
 git三剑客
git三剑客
# 一些命令需要注意
git add -u 仅仅添加已经被git追踪且跟新的文件到咱存区,不会添加没有被跟踪的文件
git reset --hard commitHash 回退到某个commit,并放弃其后的commit
git reset --hard 就是放弃当前的所有更改,回到最近的一个提交状态
git reset --hard HEAD~1
问:如果git reset --hard 到错误的版本还有机会复原吗?
可以的,只要我们拿到对应的commitHash就可以
- 方案一:
使用git reflog ,可以查看历史HEAD的指向commit,我们拿到对应的commitHash后,使用git reset --hard commitHash就可以了
- 方案二;
去.git/objects中查找对应的节点,但是这种形式可能效率较低,建议使用方案一
恢复本质:拿到想要恢复版本的commitHash
- 文件名字修改规范操作
- 之前的流程
将本地目录 mv fileName1 fileName2
在暂存区 git rm fileName1
将新文件加到暂存区 git add fileName2
- 规范的流程
git mv fileName1 fileName2 可以不用进行add等
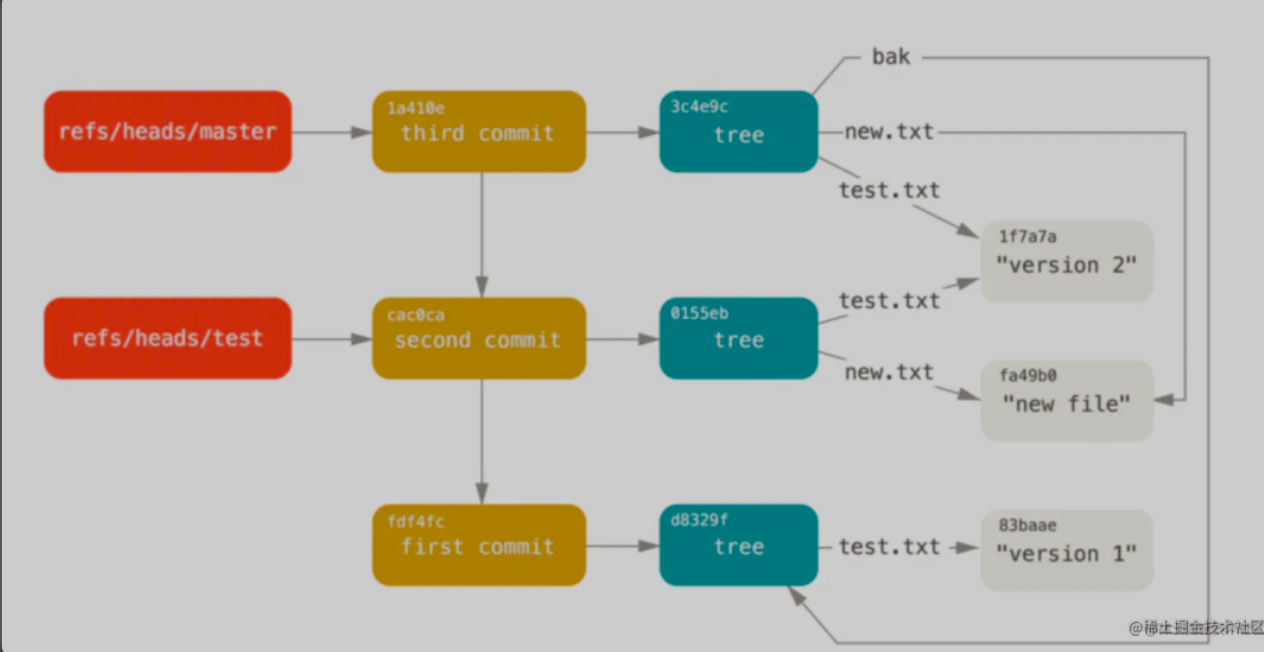
版本日志 git log git log --oneline 以一行的形式显示日志 git log -n4 查看最新的n条日制 git log --graph 以地图的形式查看 git log --all 查看全部日志
查看git 对象信息 git cat-file -t hash 查看hash 的类型 git cat-file -p hash 查看hash的具体信息
.git中四个重要的目录 config 本地git配置信息 refs git中不同分之的信息 HEAD 当前使用的分支 objects 存放了tree等信息
怎么删除不需要的分支
检测删除(可能检测是否需要合并)git branch -d 分支名
强制删除 git branch -D 分支名
- 修改已提交的commit的message
git commit -amend 对最近一次提交作出变更
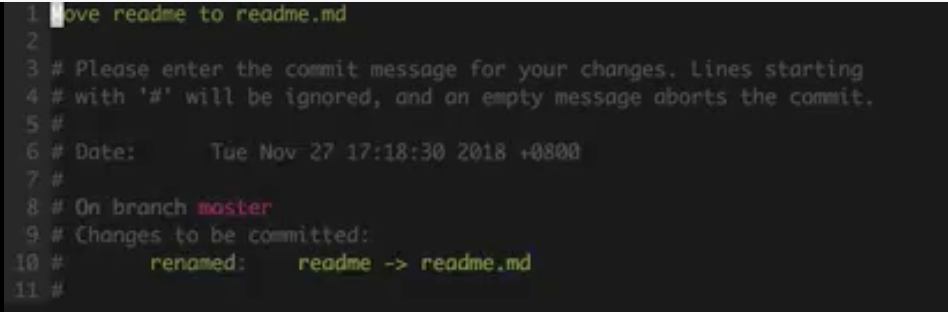
- 对旧的commit进行变更
git rebase -i commithash的父亲
rebase是基于的意思,我们要修改commit1,那么我们要在commit1的父节点来进行修改commit2
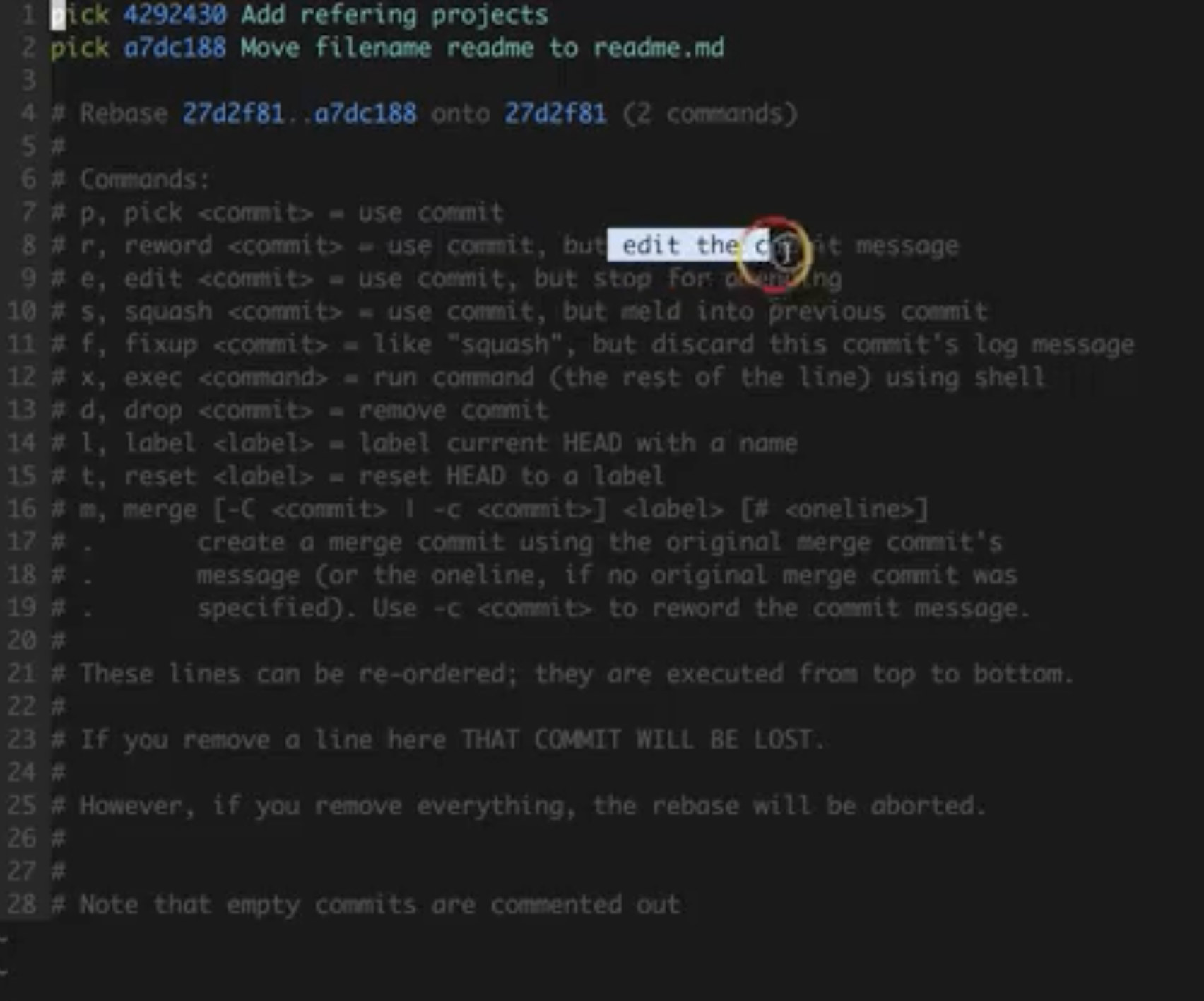
需要进行实战commit message进行修改
首先最基本的就是应该知道git rebase到底有什么用
①目前看看项目中的git日志

