
 尚硅谷k8s
尚硅谷k8s
# 背景
基础设施即服务
平台即服务
软件设施即服务
问题:
在最老的未服务架构中,我们一台机器部署一个应用,每个机器之间通过地址端口就可以进行通信。
但是当我们使用容器技术时,每个容器中的端口需要映射到机器的实际端口,这种端口映射在服务很多后就很难管理,这时候我们就需要一种很好的管理工具。
解决方案:
- 资源管理器 MESOS
2019 推特由MESOS转向k8s
- docker SWARM
缺点:不能进行回滚等功能
2019 阿里云不再使用
- kubernetes
google、go语言编写
特点:
轻量级:消耗的资源少
# 介绍说明
# 前生今世
# 组件框架
# borg
了解组件的前提,先了解borg的架构
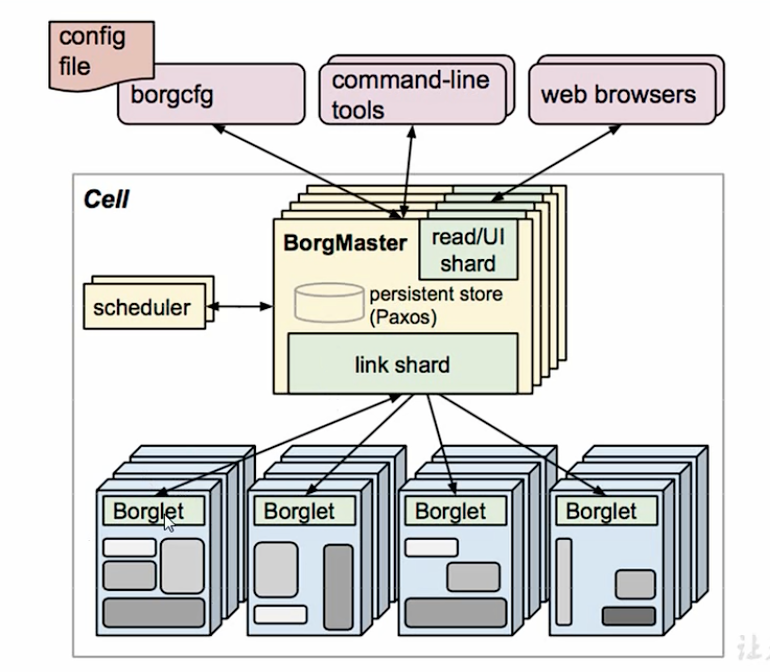
- borgmaster
首先borgMaster主要用作流量的分发,可以处理当一个请求过来了,相应的流量可以打到哪个borglet地方。
- borglet
每一个具体的服务对应的节点,可能对应着一个服务
- 访问方式
borgmaster有3种访问方式
- 命令行
- 浏览器
- 文件
Schedule
调度器。决定调度的顺序。会将相应的调度保存到数据库paxos,然后borglet定时去数据库拉取数据。
# kebernates
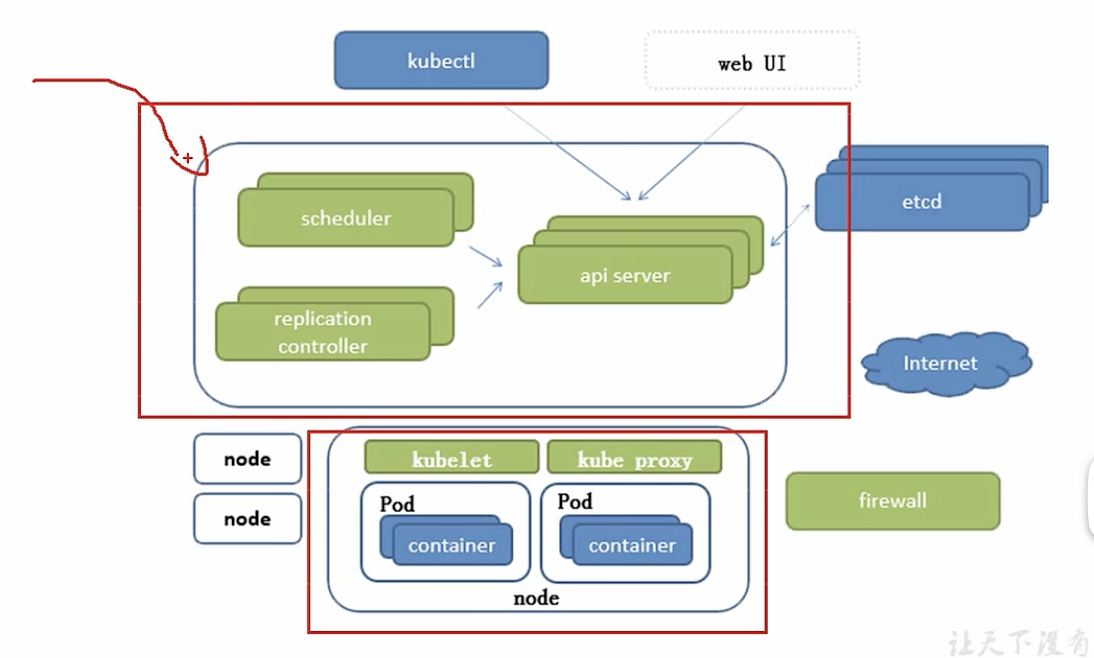
- api server
所有服务访问的入口
- scheduel
负责接收任务,选择合适的节点进行分配任务
- 控制器ControllerManager
维护副本期望的数目,一个node可以设置一个期望的副本数目。
副本数量最好为>=3的基数个
- etcd
存储k8s所有重要信息(持久化)
一个可信耐的分布式键值存储服务,它能为整个分布式集群存储一些关键数据,协助分布式集群的正常运转。
分为两种版本:memery和database
注意:kubuernates v1.11后etcd ,memery已经被弃用
etcd架构图:
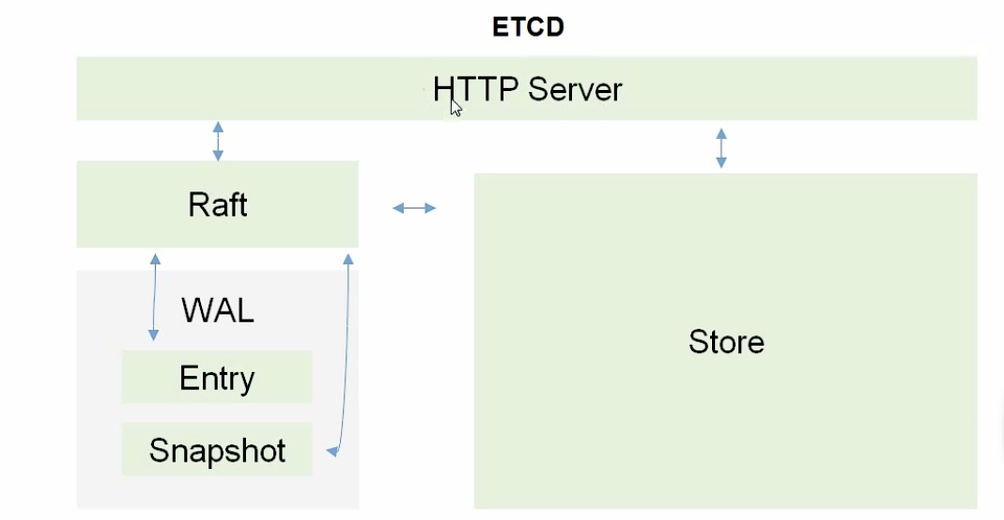
类比mysql,预写日志。
- kubelet
直接跟容器引擎交互实现容器的生命周期管理
- kubeproxy
负责写入规则至IPTAVLES、IPVS实现服务的映射
# 其他重要的组件
- coreDNS(重要)
可以为集群中的SVC创建一个域名的对应关系解析
- dashboard
给k8s提供b/s结构访问体系
- ingress controller
官方只能实现4层代理,ingress可以实现7层代理
- fedetation:提供一个可以夸集群中心多k8s统一管理的功能
- prometheus
提供一个k8s集群的监控能力
- ELK
提供k8s日志统一接入平台
# 关键字
# 基础概念
# pod概念
管理的最小单位
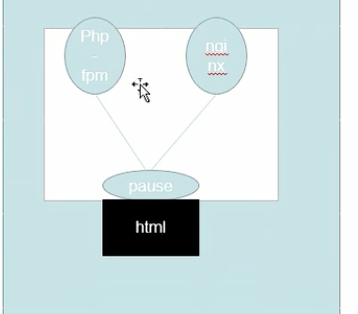
概念:一个pod中,可能存在多个容器。启动一个pod,必须先要启动一个pause容器,然后再启动其他的容器A、B。启动后AB网络共享、存储卷共享,即AB两者采用映射的方式都使用的是pause的网络和存储。
- 自主式 Pod
# 管理器
# 什么是管理器
K8S是容器 (opens new window)资源管理和调度平台,容器跑在Pod里,Pod是K8S里最小的单元。所以,这些Pod作为一个个单元我们肯定需要去操作它的状态和生命周期。那么如何操作?这里就需要用到控制器了。
这里一个比较通俗的公式:应用APP = 网络 + 载体 + 存储
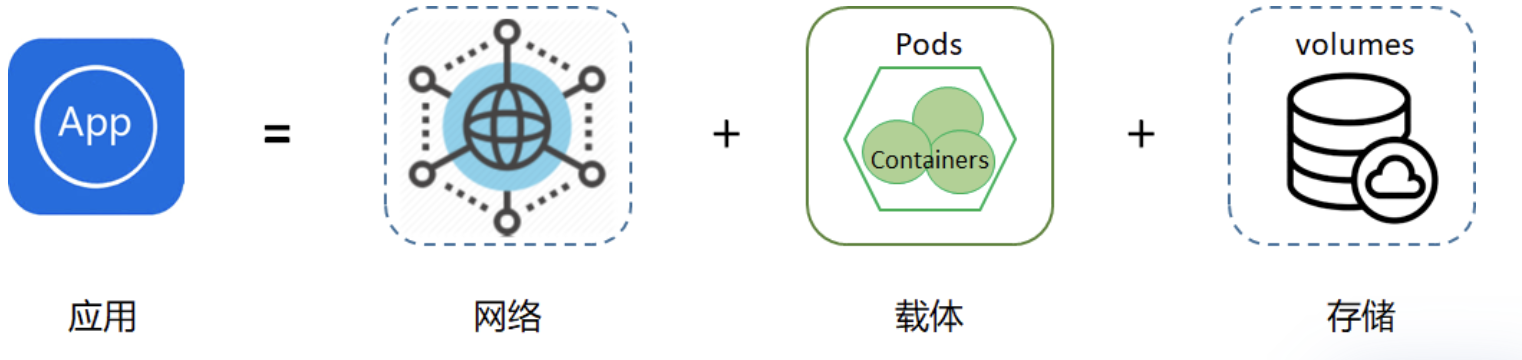
这里应用一般分为无状态应用、有状态应用、守护型应用、批处理应用这四种。
无状态应用
应用实例不涉及事务交互,不产生持久化数据存储 (opens new window)在本地,并且多个应用实例对于同一个请求响应的结果是完全一致的。举例:nginx或者tomcat
有状态应用
有状态服务可以说是需要数据存储功能的服务或者指多线程类型的服务、队列等。举例:mysql数据库 (opens new window)、kafka、redis、zookeeper等。
守护型应用
类似守护进程一样,长期保持运行,监听持续的提供服务。举例:ceph、logstash、fluentd等。
批处理应用
工作任务型的服务,通常是一次性的。举例:运行一个批量改文件夹名字的脚本。
这些类型的应用服务如果是安装在传统的物理机或者虚拟机上,那么我们一般会通过人肉方式或者自动化工具的方式去管理编排。但是这些服务一旦容器化了跑在了Pod里,那么就应该按照K8S的控制方式来管理了。上一篇文章我们讲到了编排,那么K8S靠什么具体的操作来做编排?答案就是这些控制器。
不会被管理器管理,死亡后不会复活
- 控制器管理的Pod
# rc、rs、dy
pod管理器

