
 bufferPool详解
bufferPool详解
# 1. Innodb总体架构
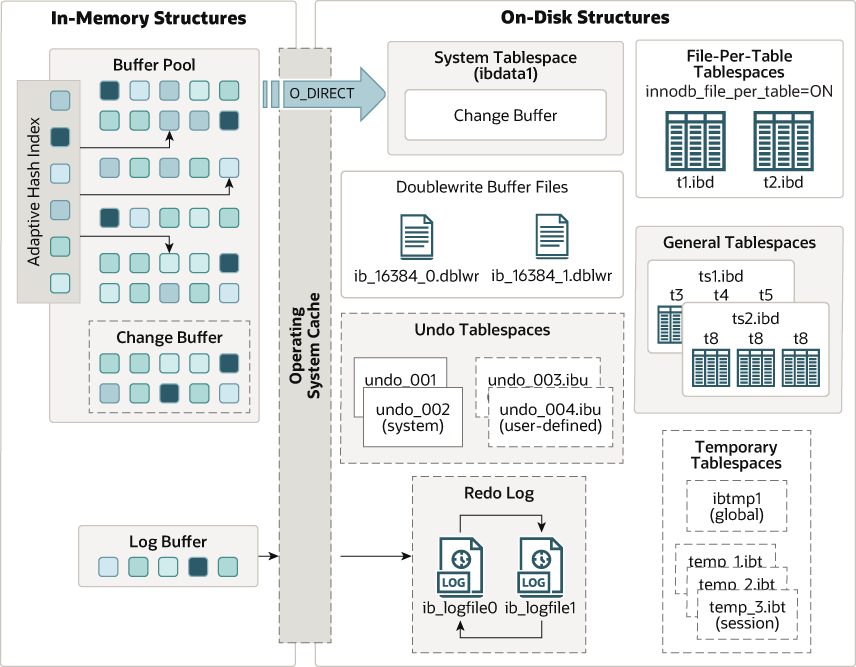
前提:mysql数据存储是以页为单位的,默认的页的大小为16kb。页也有很多种类型,本篇文章我们主要考虑数据页和索引页。
# 2. 一个页的普遍结构
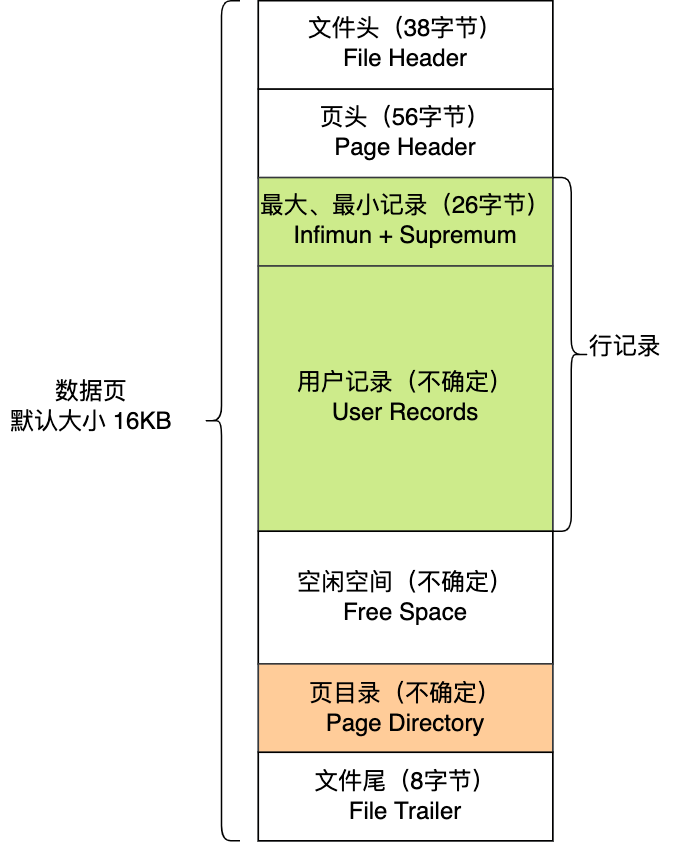
- File Header: 文件头,表示页的信息
- Page Header: 页头,表示页的状态信息
- Infimum+supremum:两个虚拟的伪记录,分别表示页中的最小记录和最大记录。
- User Records: 存储行记录的内容
- Free Space: 页中还没被用使用的空间
- Page Directory: 存储用户记录的相对位置,对记录起到索引作用
- File Taller:校验页的完整性
在 File Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
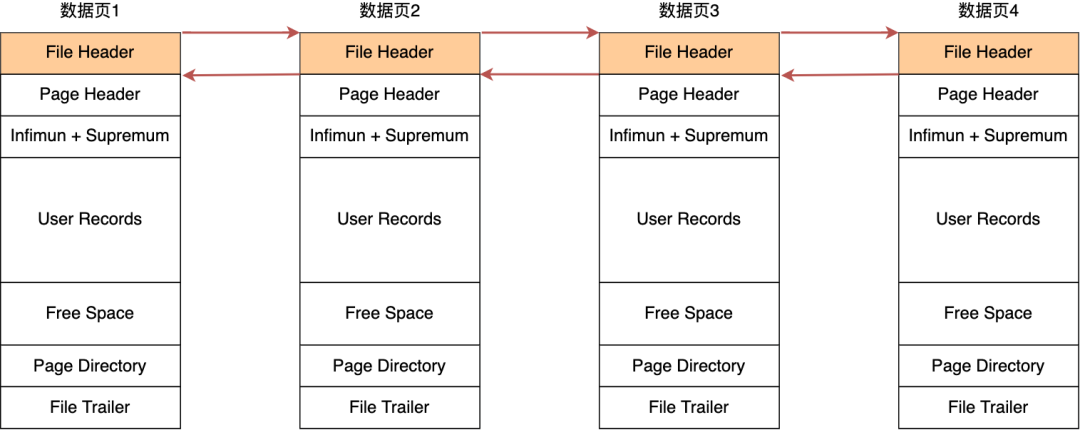
采用链表的结构是让数据页之间不需要是物理上的连续的,而是逻辑上的连续。
# User Records结构
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
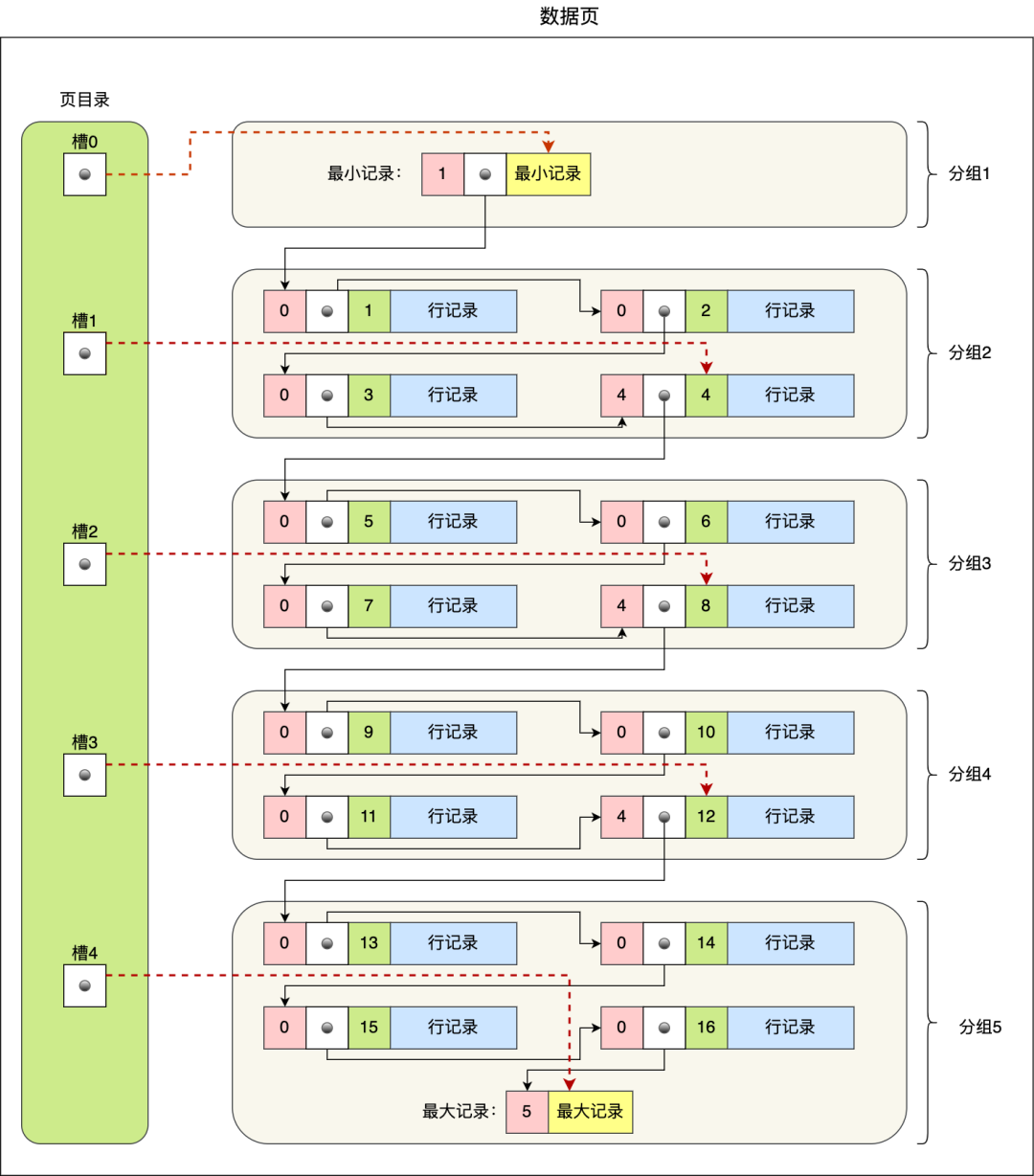