②我们现在要把00eebc1 的commit信息改为second
git rebase -i be58967 (注意,这里我们需要rebase想要更改的commit的父commit)
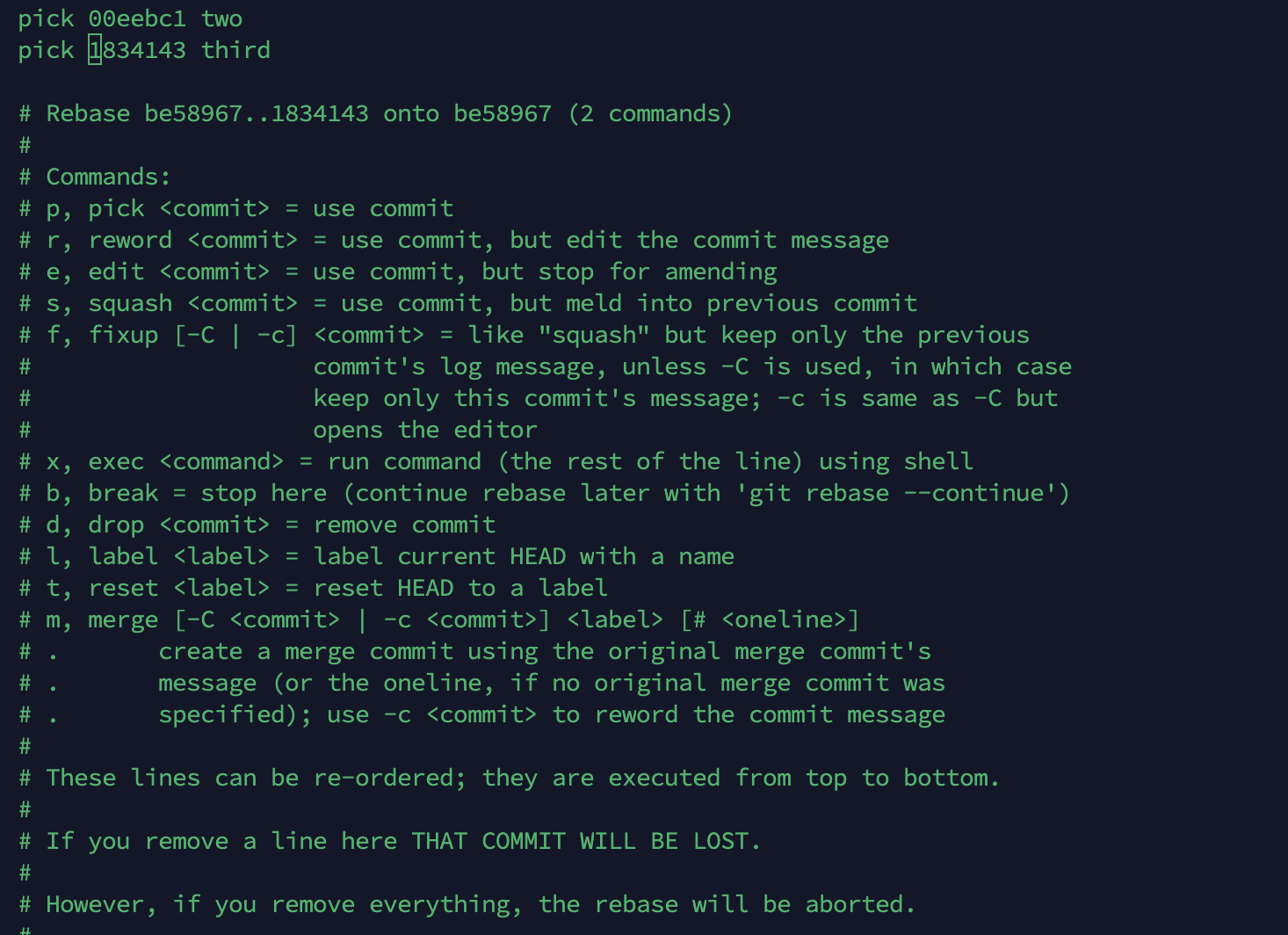
从图上看出,真实有效的为第一行,其他的都是help注释,这里我们将pick改为reword来更改message
保存退出后,会自动跳转到下面的界面,我们将对应的数据更改为second就可以了