rs在大型项目中可以过滤标签进行管理,新版本已经抛弃了RC
deployment支持滚动更新:创建一个新的,删除一个旧的,进行滚动的更新。即当我们要更新一个pod时,会先删除一个新的,再删除一个旧的,这样可以让更新更加平滑。但是deployment并不支持pod的创建。
- deployment创建流程
dy创建后,会由dy自己创建一个rs,rs会创建对应的pod。
- 更新流程
因为采用的是滚动更新,此时dy会创建一个新的rs-1,然后进行滚动更新流程,rs-1更新的一个,rs中的pod停用一个,以此类推。更新完成后rs不会被删除而是停用
- 回滚
因为之前的rs并没有被删除,所以可以支持回滚
HPA (HorizontalPodAutoScale)
仅适用于deployment和replicaSet,在V1版本中仅支持根据pod的cpu利用率扩容,在vlapha版本中,支持根据内容和自定义用户的metric扩容
解释:HPA会根据dy或rs中的pod的cpu利用率来创建新的pod或者回收pod。即可以根据节点性能自动创建或删除pod
# statefullSet

docker是无状态的服务,而k8s是有状态的服务
有序删除:比如一个服务中,需要按照流程顺序启动mysql、apache、nginx等,如果顺序乱了,可能会报错
# daemonSet