页目录创建的过程如下:
- 将所有的记录划分成几个组,这些记录包括最小记录和最大记录,但不包括标记为“已删除”的记录;
- 每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储该组一共有多少条记录,作为 n_owned 字段(上图中粉红色字段)
- 页目录用来存储每组最后一条记录的地址偏移量,这些地址偏移量会按照先后顺序存储起来,每组的地址偏移量也被称之为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照「主键值」从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
以上面那张图举个例子,5 个槽的编号分别为 0,1,2,3,4,我想查找主键为 11 的用户记录:
- 先二分得出槽中间位是 (0+4)/2=2 ,2号槽里最大的记录为 8。因为 11 > 8,所以需要从 2 号槽后继续搜索记录;
- 再使用二分搜索出 2 号和 4 槽的中间位是 (2+4)/2= 3,3 号槽里最大的记录为 12。因为 11 < 12,所以主键为 11 的记录在 3 号槽里;
- 再从 3 号槽指向的主键值为 9 记录开始向下搜索 2 次,定位到主键为 11 的记录,取出该条记录的信息即为我们想要查找的内容。
看到第三步的时候,可能有的同学会疑问,如果某个槽内的记录很多,然后因为记录都是单向链表串起来的,那这样在槽内查找某个记录的时间复杂度不就是 O(n) 了吗?