可以看见更改成功了
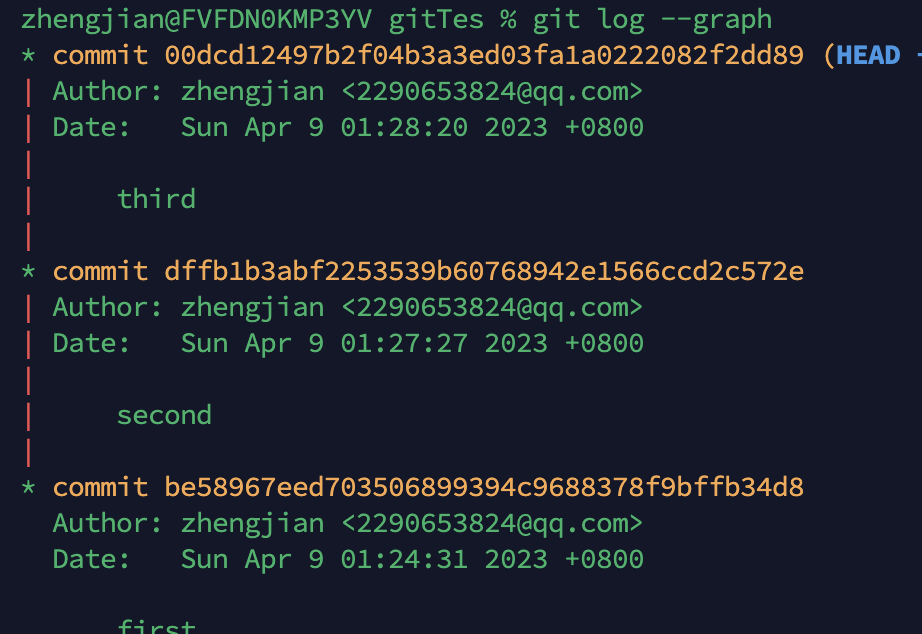
注意,以上的变更一般在自己开发的分支上进行变更,在合作开发时,一般不要随意变更别人message
- 怎么把几个连续的commit变为一个commit
①选择需要合并commit的父commit作为rebase。
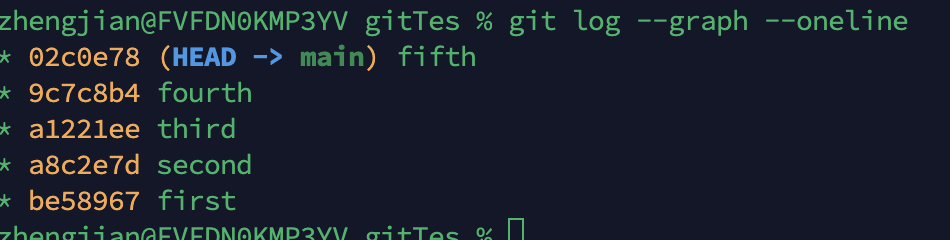
如图所示,我想要合并2,3,4 那么我应该将first作为rebase
Git rebase -i be58967
②将要进行合并的分支选做squash命令
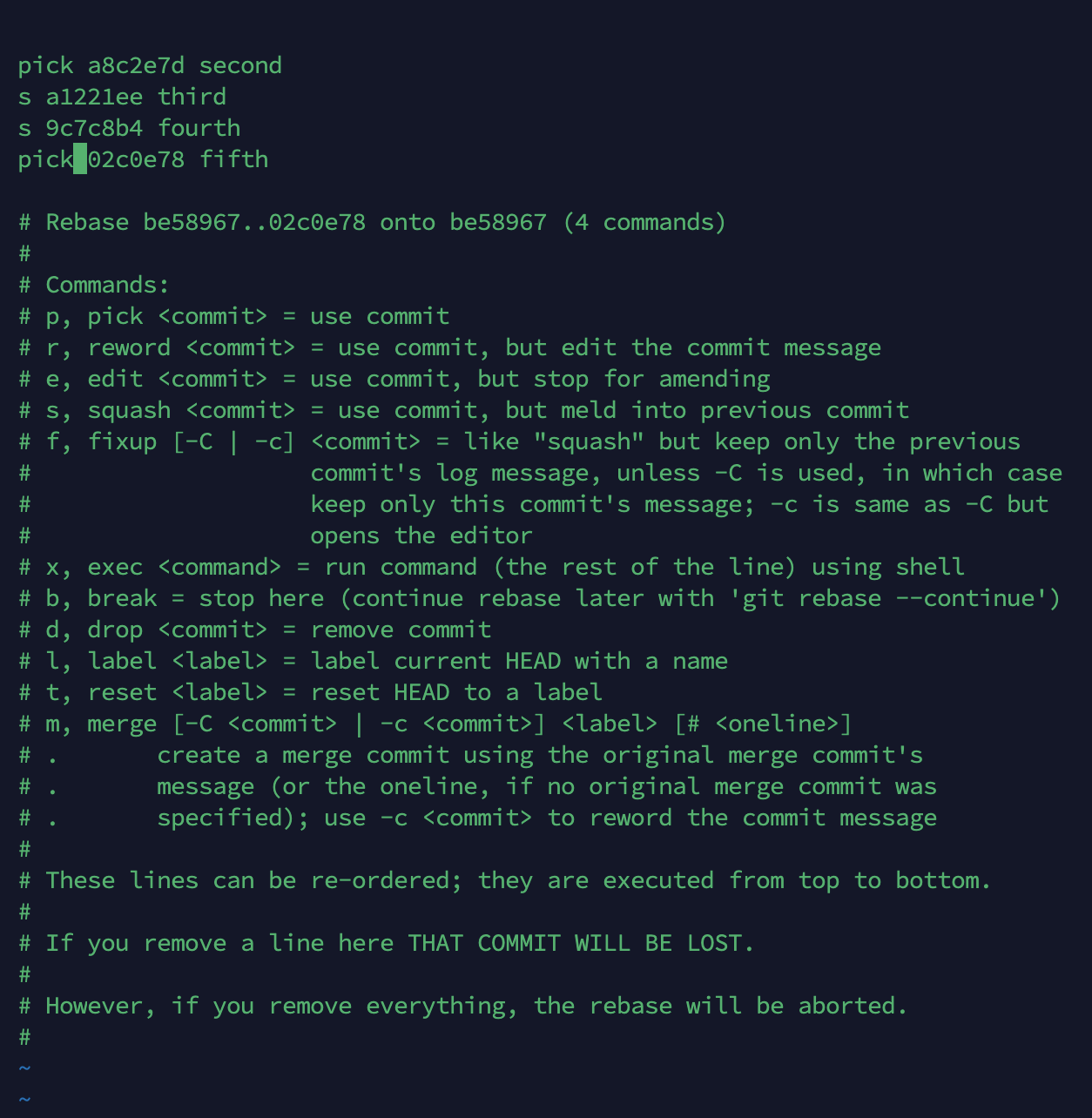
③添加合并后的commit message
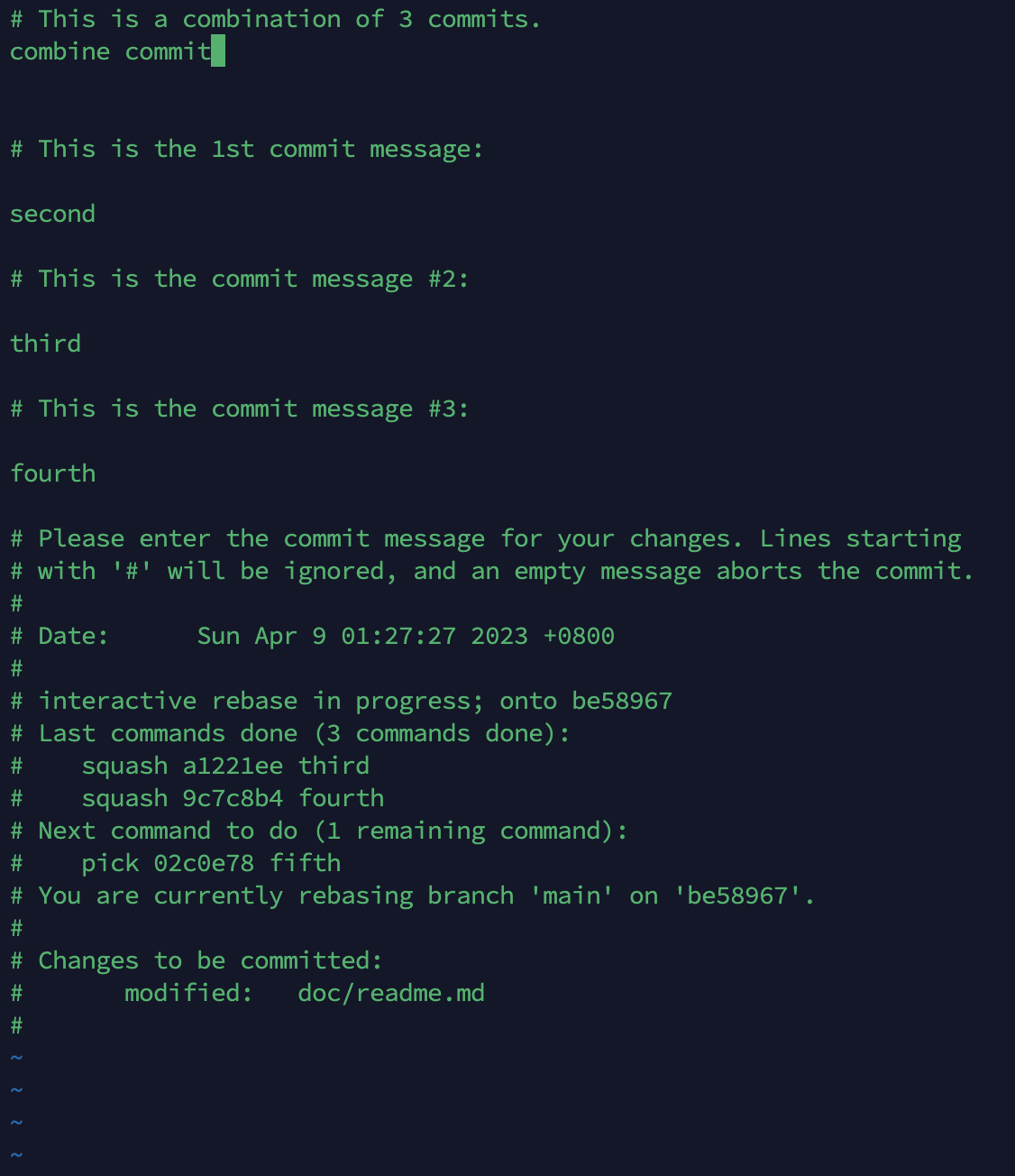
合并成功·
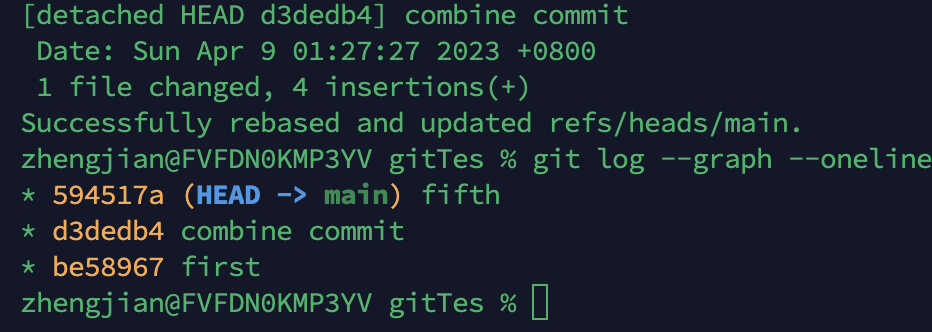
从上面可以看出来,似乎rebase操作都会涉及到分离头指针
看到上面的,合并后的commit相当于生成了一个新的commitHash,而最新的节点commit因为其父节点变化了,所以自己也产生了一个新的commithash,所以才会出现updated refs/heads/main,就是因为分支main指向的节点已经变化了。
- 怎么把几个间隔的commit变成一个comomit