不懂 TODO
# JOB、CronJob
# 扩展
# CloneSet
扩展了deployment

# 通讯模式
pod与pod之间的通讯
# 服务发现
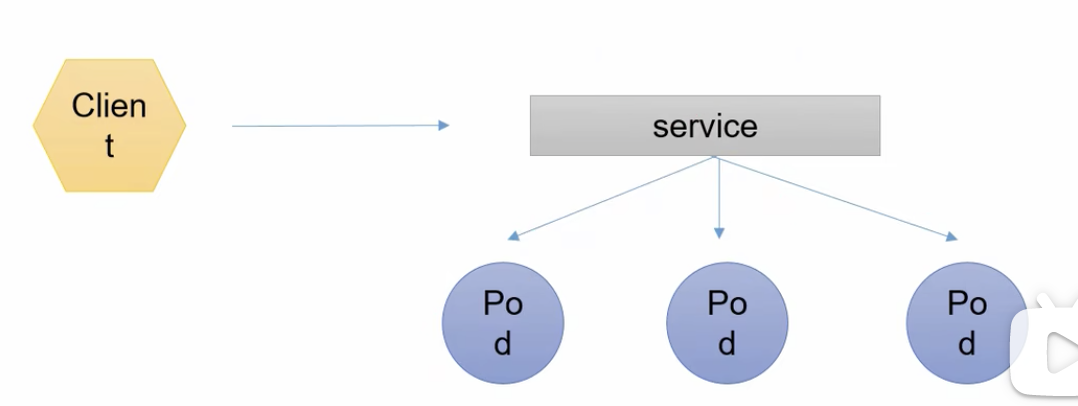
service可以通过管理器去发现一组pod,service有一个地址和端口,这样client就可以访问service,service再通过负载均衡访问到pod
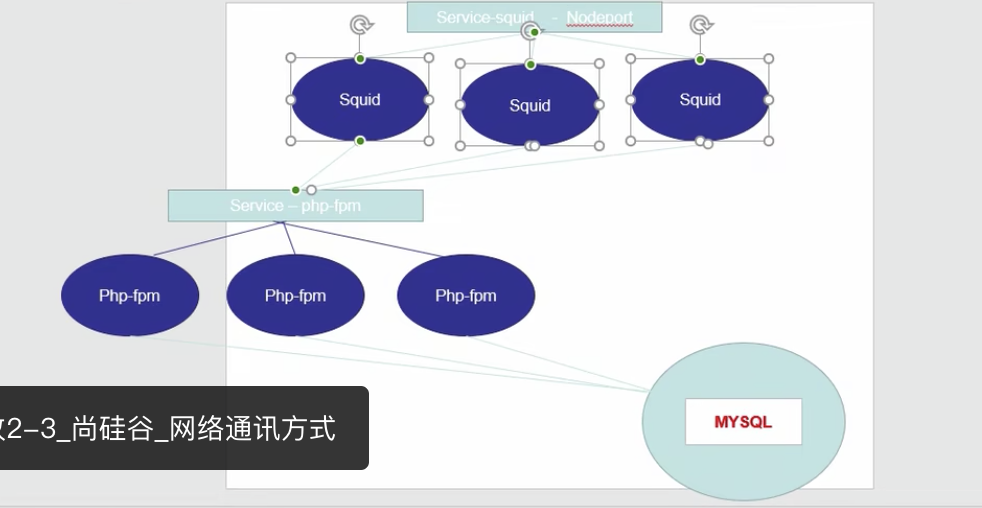
比如我们创建了3个php-fpm,他们处于平行的服务,squid要调用它,如果在squid中写死了php-fpm的
# 网络模型


overlay network 怎么去实现?
Flannel :功能是让集群中的不同的节点主机创建docker容器具有全集群唯一的虚拟ip地址。而且它还能在这些ip地址之间建立一个覆盖网络,通过这个覆盖网络,将数据包原封不动地传递到目标容器内
案例:
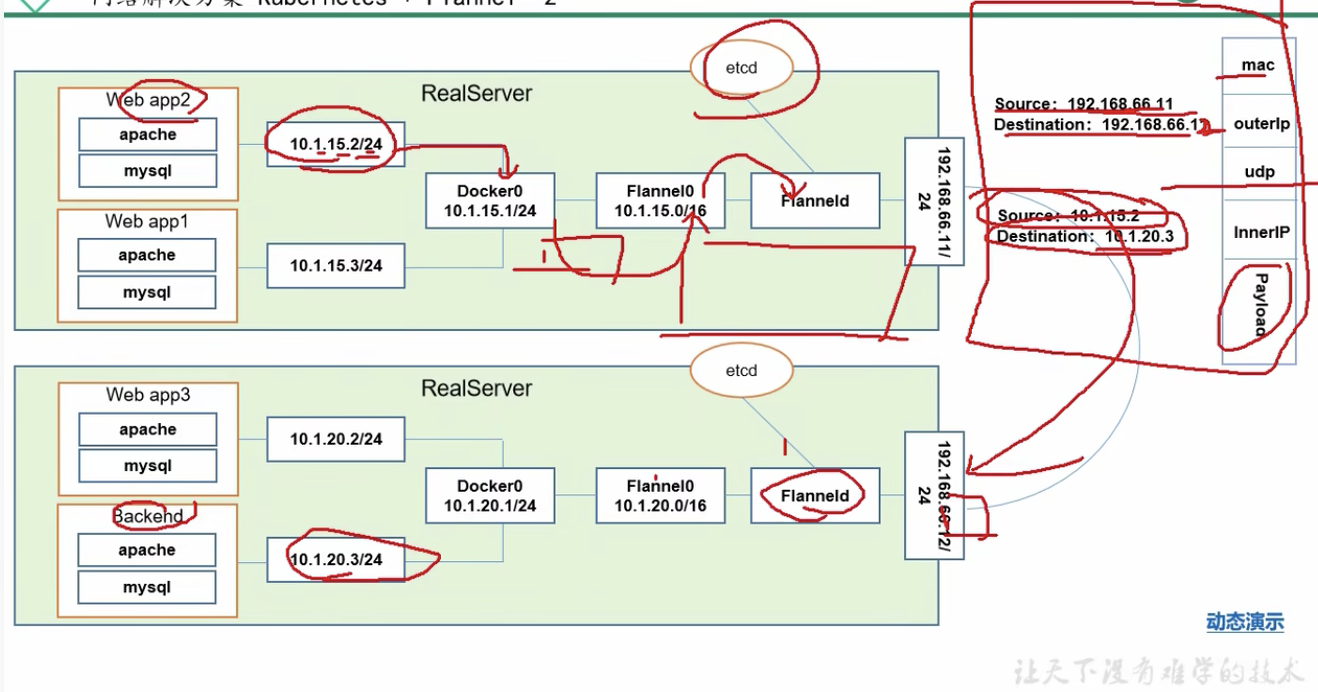
- 解释
想象一下,backend后台需要调用app1、app2、app3,现在app2向backend发送数据包,app2节点表示的ip会发送至docker0,docker0再到网桥flannel0,再到flanneld,flanneld会在etcd中查看相关的地址映射信息,并组装成相应的数据包,通过udp的方式转发给其他的主机中对应的pod节点。