这点不用担心,InnoDB 对每个分组中的记录条数都是有规定的,槽内的记录就只有几条:
- 第一个分组中的记录只能有 1 条记录;
- 最后一个分组中的记录条数范围只能在 1-8 条之间;
- 剩下的分组中记录条数范围只能在 4-8 条之间。
现在,我们知道了如何从一个页中快速定位一条数据。那么在数据量很大的情况下,我们就要使用到b+树,我们就需要在海量数据中先定位到数据所在的页,在从页当中找到对应的数据项。
那么b+树是怎么定位页的呢?
# 聚簇索引结构
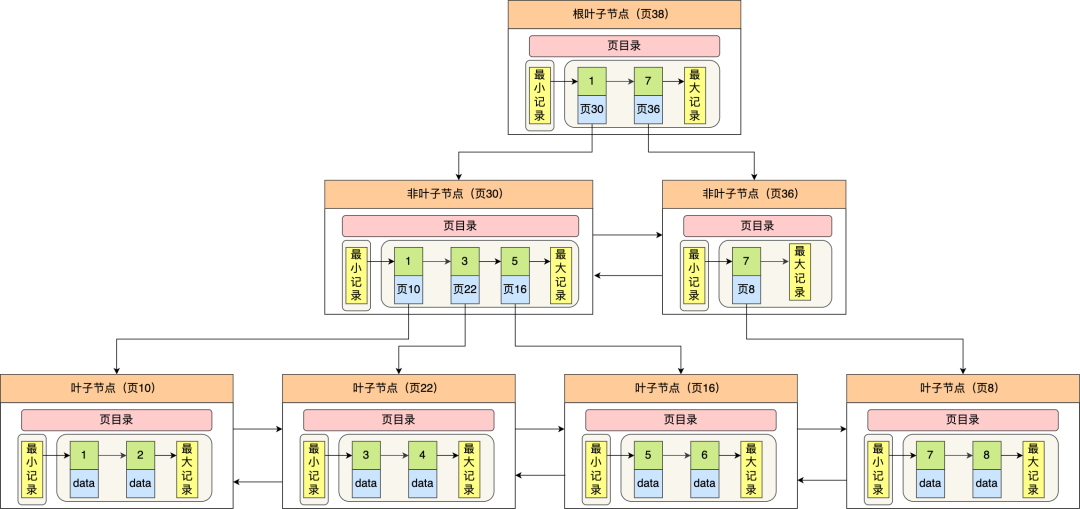
通通过上图,我们看出 B+ 树的特点:
- 只有叶子节点(最底层的节点)才存放了数据,非叶子节点(其他上层节)仅用来存放目录项作为索引。
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量;
- 所有节点按照索引键大小排序,构成一个双向链表,便于范围查询;
我们再看看 B+ 树如何实现快速查找主键为 6 的记录,以上图为例子:
- 从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在[1, 7)范围之间,所以到页 30 中查找更详细的目录项;
- 在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页16)查找记录;
- 接着,在叶子节点(页16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
# 非聚簇索引结构

一张表只能有一个聚簇索引,那为了实现非主键字段的快速搜索,就引出了二级索引(非聚簇索引/辅助索引),它也是利用了 B+ 树的数据结构,但是二级索引的叶子节点存放的是主键值,不是实际数据。