如图所示,我想将first合并到fifth分支,该怎么做了。我们之前说了rebase要有一个根基,但是现在first父节点我们是没有的该怎么办?
- 复制first的hash,然后在rebase -i中进行添加
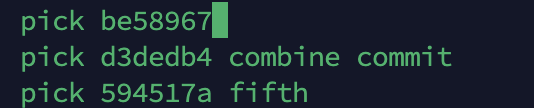
如图所示,我们手动添加了第一行commit。
现在我们要将first合并到fifth应该怎么做了?
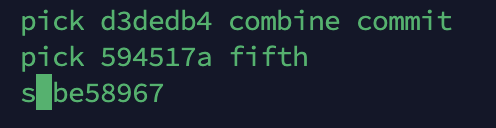
若果有冲突解决冲突,然后填写新commit的message
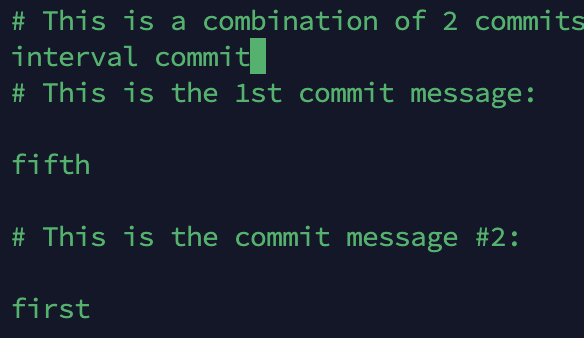
保存退出即可:

当您使用 git rebase 命令合并多个 commit 时,实际上是修改了本地的 Git 历史记录。如果此时直接使用 git push 命令将修改推送到远程仓库,那么 Git 会拒绝此操作,提示 “non-fast-forward” 错误。
这是因为 Git 的默认行为是只允许进行 fast-forward 合并,也就是只允许在原有基础上新增提交,而不允许强制覆盖历史记录。如果要将修改推送到远程仓库,需要使用 git push --force 或 git push -f 命令。
然而,强制推送可能会导致潜在的问题,如意外覆盖他人提交、丢失历史记录等,所以在进行强制推送前,请确保您已经充分理解其风险,并谨慎操作。
另一种更安全的方法是使用 git push --force-with-lease 命令。该命令会先检查远程仓库的状态,确保没有其他人在您之前推送过修改,然后再进行强制推送。这可以避免意外覆盖他人提交的风险。
- diff操作
怎么对比暂存区与已经提交的版本之间的差异
git diff --cached
怎么对比工作区与暂存区之间的差异
git diff
只针对某一个文件
git diff -- fileName1 fileName2
撤销暂存区
git reset Head -- filename1 filename2
Git reset HEAD 撤销全部
撤销工作区
git checkout -- filename1 filename2
删除最近的几次commit
git reset --hard hash
看几次commit之间的差异
git diff commt1 commit2 -- file
- 删除文件姿势
git rm file
也会自动将工作区的进行文件删除
git stash pop /apply 区别
- 指定不需要纳入git的文件
.gitignore
# git中的对象
git中的四个重要对象commit 、 tree、 blob、tag(tag可以去tag专题看介绍,下面只介绍其他三种)
文件管理

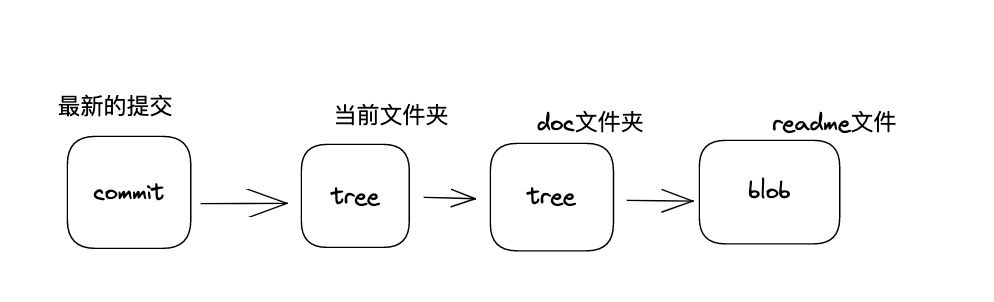
在Git中,commit、tree和blob是三个核心的对象类型,它们有着紧密的关系。
# 对象的介绍
首先,blob(二进制大对象)是指文件的内容,它可以是任何类型的文件,包括源代码、图像、音频或视频等。每个blob在Git仓库中都有一个唯一的SHA-1哈希值来标识它。
其次,tree(树对象)是一种特殊的对象,它描述了一个目录的结构,包含一个或多个blob对象和其他tree对象,以及它们之间的关系。与blob一样,每个tree也有一个唯一的SHA-1哈希值。
最后,commit(提交对象)指向一个tree对象,并包含一些元数据,例如提交者、时间戳、提交消息等。当创建一个新的提交时,Git会创建一个新的commit对象并将其指向当前的tree对象。每个commit也有一个唯一的SHA-1哈希值。
因此,这三种对象类型的关系如下:一个commit对象指向一个tree对象,该tree对象描述了当前版本的目录结构,而该目录结构由一些blob对象组成,它们表示实际的文件内容。
# 对象之间的关系
一次commit对应着一个文件目录版本。一次commit会对应多个tree。一个tree相当于一个目录,tree下面也会对应多个tree或多个blob。一个blob相当于一个文件,在git中认为只要是文件内容相同,则认为是同一个blob
例如查看一个commit的详细信息:
git cat-file -p 4a4a8dea2a36bc3f476
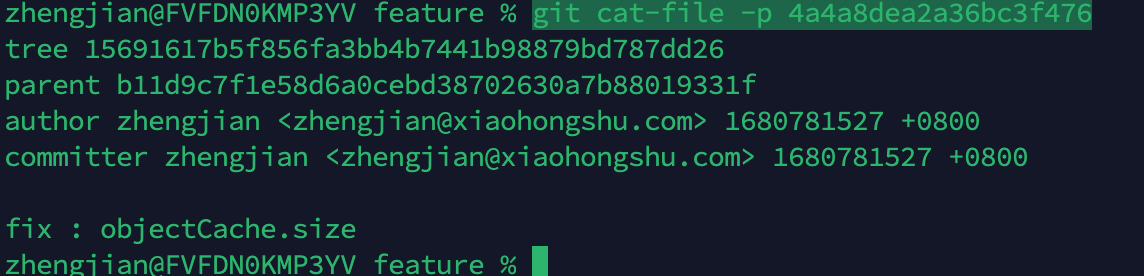
从里的tree我们都明白了,其实就是指向了一个文件。
但是这里的parent又是什么东西呢?
在 Git 中,每个提交记录都包含一个指向其父提交(或上一个提交)的指针。这些父提交可以是单个提交,也可以是多个提交,形成分支或合并历史记录。
在提交对象中,parent字段是一个指向一个或多个父提交的哈希值的列表。当创建一个新的提交时,Git 将会把当前的分支指向新的提交,同时将新的提交的 parent 字段设置为现有提交的哈希值。这样就形成了一系列有向无环图(DAG),用于表示代码库的历史版本。
tree字段则指向该提交的根目录的哈希值,表示这个提交所包含的文件和目录结构。通过跟踪 tree 和 parent 哈希值,Git 可以追溯整个代码库的历史记录,并允许用户查看先前的版本,比较更改和合并不同的历史记录。
# git对象实践
问题:新建一个git仓库,有且仅有1个commit,仅仅包含/doc/readme,请问有多少个tree,多少个blob

# 三大对象再理解
这些对象都存在.git目录中的objects中
当我们进行clone或者push时,
另外,如果更改一个文件的内容,只改变一点也会创建一个新的object,因为hash变了
# 实际操作理解对象创建过程以及关系
需要细细研究,有点东西
https://mp.weixin.qq.com/s?__biz=MzI1NDczNTAwMA==&mid=2247541766&idx=1&sn=8091a5f18aa7ede19557e2142637cf9a&chksm=e9c2c3f1deb54ae713eb48eb3e65e4a498df0ca0aca542cc4a971f261a0efe4aa79fff9e3bf9&mpshare=1&scene=23&srcid=0411xXR0BBftW5H0X098wgcm&sharer_sharetime=1681227533623&sharer_shareid=4d2ece652c18043ba9427f6fbfc02bc2#rd
首先我在创建一个结构目录如下的文件:
./git
doc
- readme.txt
2
3
其中readme.txt的文件内容如下:
hello world
现在我们将所有的文件进行提交,然后查看objects,目录下有哪些文件:

如图新增了4个文件,根据之前的学习,我们猜测目录结构如下:
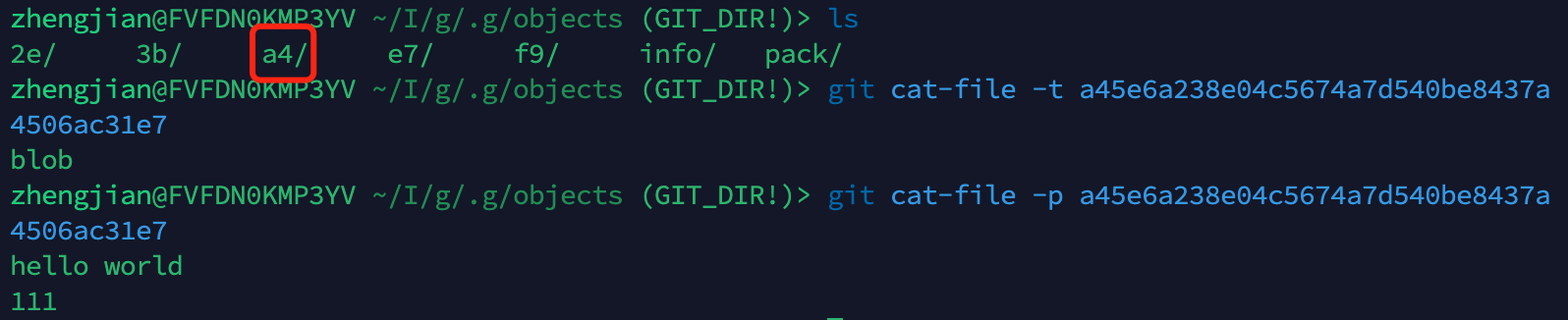
使用git cat-file -p 命令查看hash的类型进行验证
git cat-file -p 2e9e6cd9fef232a6f0ecab0523718725b5bfdb24
040000 tree e7a75e980c7adc0d5ab1c49ecff082b518bb6cf8 doc
git cat-file -p 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
hello world
git cat-file -p e7a75e980c7adc0d5ab1c49ecff082b518bb6cf8
100644 blob 3b18e512dba79e4c8300dd08aeb37f8e728b8dad readme.txt
git cat-file -p f9843075fd6e4618f4c4081bce7cc9ce99986788
tree 2e9e6cd9fef232a6f0ecab0523718725b5bfdb24
author zj<XXX@qq.com> 1681285686 +0800
committer zj<XXX@qq.com> 1681285686 +0800
commmit message
2
3
4
5
6
7
8
9
10
11
12
13
14
15
(省略了-t 查看hash类型的操作,上面查询的是hash里的具体内容)
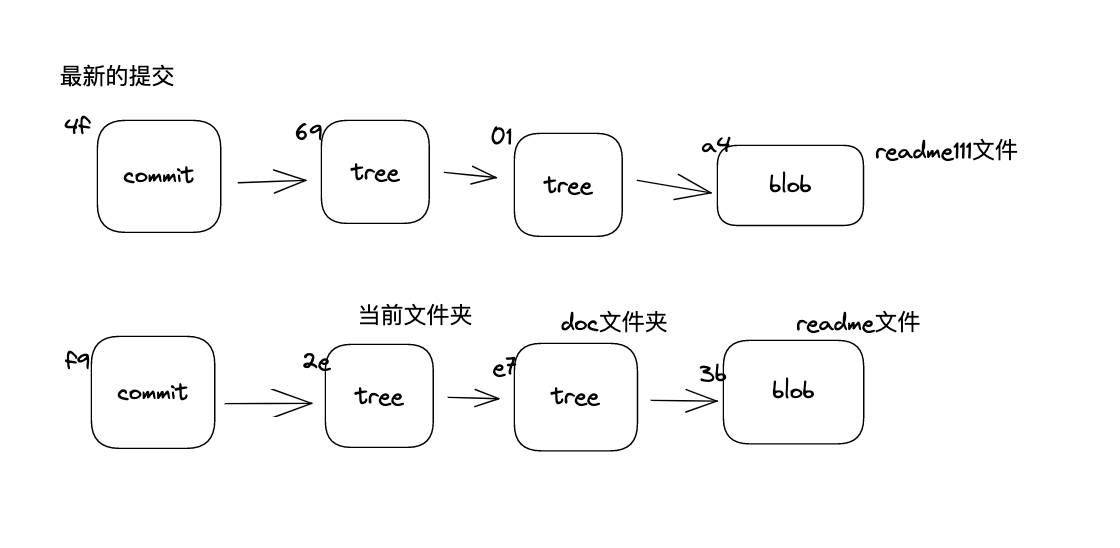
从上面这个我们就可以推测出下面的图示:

以上就是我们第一次提交的内容,我们使用git log看看:

如图,可以看出来日志内容中显示了commit对象的hash f9。
那么我们对readme文件进行修改,在最后一排添加一排111,然后进行提交到暂存区:
其实我们将文件添加到暂存区时,就已经会产生一个blob文件了,该文件就是新增了111的文件版本:
那么我们将本次进行提交呢?

其实就会发现会新增3个object,我们分别来看看每个object的内容

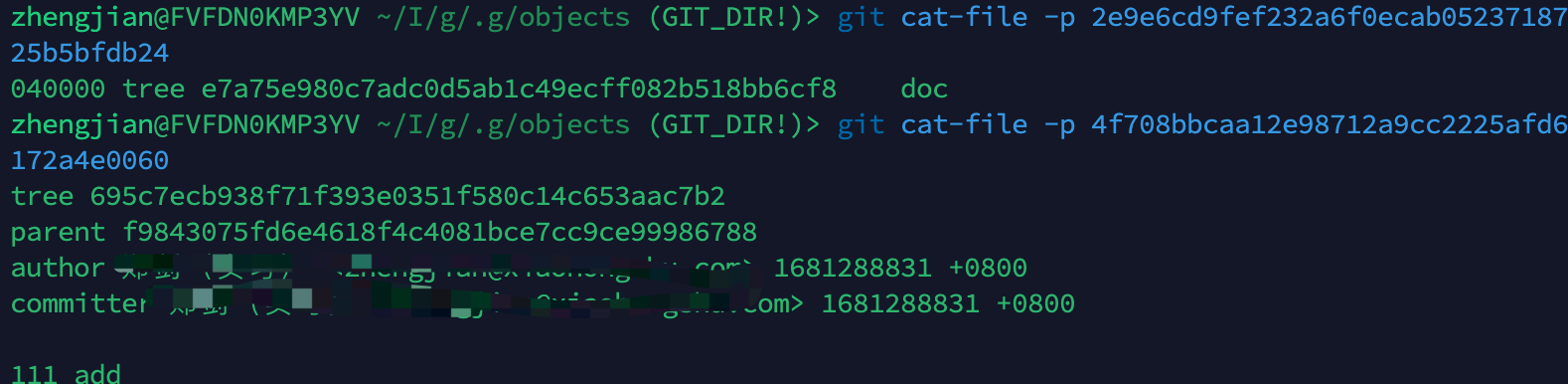

根据上面我们又可以形成新的图示
其实这么看差不多就理解了,当我们进行一次新的提交,因为应该了对应的文件readme,其会生成一个新的objectHash,而此时因为其hash变了,其当前目录为了记录历史记录,不得不生成一个新的tree来指向最新的文件,循环往复,直到最新的commit指向新建的tree。
可以得出一个结论,只要一个文件修改了,commit后,一定会产生新的commit和tree。而那些不变的文件,tree指向他们的原hash就可以。
例如我现在在doc下新建一个目录java,并在java下创建一个Main.java文件,commit后预期的结果应该如下所示:

预期会增加5个节点。我们进行实际操作看看是不是呢?
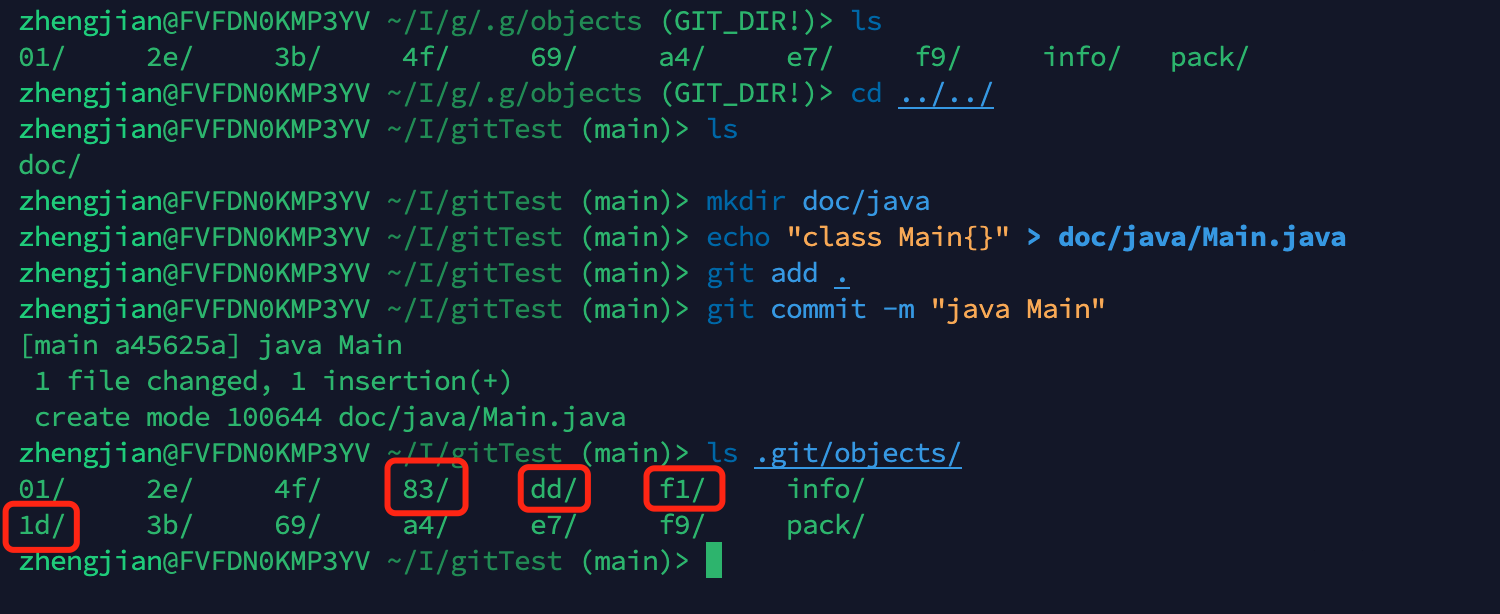
发现实际只增加了4个节点,很意外,我们看看每个hash的内容是什么

发现缺少了提交的commit,怎么回事?我们看看git log
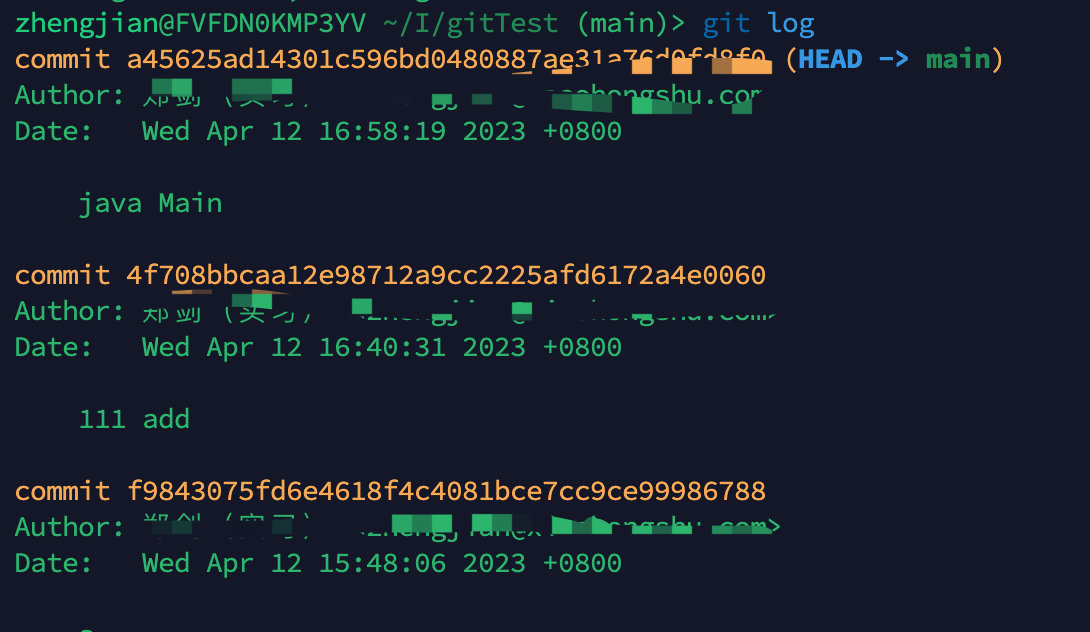
其实看到了我们最新的提交a4开头。
这下我们就知道了,在/a4下面其实有两个文件,我们没有注意