iptables与lvs
ETCD非常重要:
存储管理Flannel可分配的IP地址段资源
监控ETCD中每个POD的实际地址,并在内存中建立维护POD节点路由表
如果要考虑高可用,第一个应该考虑的就应该是ETCD的高可用
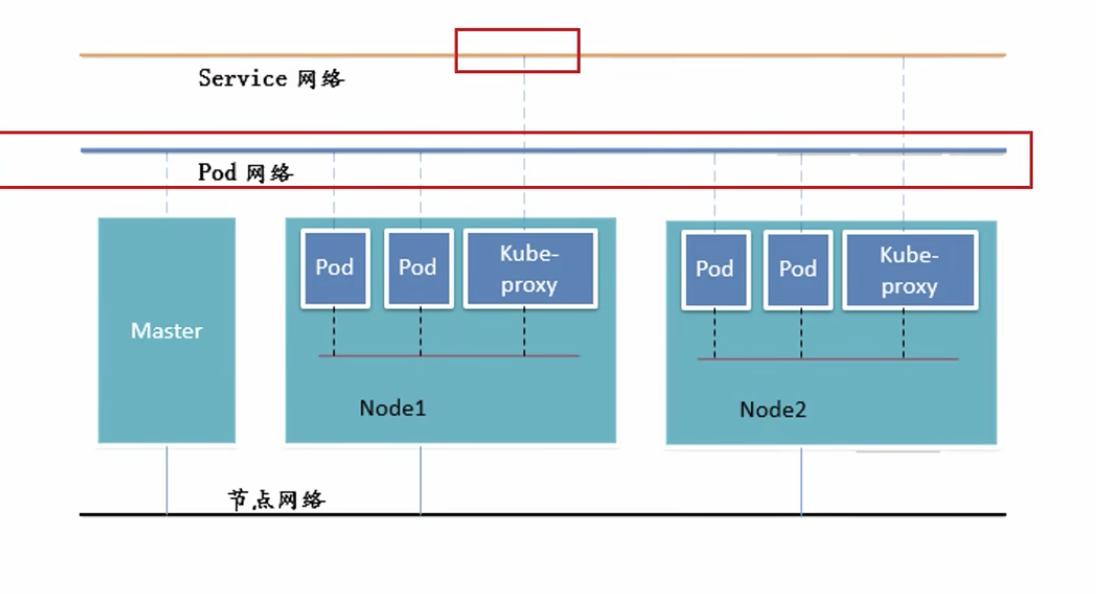
节点网络即是我们物理机的网络,是真实的网络,其中service网络和pod网络都是虚拟的网络
# kubernates
# 安装
- minikube
首先进行Minikube的安装
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-darwin-amd64
sudo install minikube-darwin-amd64 /usr/local/bin/minikube
2
Kubeadm
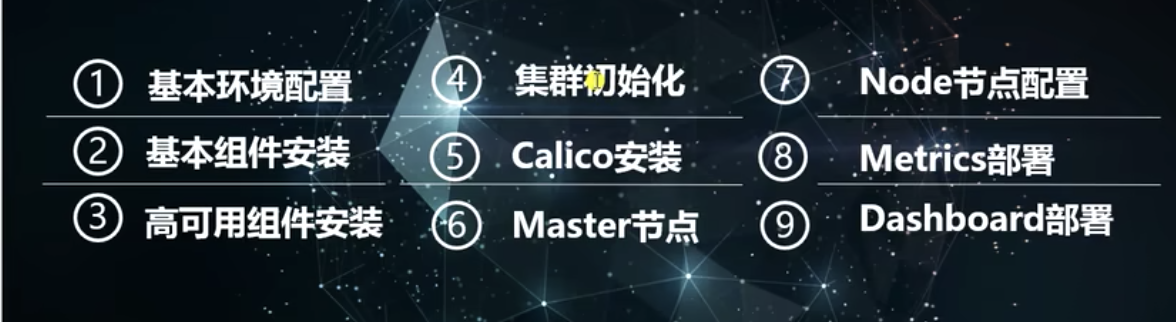
# 自行构建集群
# 资源清单
# k8s中的资源
k8s所有内容都被抽象为资源,资源实例化后都叫做对象
- 名称空间
仅在此名称空间下生效