# 3. 为什么会存在bufferPool
现在我们知道一条数据是如何查询出来的了,但是如果每次都像这样从磁盘中查找出可能得页,是不是有点浪费时间呢?怎么优化呢,其实就是根据加入缓存的概念来进行时间的优化,innodb中提供的缓存就叫做buffer pool。
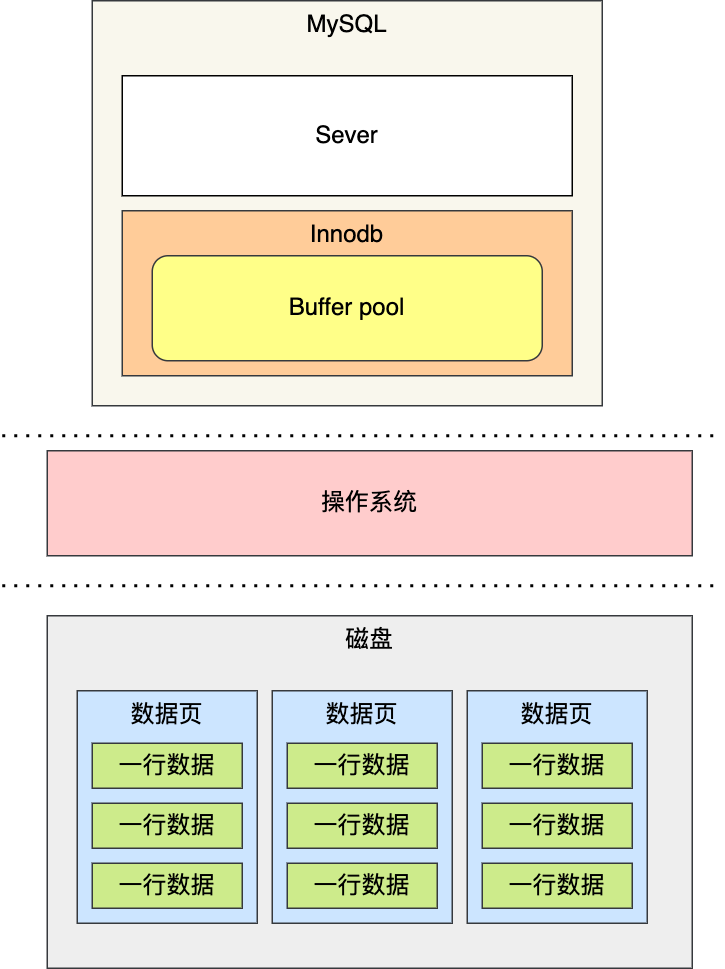
有了缓冲池后:
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
来看看官网的解释:
The buffer pool is an area in main memory where InnoDB caches table and index data as it is accessed. The buffer pool permits frequently used data to be accessed directly from memory, which speeds up processing. On dedicated servers, up to 80% of physical memory is often assigned to the buffer pool.For efficiency of high-volume read operations, the buffer pool is divided into pages that can potentially hold multiple rows. For efficiency of cache management, the buffer pool is implemented as a
# 4. bufferPool的内存结构
那么在bufferPool中这些控制块是怎么进行存放的呢?
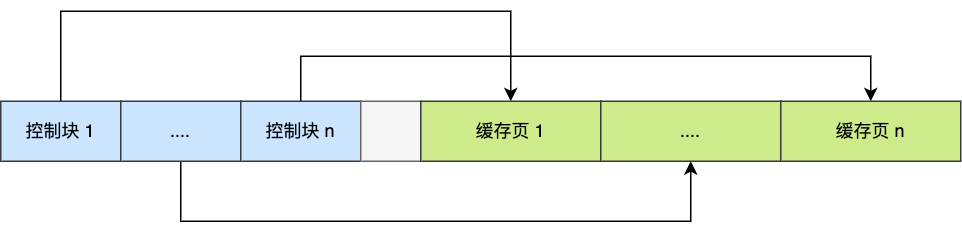