这下就符合预期了,生成了5个节点是正确的。

# git gc
我们试试一个新的命令:git gc
此时我们在objects目录下看看,我们的hash不在了

其实我们的东西跑到pack里面去了

怎么查看pack的内容:
执行 git verify-pack -v 看下 idx 文件的内容:
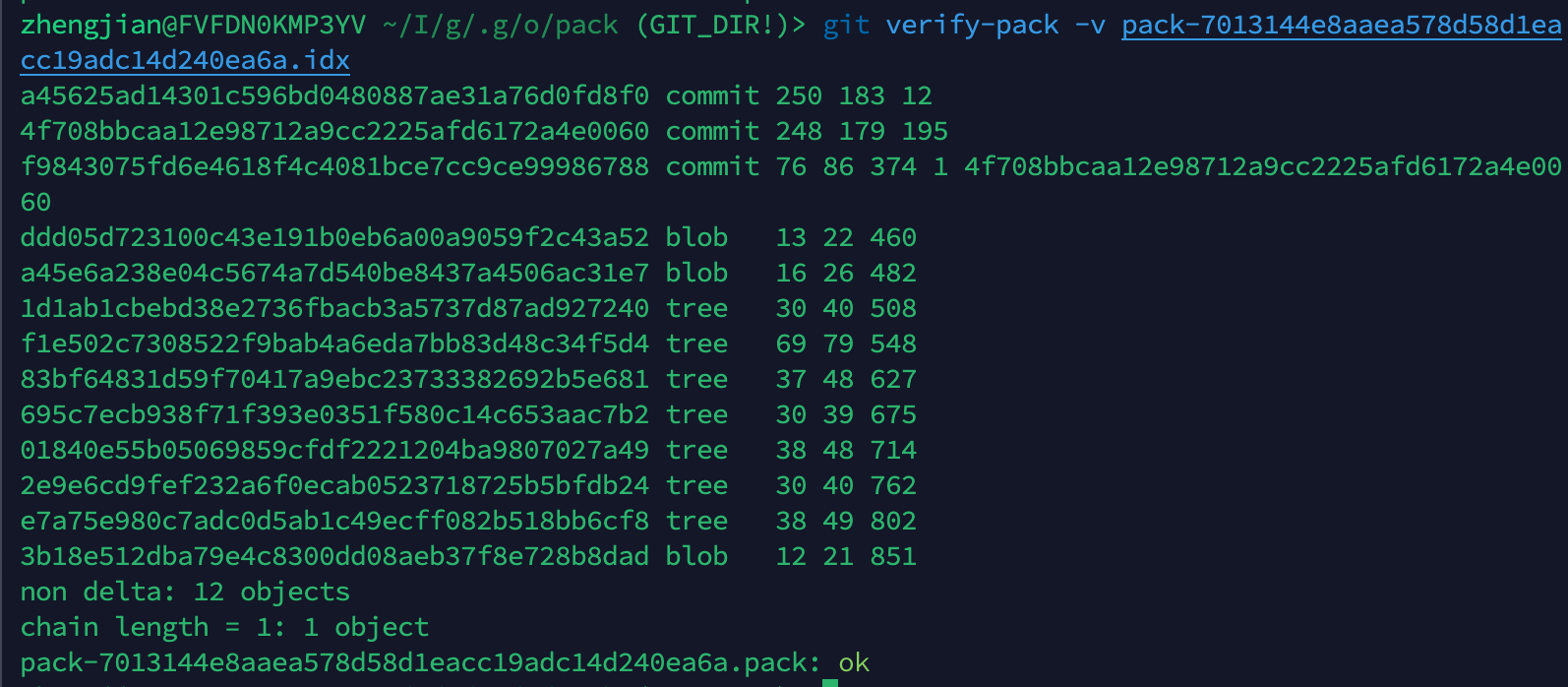
可以看到,我们所有的hash都压缩到这里了
//TODO : 后面跟着一长串的东西是什么 chain
我们使用git gc时候,是不是和我们进行push时很相似,这一看就明白了:每次push时,其实会将我们本地在object中hash进行gc打包到pack中,下次我们clone下来时,服务端也会进行gc后再传输
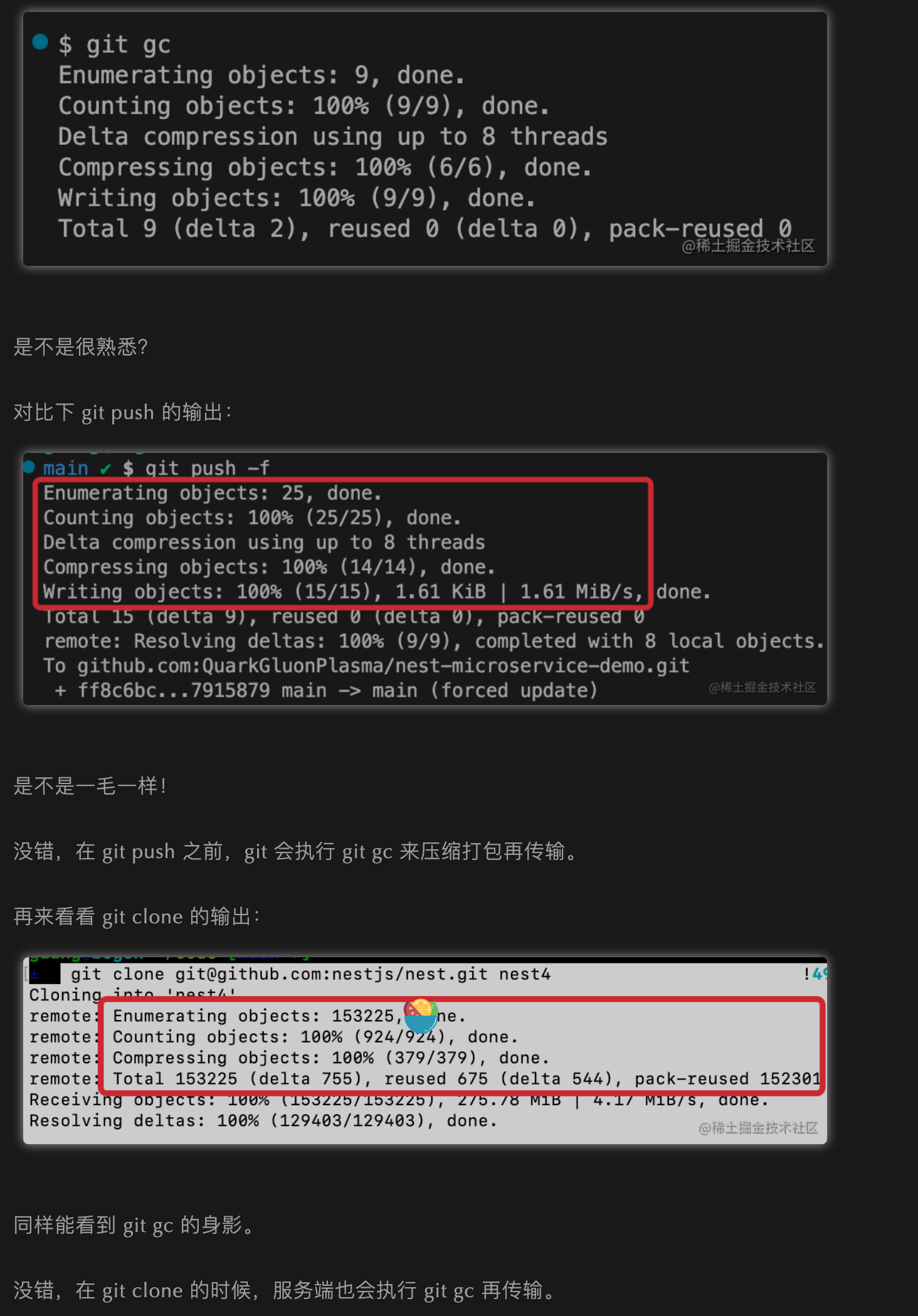
也就是说gc会对objects中的对象进行压缩。
在远程仓库中一般不会存储.git目录:
.git 目录是 Git 用来存储仓库的版本历史和元数据的目录,包含了 Git 所需的所有信息。该目录通常位于仓库的根目录中,但它被设计为隐藏目录,因此默认情况下不会在文件浏览器或终端窗口中显示。
虽然你可以在本地访问 .git 目录,但 GitHub 不会公开任何仓库的 .git 目录或其内容。GitHub 提供了 Git 命令行工具、API 和 Web 界面等多种途径来管理仓库和进行版本控制。
git gc 主要有以下作用:
- 清理无用的对象。Git 会自动引用(reference)一些对象,例如最新的提交对象和分支头等,但是有些对象可能已经不再被引用,也就是所谓的无用对象。
git gc可以帮助我们找到并删除这些无用的对象,从而释放磁盘空间。 - 压缩对象。Git 中的对象通常以松散格式存储,这样可以方便地添加和修改,但同时会占用更多的磁盘空间和读写时间。
git gc可以把松散格式对象压缩成紧凑格式,从而进一步减少磁盘占用,并提高读写性能。 - 优化仓库。
git gc还会执行其他一些优化操作,例如压缩历史记录、删除冗余数据等,从而提高 Git 仓库的整体性能。
需要注意的是,git gc 命令可能需要一些时间来完成,特别是对于大型仓库来说。此外,建议不要频繁地手动执行 git gc,因为这可能会影响你的工作流程和 Git 的性能。通常情况下,我们可以让 Git 在满足一定条件时自动运行 git gc。
# 分离头指针
什么是git中的分离头指针:

HEAD detached at hash
Git的分离头指针(Detached HEAD)是指当前工作树(Working Tree)处于HEAD指针指向的提交(Commit)之外的一种状态。在分离头指针状态下,Git不再跟踪分支(Branch)而是直接跟踪提交。
使用git checkout <commit>命令切换到一个特定的提交时,就会进入分离头指针状态。这种情况通常发生在以下几种情况:
- 执行
git checkout <tag>或git checkout <commit hash>等命令,但未创建新的分支来跟踪这个提交; - 在某个分支上进行修改,但在提交这些修改前执行了
git checkout <commit>命令。
如果在分离头指针状态下进行修改并提交,那么这些提交将会成为孤立的提交(Orphan Commits),也就是没有任何分支指向的提交。
# 怎么产生?
git checkout commitHash
这时就产生了分离头指针,改指针并没有与任何的分支进行关联,当然我们可以在这里进行提交,但是因为没有任何分支进行关联,当我们突然切换到另一个分支过后,分离头指针上提交的commit就会丢失
那么分离头指针就完全没有用了吗?
分离头指针的优点是:
- 可以方便地查看、修改、测试历史提交,无需创建新的分支或拉取代码;
- 可以快速切换到不同的提交和版本,方便进行版本回退;
- 可以在不影响当前分支的情况下修改和提交代码。
分离头指针的缺点是:
- 在分离头指针状态下进行修改并提交,这些提交将成为孤立的提交,没有任何分支指向它们,可能会导致难以维护的仓库历史;
- 分离头指针状态下,无法使用
git pull等命令自动获取最新的远程更新; - 当需要继续开发时,需要创建新的分支来跟踪当前的工作,否则会丢失之前的提交记录。
因此,在实际应用中,建议尽量避免使用分离头指针状态,只有在特殊情况下才使用。
# HEAD与Branch
正常情况下HEAD中保存的数据是一个地址的引用。
从目录的ref来看,其实真实指向的是一个commit,所以最总一个head不是指向多个commit,而是指向一个具体的commit。而这个commit有父亲节点可以访问,就间接的包含了多个commit
既然HEAD和branch本质上都指向了commit,其实我们的所有操作基本上都是基于commit进行操作,比如对比两侧commit的差异:
git diff commit1 commit2
git diff HEAD HEAD^
Git diff HEAD HEAD^^
git diff HEAD HEAD~2
# git的作用域
git config 可以用来配置 Git 客户端的行为和属性。其作用域可以分为三种:
- local:只对某个特定的仓库有效,设置在当前仓库的 .git/config 文件中。
- global:对当前用户的所有仓库都有效,存储在当前用户根目录下的 .gitconfig 文件中。
- system:对系统上所有登录用户的所有仓库都有效,通常存储在 /etc/gitconfig 文件中。
当同一个属性在多个配置文件中都有定义时,Git 会按照 local、global、system 的优先级依次查找并采用最后一个定义的值。
其中优先级别 local > global > system
# Git别名
推荐日志别名:
[alias]
lg = log --color --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit
dog = log --all --decorate --oneline --graph
2
3
- 设置
git命令别名
git config <作用域> alias.<别名> '<命令>'
git config --global alias.dog 'log --all --decorate --oneline --graph'
对应的信息会写入到对应作用域的配置文件里面
- 设置外部命令别名
像gitk这样的外部命令,是没有git前缀的。设置别名的方法与设置git提供的命令有所不同,要按照如下格式设置:
git config <作用域> alias.<别名> '<!外部命令>'
- 感叹号表示这是一个外部命令;
- 注意要加上单引号,不用加
git前缀;
比如在系统用户作用域下,将git ui设置为gitk的别名:
git config --global alias.ui '!gitk'
设置完成后,该配置会被写入系统用户的配置文件gitconfig中
设置了别名后,原来的命令依然有效
# git revert
其实revert 和reset的功能类似,都是撤销某次的commit。
但是两者有本质上的区别。
git reset是直接从分支上回退到对应的commit节点,如图:
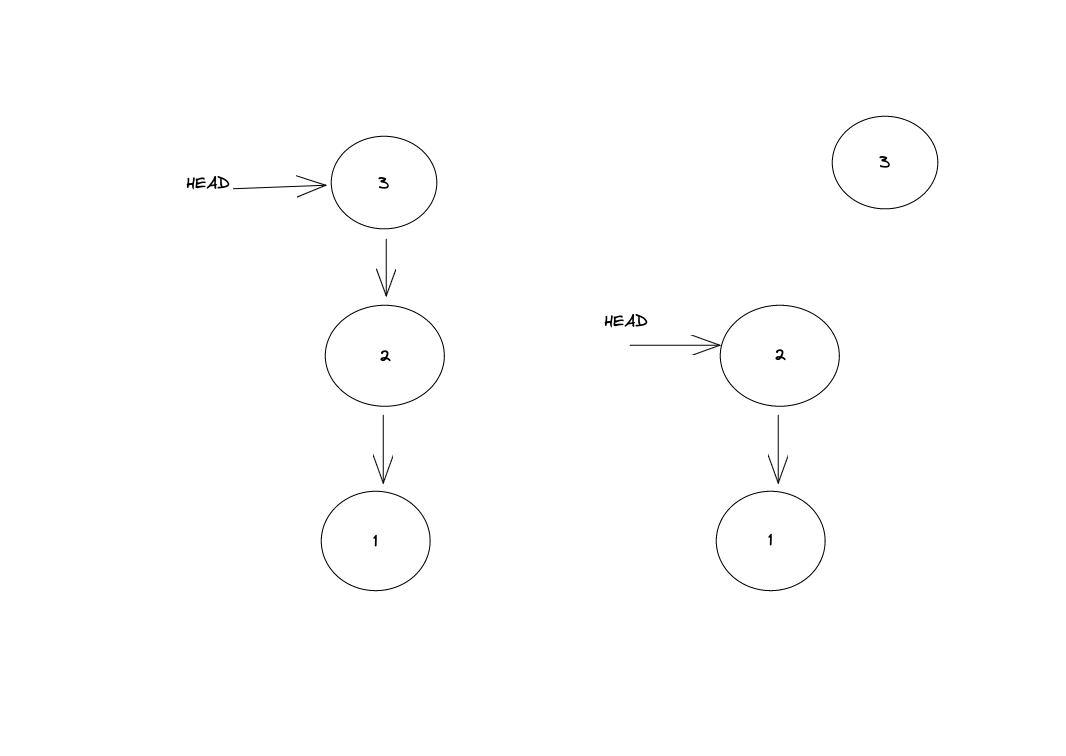
如图所示,当前HEAD指向3,如果我使用reset命令,会将HEAD指向2,commit3会断掉与2的关系。如果我们使用的是revert的话,其实其作用就是创建一个新的提交,新的提交中就做了相应的修改操作对应撤销操作,如图:
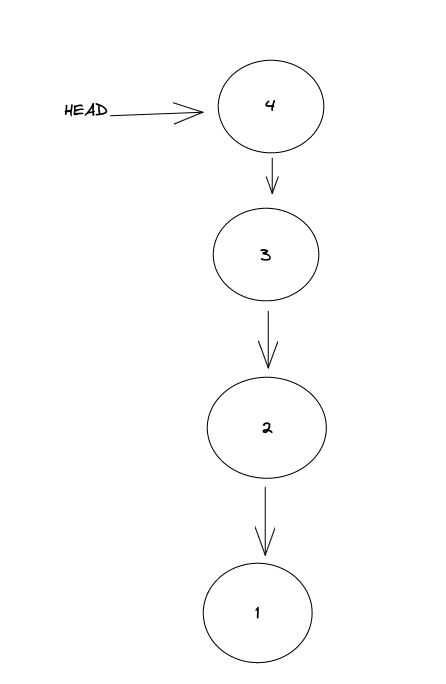
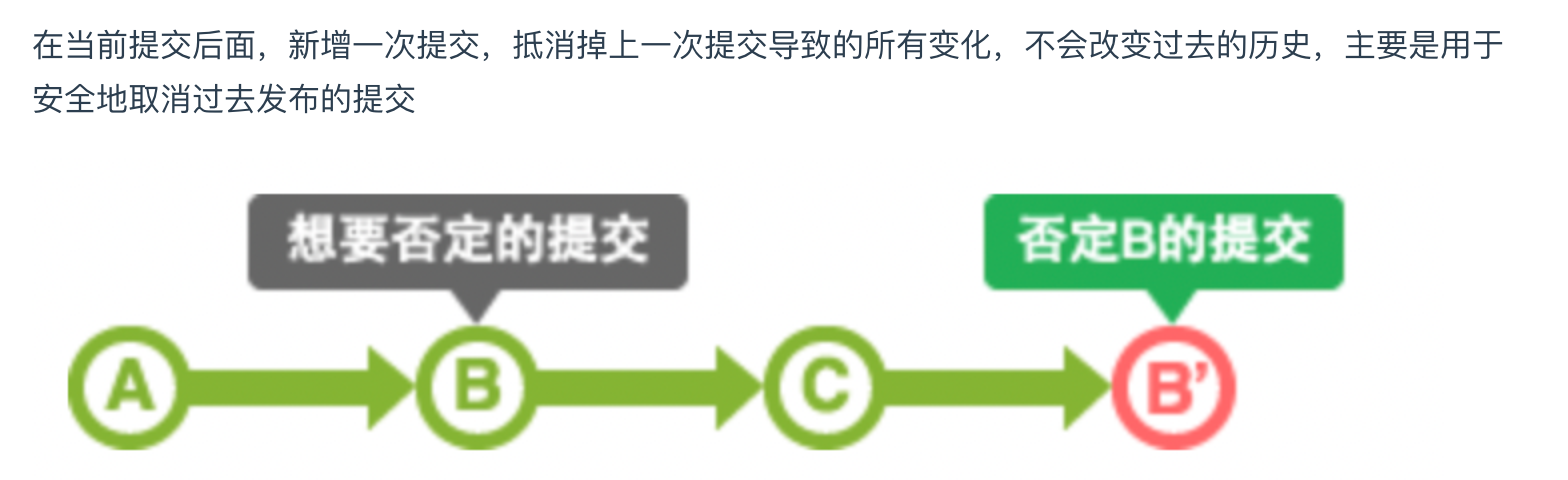
如何使用?
用法跟git reset一致
# 两者区别
撤销(revert)被设计为撤销公开的提交(比如已经push)的安全方式,git reset被设计为重设本地更改
因为两个命令的目的不同,它们的实现也不一样:重设完全地移除了一堆更改,而撤销保留了原来的更改,用一个新的提交来实现撤销
两者主要区别如下:
- git revert是用一次新的commit来回滚之前的commit,git reset是直接删除指定的commit
- git reset 是把HEAD向后移动了一下,而git revert是HEAD继续前进,只是新的commit的内容和要revert的内容正好相反,能够抵消要被revert的内容
- 在回滚这一操作上看,效果差不多。但是在日后继续 merge 以前的老版本时有区别
git revert是用一次逆向的commit“中和”之前的提交,因此日后合并老的branch时,之前提交合并的代码仍然存在,导致不能够重新合并
但是git reset是之间把某些commit在某个branch上删除,因而和老的branch再次merge时,这些被回滚的commit应该还会被引入
- 如果回退分支的代码以后还需要的情况则使用
git revert, 如果分支是提错了没用的并且不想让别人发现这些错误代码,则使用git reset
# git rebase 与git mergae有什么区别
https://vue3js.cn/interview/git/git%20rebase_%20git%20merge.html (opens new window)