- 集群
全局都可见
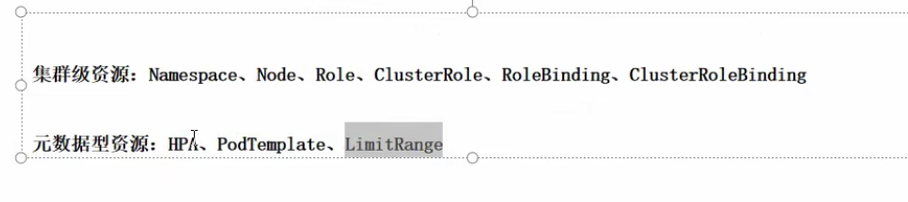
- 元数据
# 语法 资源清单
必须存在的字段

非必需
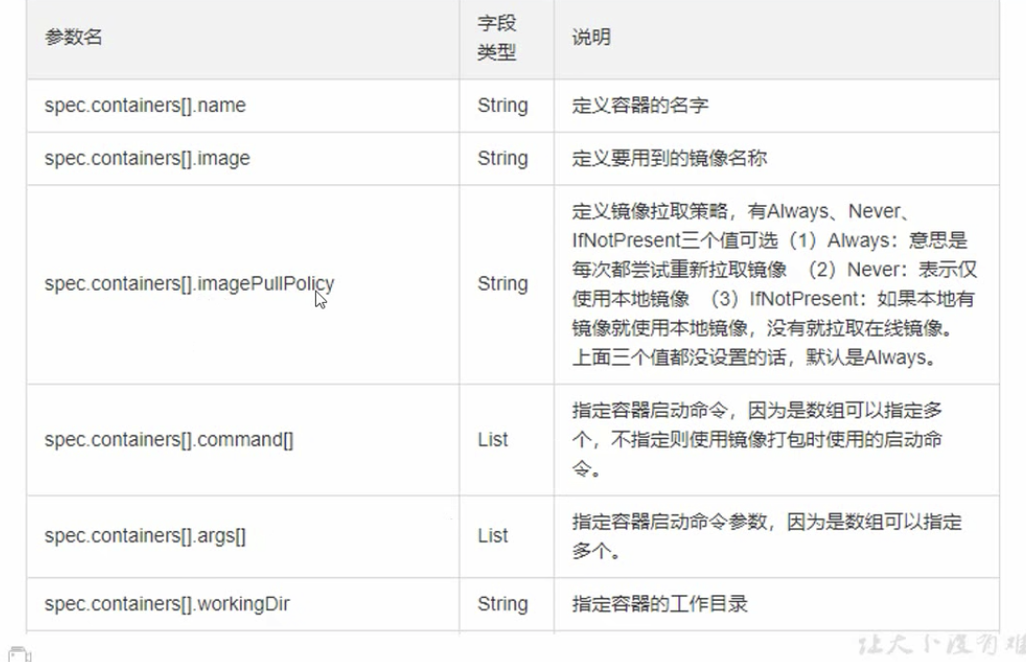

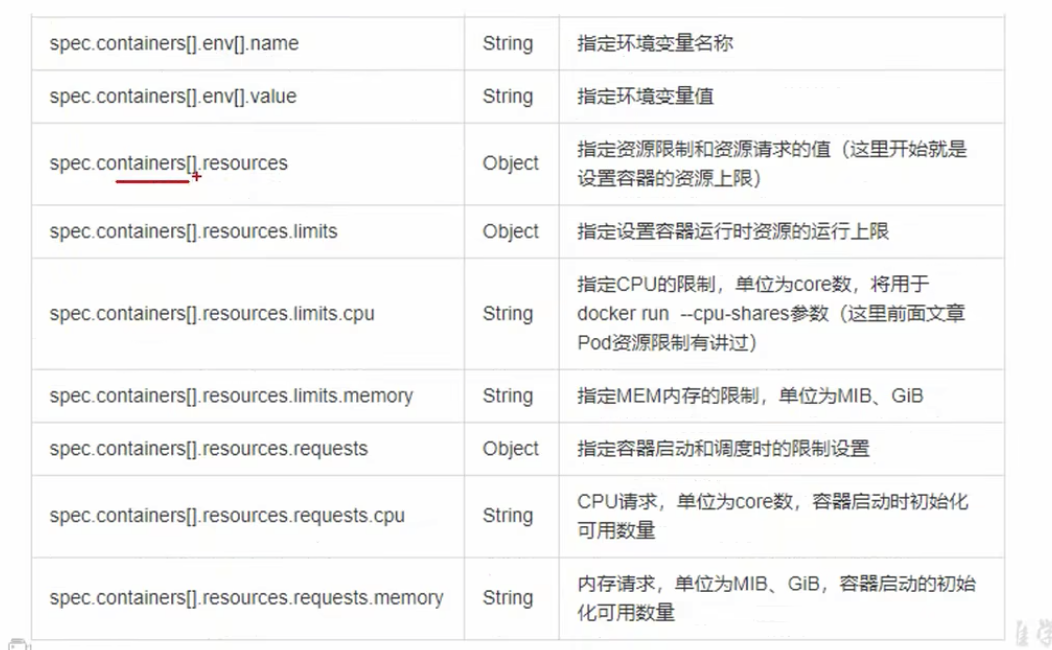
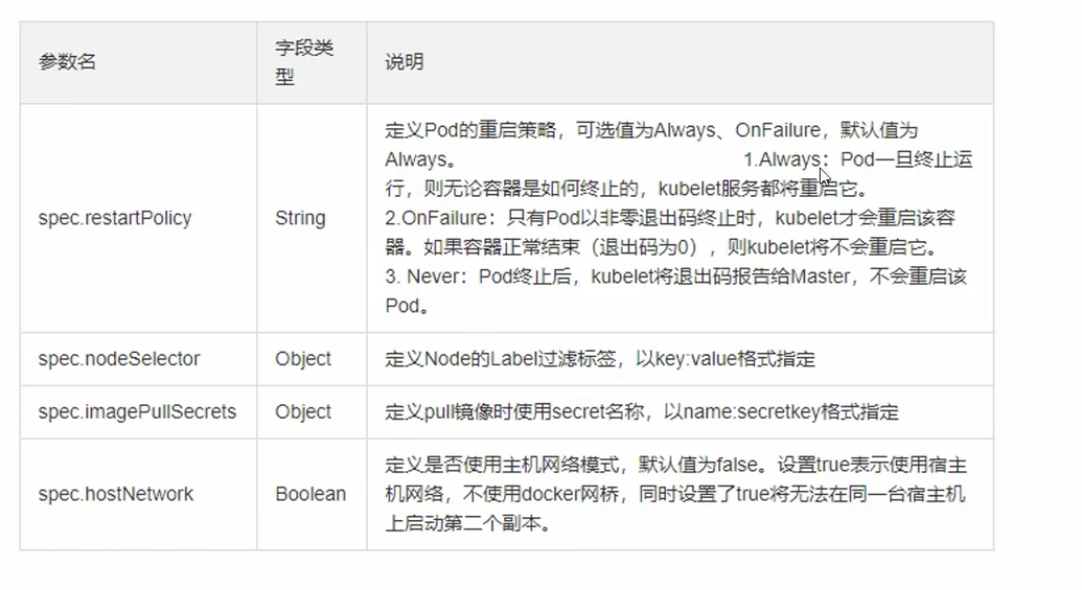
如何看更详细的信息?
kubectl explain pod
kubectl explain pod.spec
2
# 编写资源清单
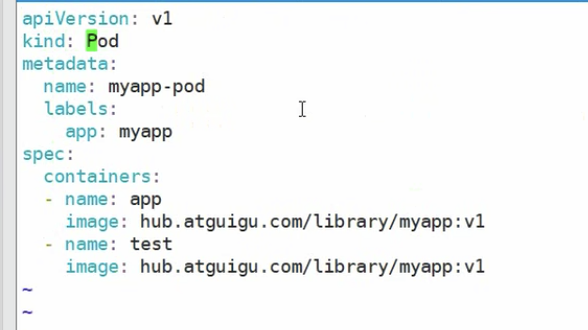
启动对应的资源清单
kubectl apply -f xx.yaml
查看Pod状态
kubectl get pod
查看日志
//查看哪个容器有问题
kubectl describe pod xxxName
kubectl logs xxxName -c test//查看pod下的指定容器的日志
2
3
4
# pod生命周期(重难点)
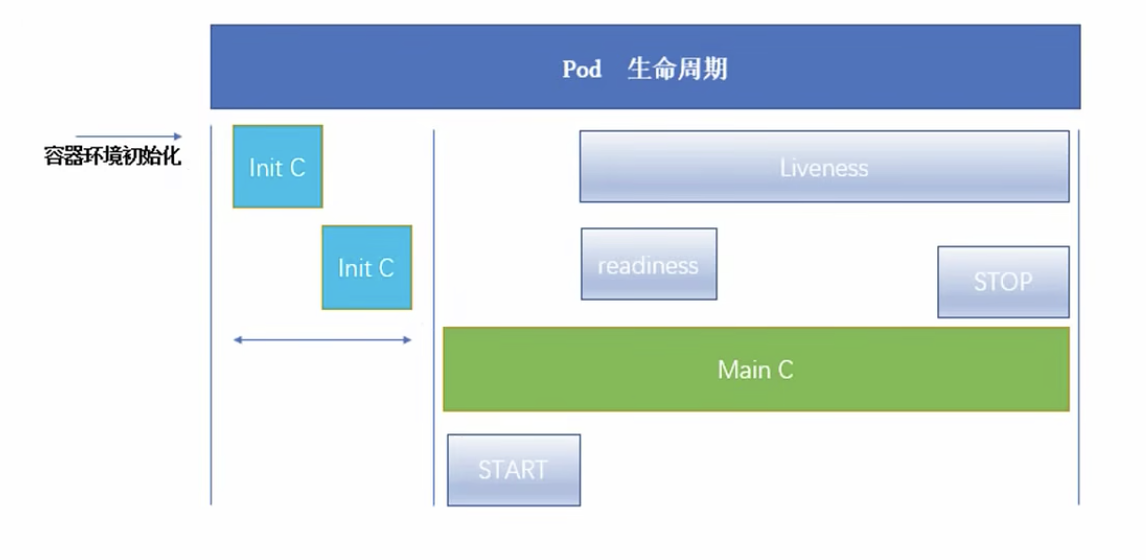