在 MySQL 启动的时候,InnoDB 会为 Buffer Pool 申请一片连续的内存空间,然后按照默认的16KB的大小划分出一个个的页, Buffer Pool 中的页就叫做缓存页。此时这些缓存页都是空闲的,之后随着程序的运行,才会有磁盘上的页被缓存到 Buffer Pool 中。
为了更好的管理这些在 Buffer Pool 中的缓存页,InnoDB 为每一个缓存页都创建了一个控制块,控制块信息包括「缓存页的表空间、页号、缓存页地址、链表节点」等等。
可以从上面看出,这些存放的数据是在物理空间上连续的。
现在我告诉你,一个buffer pool默认128m,那么里面的页就可以存储很多很多份,那么我们如何判断哪些缓存使使用过的?哪些数据是脏数据?哪些页空间还没有被分配?难道我们要从头开始遍历每一个页吗?这样的话效率会很低。
# Free linkedList
所以,为了能够快速找到空闲的缓存页,可以使用链表结构,将空闲缓存页的「控制块」作为链表的节点,这个链表称为 Free 链表(空闲链表)。
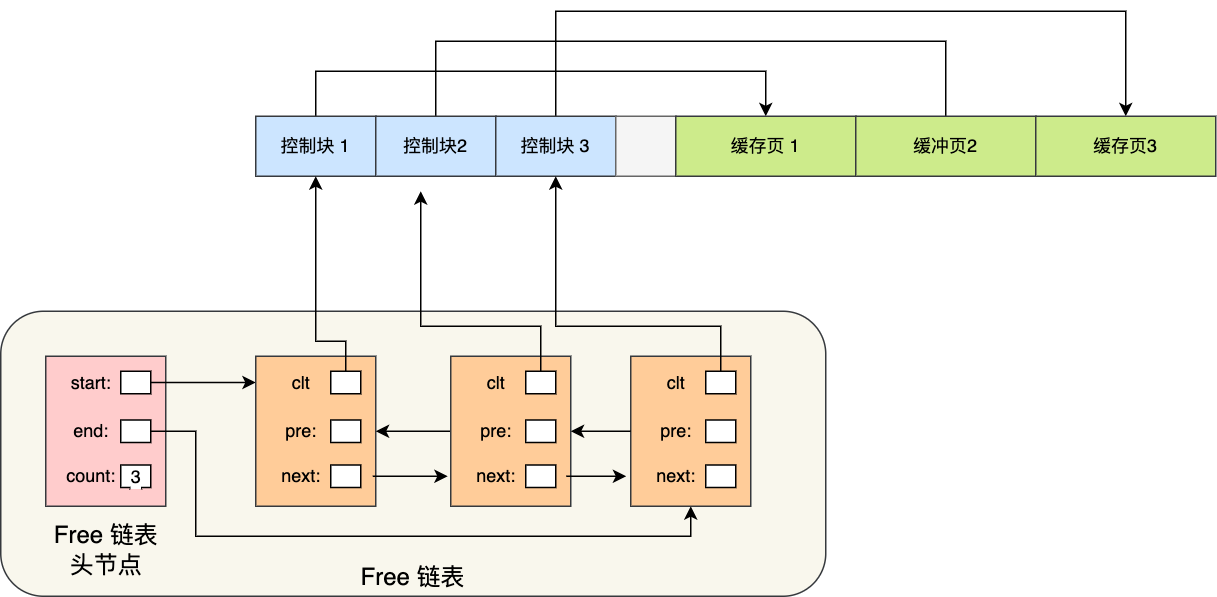
Free 链表上除了有控制块,还有一个头节点,该头节点包含链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。
Free 链表节点是一个一个的控制块,而每个控制块包含着对应缓存页的地址,所以相当于 Free 链表节点都对应一个空闲的缓存页。
有了 Free 链表后,每当需要从磁盘中加载一个页到 Buffer Pool 中时,就从 Free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的控制块从 Free 链表中移除。
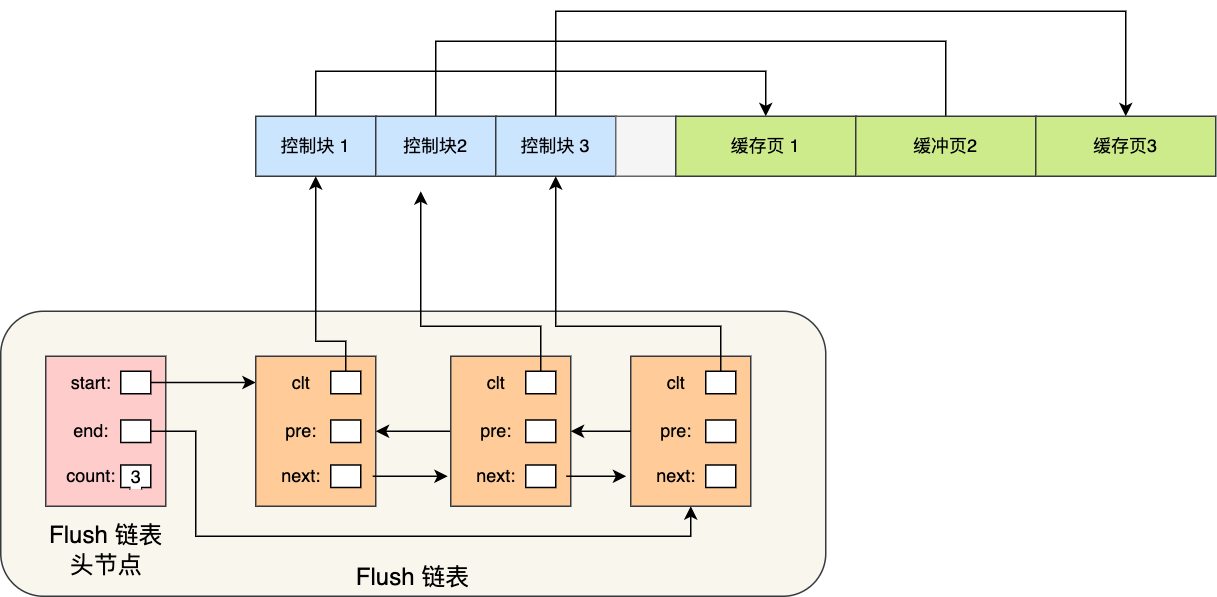
# Flush LinkedList
为什么会有脏页?
