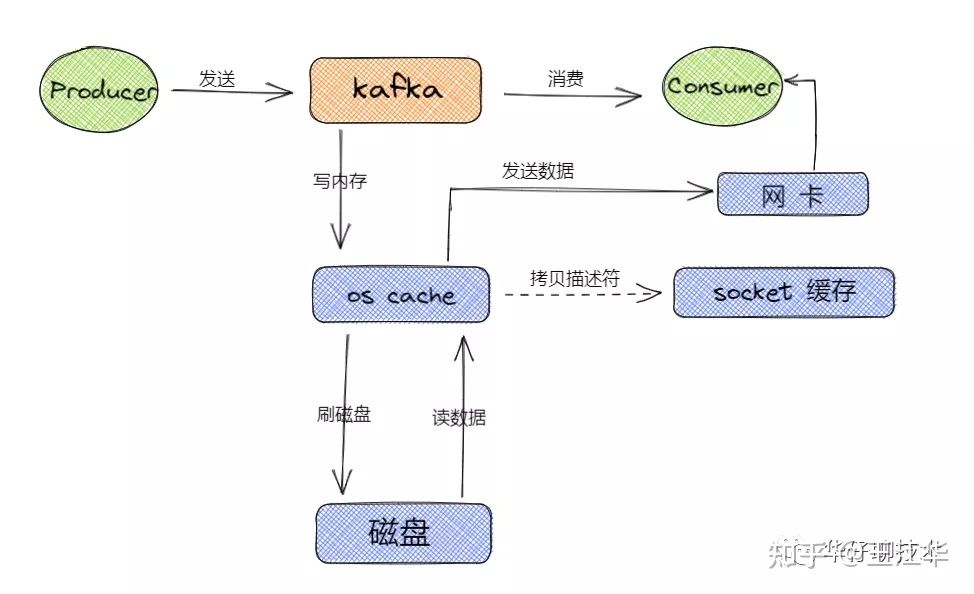
# page cache
生产者将信息发送到broker过后,不会直接写磁盘,而是先存到内核的page cache中,待合适的时机由操作系统写到磁盘中。
在 Kafka 中,大量使用了 PageCache, 这也是 Kafka 能实现高吞吐的重要因素之一,当一个进程准备读取磁盘上的文件内容时,操作系统会先查看待读取的数据页是否在 PageCache 中,如果命中则直接返回数据,从而避免了对磁盘的 /0 操作;如果没有命中,操作系统则会向磁盘发起读取请求并将读取的数据页存入 PageCache 中,之后再将数据返回给进程。同样,如果一个进程需要将数据写入磁盘,那么操作系统也会检查数据页是否在页缓存中,如果不存在,则PageCache 中添加相应的数据页,最后将数据写入对应的数据页。被修改过后的数据页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性。
# 总结