成功:返回0,就表示成功返回。返回其他数据,就表示失败了。
# 容器环境初始化
# init
初始化容器(不能并行,必须串行,包括pause容器)
介绍:pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先应用容器启动的Init容器。
Init容器与普通的容器非常像,除了:
Init容器总是运行到成功为止
每个init容器必须在下一个init容器启动之前完成
如果pod的Init容器失败,kubernetes会不断地重启该pod,直到Init容器成功为止,然而,如果pod对应的restartPolicy为nerver,则它不会重新启动
作用:

举例:

比如我们有两个pod:mysql(pod1)、Apache+php(pod2)。
此时pod2需要调用pod1服务,如果pod1还没有成功启动,那么pod2就会调用失败。那我们要怎么做到pod2调用pod1之前,保证pod1已经启动成功呢?
可以在pod2之前加一个init容器,让其去监控pod1是否成功启动,只有当成功启动过后,pod2才开始启动
编写init模板:
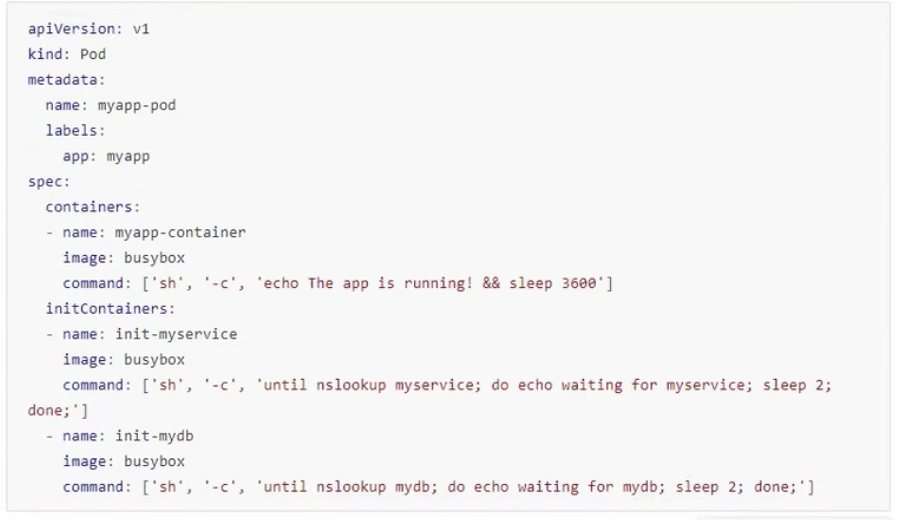
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh','-c','echo the app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox
command: ['sh','-c','until nslookup myservice; do echo waiting for myservice; sleep2; done;']
- name: init-mydb
image: busybox
command: ['sh','-c','until nslookup mydb; do echo waiting for mydb; sleep 2;done;']
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
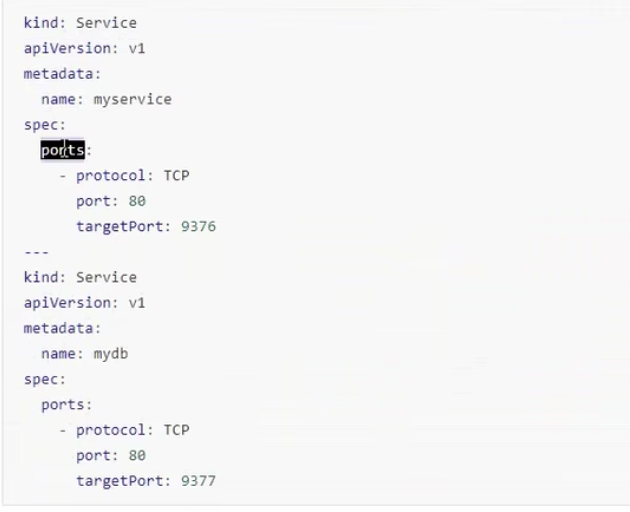
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 8377
2
3
4
5
6
7
8
9
kind: Service
apiVersion: v1
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
2
3
4
5
6
7
8
9
10
上面可知,当主main启动后,需要等待出初始化容器myservice、mydb执行完成后,才能真正进行main容器的执行
kind: service?
https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/ (opens new window)
注意事项:
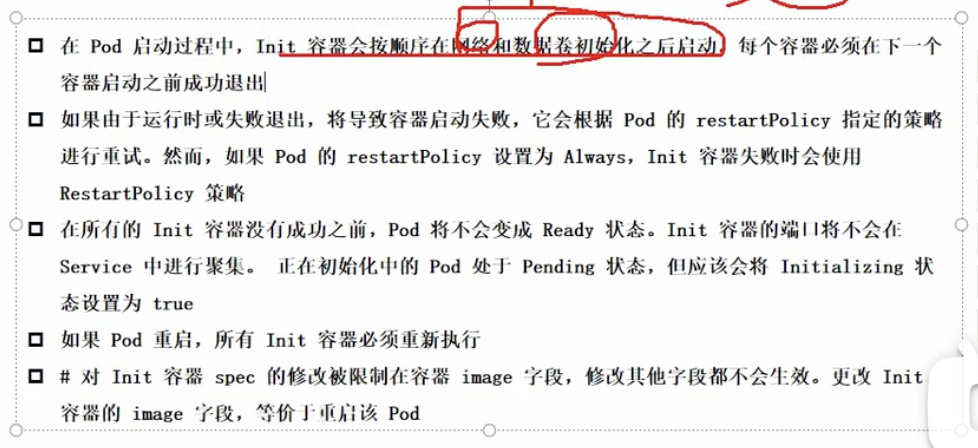
网路和数据初始化是在pause容器中完成的。
使用命令
kubectl edit pod podName
可以修改对应的yaml文件,如果修改了image字段相关的数据,会触发init容器的重新启动,也就表示整个pod都会进行重启。

init容器的资源清单中很多字段都是和主容器字段一样的,除了readiness就绪检测字段。因为readiness是就绪检测,init容器的功能也是为主容器的初始过程服务,如果init也要进行就绪检测,那么就本末倒置,一层套一套更加复杂,所以init中不应该提供就绪检测的生命周期。
缺点:init容器不在main容器过程中,如果init容器放行通过了,那么如果在main容器启动过程中又出错了,那么init容器的存在不就没有意义了吗?
k8s还提供了容器探针的功能:即readinessProbe和livenessProbe