我们每次写数据的时候,会首先修改bufferPool对应的页的数据,但是当我们写完后,如果我们立即刷回磁盘进行io操作,性能消耗是很大的,所以我们可以在bufferpool修改后,暂时不进行刷回磁盘,当过一段时间后,在统一刷回磁盘,我们将那些需要刷回磁盘的页标记为脏页。
设计 Buffer Pool 除了能提高读性能,还能提高写性能,也就是更新数据的时候,不需要每次都要写入磁盘,而是将 Buffer Pool 对应的缓存页标记为脏页,然后再由后台线程将脏页写入到磁盘。
那为了能快速知道哪些缓存页是脏的,于是就设计出 Flush 链表,它跟 Free 链表类似的,链表的节点也是控制块,区别在于 Flush 链表的元素都是脏页。
有了 Flush 链表后,后台线程就可以遍历 Flush 链表,将脏页写入到磁盘。
#
# 5. 淘汰算法
# LRU
内存的大小总是有限的,我们不可能将所有的页数据都存放到内存中,那么就必须要考虑将进行常用、热的数据放在内存当中。可以类比redis数据库,最常见的就是LRU算法。
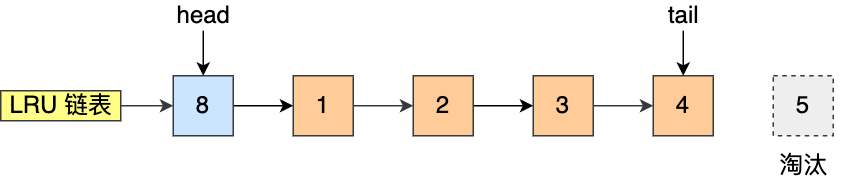
比如下图,假设 LRU 链表长度为 5,LRU 链表从左到右有 1,2,3,4,5 的页。
如果访问了 3 号的页,因为 3 号页在 Buffer Pool 里,所以把 3 号页移动到头部即可。
而如果接下来,访问了 8 号页,因为 8 号页不在 Buffer Pool 里,所以需要先淘汰末尾的 5 号页,然后再将 8 号页加入到头部。
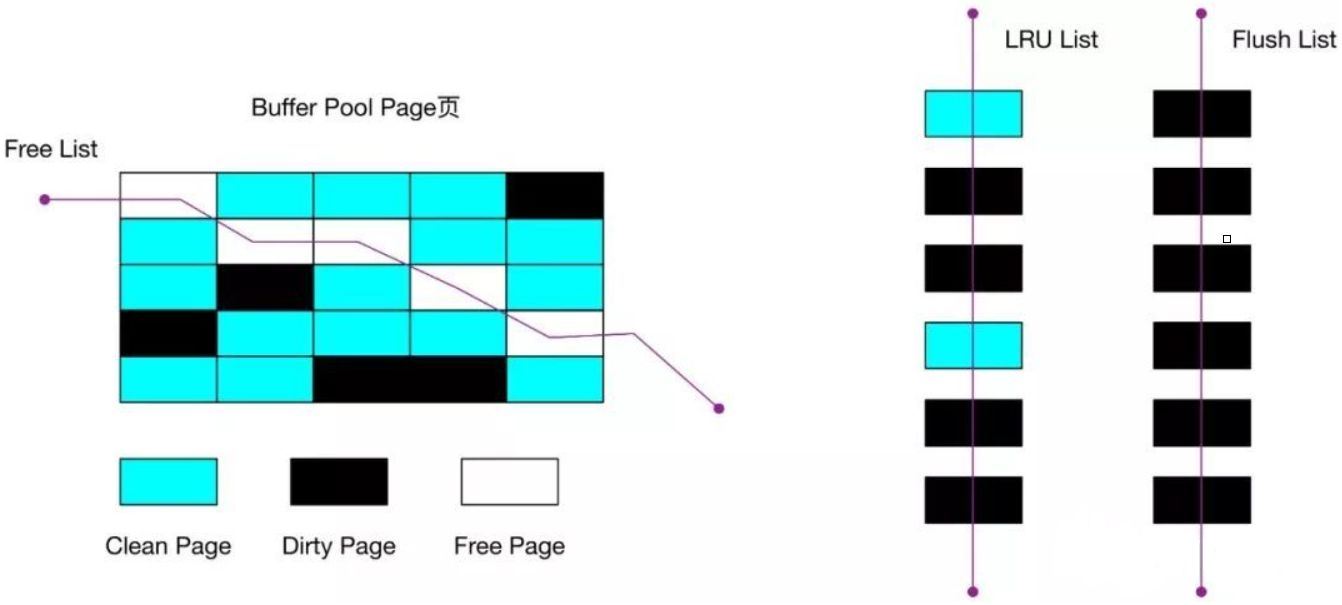
到这里我们可以知道,Buffer Pool 里有三种页和链表来管理数据。
图中:
- Free Page(空闲页),表示此页未被使用,位于 Free 链表;
- Clean Page(干净页),表示此页已被使用,但是页面未发生修改,位于LRU 链表。
- Dirty Page(脏页),表示此页「已被使用」且「已经被修改」,其数据和磁盘上的数据已经不一致。当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该页就变成了干净页。脏页同时存在于 LRU 链表和 Flush 链表。


# innodb LRU
innodb并没有采用传统的LRU算法,为什么呢?因为使用传统的LRU会给mysql带来几个性能问题:
- read-ahead 预读失败
- 缓冲池污染
# 什么是read-ahead
A type of I/O request that prefetches a group of *pages* (an entire ****extent****) into the *buffer pool* asynchronously, in case these pages are needed soon. The linear read-ahead technique prefetches all the pages of one extent based on access patterns for pages in the preceding extent. The random read-ahead technique prefetches all the pages for an extent once a certain number of pages from the same extent are in the buffer pool. Random read-ahead is not part of MySQL 5.5, but is re-introduced in MySQL 5.6 under the control of the
innodb_random_read_ahead(opens new window) configuration option.