主容器生命周期
# start
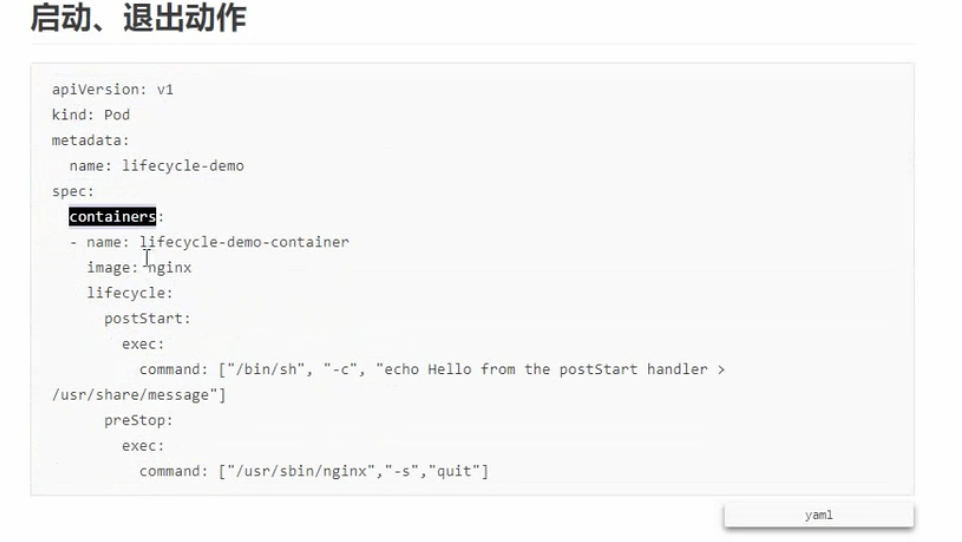
start stop很简单。
# stop

具体实现
# readiness
就绪检测。pod处于running状态,但是容器中的进程可能还没有真正被创建,不应该对外暴露服务,此时使用readiness,可以通过某种策略判断该容器是否可以真正的对外暴露服务了
就绪检测
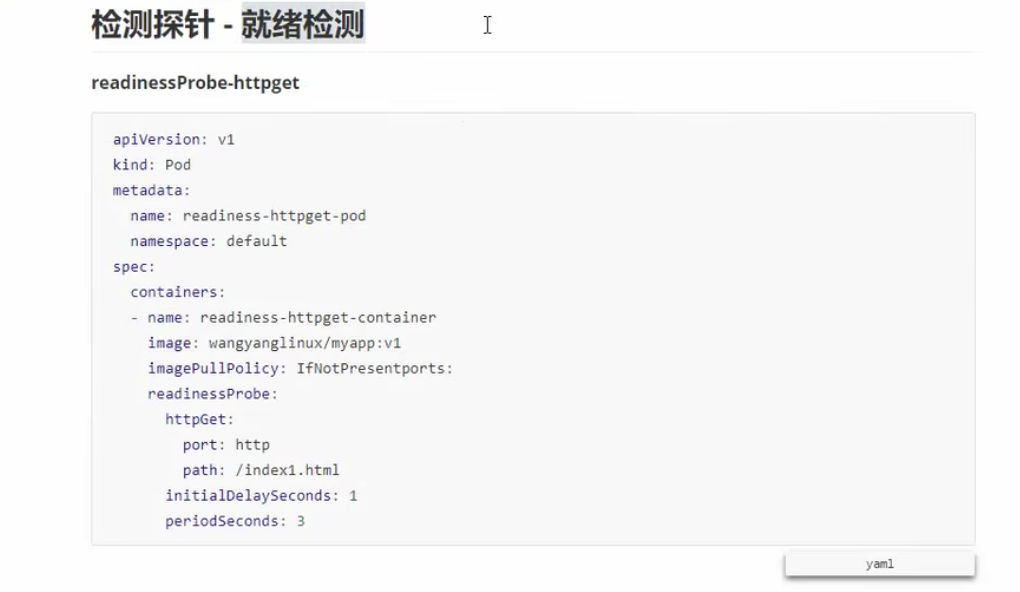
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget-pod
namespace: default
spec:
containers:
- name: readiness-httpget-container
image: httpServiceImage
imagePolicy: IfNotPresent
readinessProbe:
httpGet:
port: 8080
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
因为这里使用了就绪检测,会去Main中的容器看8080端口路径/indext.html是否能够通过index.html调用成功,如果成功了,则可以通过,否则就表示调用失败了。
使用kubectl get pod可以返现status虽然现在处于running状态,但是ready仍为0,因为我们的就绪检测失败了。