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
相当于就是当读取目标页后,也会把目标页附近的页也读取到buffer pool当中。
# 什么又 read-ahead 失败?
当lru所分配的页空间分配完后,这时就会淘汰数据。
当根据预读查询出来的数据会放到链表头部,随后链表尾部的热数据就会被淘汰,但是预读出来的数据因为是根据局部性原理拿出来的,最终不一定能保证会被真正使用到,如果没有被使用到,就叫做预读失败。预读失败使得真正的热数据被淘汰,导致后续消耗额外的io操作查询出热数据。
# 什么是缓存污染
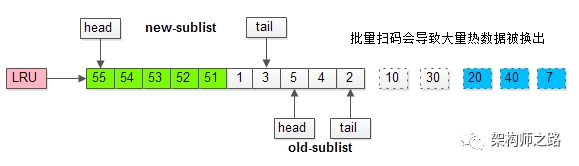
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
# 解决方案
a variation of the least recently used (LRU) algorithm
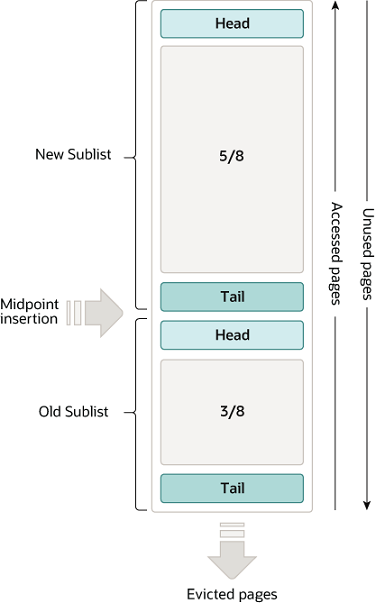
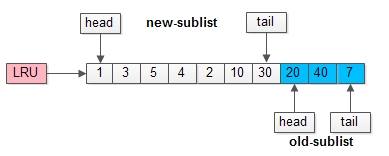
(1)将LRU分为两个部分:
- 新生代(new sublist)
- 老生代(old sublist)
(2)新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
(3)新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
- 如果数据真正被读取(预读成功),才会加入到新生代的头部
- 如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
举个例子,整个缓冲池LRU如上图:
(1)整个LRU长度是10;
(2)前70%是新生代;
(3)后30%是老生代;
(4)新老生代首尾相连;
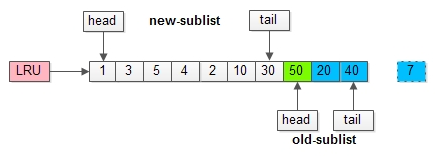
假如有一个页号为50的新页被预读加入缓冲池:
(1)50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
(2)假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;
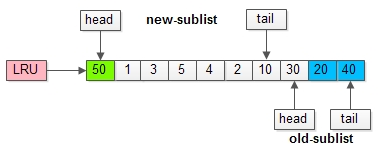
假如50这一页立刻被读取到,例如SQL访问了页内的行row数据:
(1)它会被立刻加入到新生代的头部;
(2)新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。
以上方案很好的解决了预读失败的问题。
那么缓冲池污染问题怎么解决呢?
当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
例如,有一个数据量较大的用户表,当执行:
select * from user where name like "%shenjian%";
虽然结果集可能只有少量数据,但这类like不能命中索引,必须全表扫描,就需要访问大量的页:
(1)把页加到缓冲池(插入老生代头部);
(2)从页里读出相关的row(插入新生代头部);
(3)row里的name字段和字符串shenjian进行比较,如果符合条件,加入到结果集中;
(4)…直到扫描完所有页中的所有row…
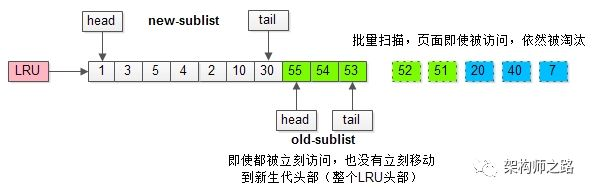
如此一来,所有的数据页都会被加载到新生代的头部,但只会访问一次,真正的热数据被大量换出。
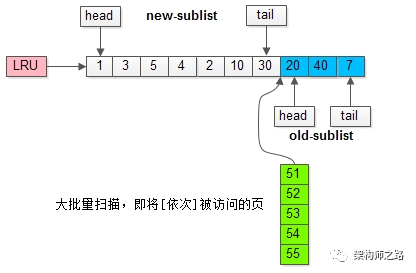
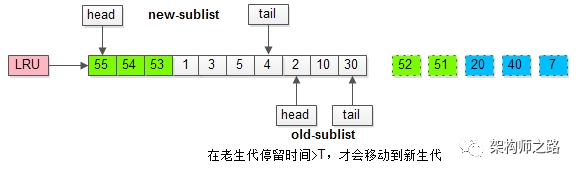
老年代停留时间窗口解决缓冲池污染问题:
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
(1)假设T=老生代停留时间窗口;
(2)插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
(3)只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
继续举例,假如批量数据扫描,有51,52,53,54,55等五个页面将要依次被访问。
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。
加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。
而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。但是像全表扫描,一个数据页中的数据读取是很快的,小于T,从而不会移动到新生代。
# 相关参数
参数:innodb_buffer_pool_size
介绍:配置缓冲池的大小,在内存允许的情况下,DBA往往会建议调大这个参数,越多数据和索引放到内存里,数据库的性能会越好。
参数:innodb_old_blocks_pct
介绍:老生代占整个LRU链长度的比例,默认是37,即整个LRU中新生代与老生代长度比例是63:37。
画外音:如果把这个参数设为100,就退化为普通LRU了。
参数:innodb_old_blocks_time
介绍:老生代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老生代停留时间超过1秒”两个条件,才会被插入到新生代头部。
# 6. buffer pool安全问题
On 64-bit systems with sufficient memory, you can split the buffer pool into multiple parts to minimize contention for memory structures among concurrent operations. For details, see Section 15.8.3.2, “Configuring Multiple Buffer Pool Instances” (opens new window).