那么怎么办呢?首先我们需要使用kubectl desribe pod 名字查看是具体什么原因造成的,然后我们会去容器内部去进行命令交互操作
kubectl exe podName.containName -it -- /bin/sh
进入交互页面,建立index.html页面即可。
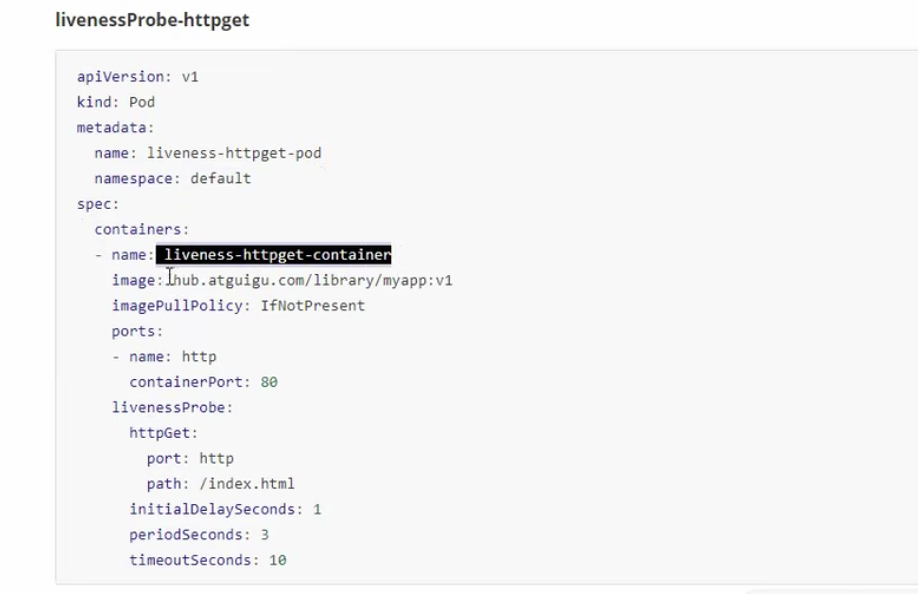
# liveness
生存检测
检测僵尸进程
存活检测
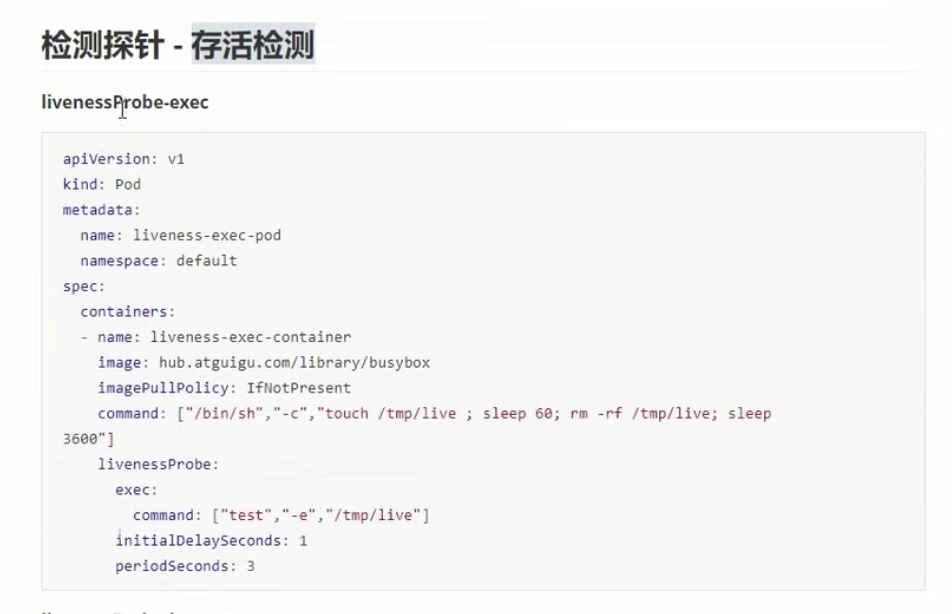
apiVersion: v1
kind: Pod
metadata;
name: liveness-exec-pod
namespace: default
spec:
containers:
- name: liveness-exec-container
image: myServerImage
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/live ; sleep 60 ; rm -rf /tmp/live; sleep 3600"]
livenessProbe:
exec:
command: ["test","-e","/tmp/live"]
initialDelaySeconds: 1
periodSeconds: 3
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
解释:
imagePullPolicy: IfNotPresent。 如果镜像在本地不存在,则到远程去拉去,否则只拉取本地的镜像
command: ["/bin/sh","-c","touch /tmp/live ; sleep 60 ; rm -rf /tmp/live; sleep 3600"]:创建一个文件60s后,删除该文件
livenessProbe:
exec:
command: ["test","-e","/tmp/live"] # 检测指定的文件是否存在
initialDelaySeconds: 1 # 主容器启动后1s才检测
periodSeconds: 3 #每隔3s检测一次
2
3
4
5
检测成功返回0,否则返回1
我们可以启动以上容器并等待一分钟:
kubectl get pod -w
-w, --watch=false:
After listing/getting the requested object, watch for changes.
2
3
即可返回相关变化的容器,我们可以等待1min等待变化。
可以看到restarts的数量发生了变化。
当存活检测后,如果存活检测失败,会干掉整个主main,并重pod。
存活检测的其他测试:
http
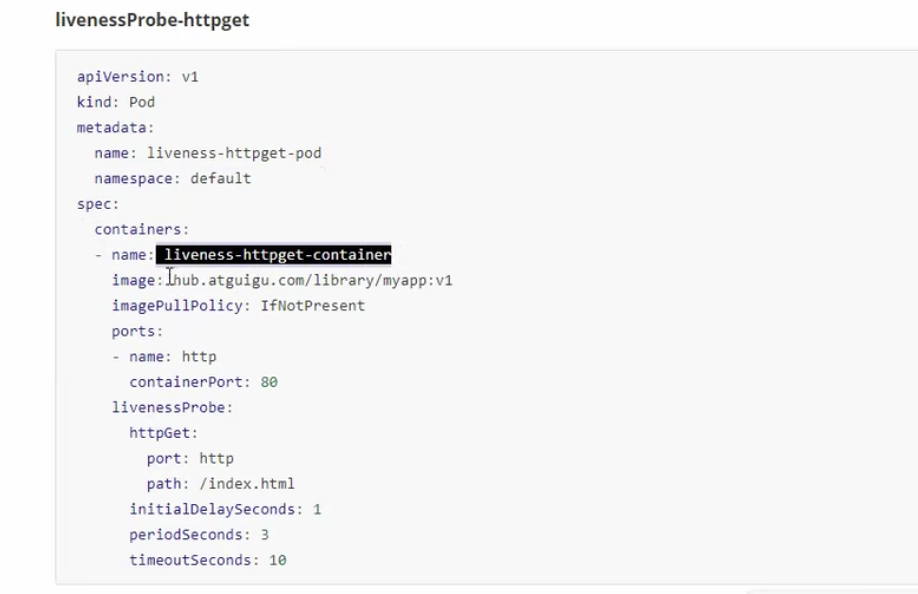
tcp
总结:init成功后,容器进如running状态,但是仍没有进入ready状态,此时进入就绪检测,如果就绪检测未通过,则持续进行就绪检测,如果通过pod状态变为ready,此时开始存活检测,存活检测通过,则每隔一段时间检测一次,如果存活检测不通过,则挂掉整个pod,重新启动,即从init开始启动。
# pod 控制器(灵魂)
掌握各种控制器特点和使用方式
pod分类:自主式(pod退出了,cileixingpod不会被重新创建)、控制器(在控制器的生命周期里,始终要维持pod的副本数量)
一般情况下,我们都会使用控制器下的pod
k8s中有很多控制器,这些相当于一个状态机,用来控制pod的具体状态行为

声明式定义:

例如:sql语句,其不需要考虑底层怎么实现的
当创建一个deployment时,会自动创建rs,rs会自动创建对应的pod



以上的控制器大多适合于无状态服务的pod
以下可以做有状态得到服务

- 自动扩容缩容方案

- RS于RC与Delpoyment的关联

如果不知道yaml中某个标签的含义怎么办?
kubectl explain rs
# 服务发现
将内部私有服务暴露给客户端
掌握syc原理以及构建方式
# 存储
服务分类
- 有状态服务
DBMS
- 无状态服务
LVS APACHE
多种存储类型的特点,并且在不同环境中选择不同的存储方案
# 调度器
可以将pod节点进行组装
# 安全机制
集群的认证、鉴权、访问控制、原理即流程
# HELM
类似yum管理器
掌握HELM原理,自定义模板,可以实现部署插件
# 运维
kubernates源码修改
kubernamtes高可用构建