When the
InnoDBbuffer pool is large, many data requests can be satisfied by retrieving from memory. You might encounter bottlenecks from multiple threads trying to access the buffer pool at once. You can enable multiple buffer pools to minimize this contention. Each page that is stored in or read from the buffer pool is assigned to one of the buffer pools randomly, using a hashing function. Each buffer pool manages its own free lists, flush lists, LRUs, and all other data structures connected to a buffer pool. Prior to MySQL 8.0, each buffer pool was protected by its own buffer pool mutex. In MySQL 8.0 and later, the buffer pool mutex was replaced by several list and hash protecting mutexes, to reduce contention.
# 1 访问Buffer Pool时需要加锁吗?
对MySQL执行CRUD的第一步,就是利用BP里的缓存来更新或查询。
假设MySQL同时接收到了多个请求,他自然会用多线程处理,那这多线程就可能会同时访问BP,即同时操作里面的缓存页,同时操作一个free链表、flush链表、lru链表。现在多线程来并发的访问这个BP,此时他们都是在访问内存里的一些共享数据结构,如缓存页、各种链表,必要加锁,然后让一个线程先完成一系列操作,比如说加载数据页到缓存页,更新free、lru链表,然后释放锁,接着下个线程再执行操作。
# 2 多线程并发访问加锁,DB性能还能好?
即使就一个BP,多个线程会加锁串行执行,性能也差不到哪。因为大部分情况下,每个线程都是查询或更新缓存页数据,基本都是微秒级,包括更新free、flush、lru这些链表都是基于链表的指针操作,性能也极高。
所以即使每个线程排队加锁,然后执行一系列操作,数据库性也还可以。
但毕竟也是每个线程加锁,然后排队一个个操作,有时你的线程拿到锁后,他可能要从磁盘里读取数据页加载到缓存页,这还发生了一次磁盘I/O!所以他要是进行磁盘IO的话,耗时就会多些,后面排队等的线程就得多等会了!
# 3 多BP实例设置
可以给MySQL设置多个BP来优化其并发能力。MySQL默认规则,若你给BP分配的内存小于1G,那最多就只能给你一个BP。
但若你的机器内存很大,那你必然会给BP分配大内存,比如8G,那此时你可设置多个BP:
[server]
innodb_buffer_pool_size = 8589934592
innodb_buffer_pool_instances = 4
1
2
3
2
3
4
5
6
给BP设置8G总内存,有4个BP,即每个BP 2G。这时,MySQL运行时就有4个BP了!
多线程并发访问时,压力就分散了,这就是分段锁的思想。
# 7. 脏页刷盘时机
引入了 Buffer Pool 后,当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,但是磁盘中还是原数据。
因此,脏页需要被刷入磁盘,保证缓存和磁盘数据一致,但是若每次修改数据都刷入磁盘,则性能会很差,因此一般都会在一定时机进行批量刷盘。
可能大家担心,如果在脏页还没有来得及刷入到磁盘时,MySQL 宕机了,不就丢失数据了吗?
这个不用担心,InnoDB 的更新操作采用的是 Write Ahead Log 策略,即先写日志,再写入磁盘,通过 redo log 日志让 MySQL 拥有了崩溃恢复能力。
下面几种情况会触发脏页的刷新:
- 当 redo log 日志满了的情况下,会主动触发脏页刷新到磁盘;
- Buffer Pool 空间不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘;
- MySQL 认为空闲时,后台线程会定期将适量的脏页刷入到磁盘;
- MySQL 正常关闭之前,会把所有的脏页刷入到磁盘;
在我们开启了慢 SQL 监控后,如果你发现**「偶尔」会出现一些用时稍长的 SQL**,这可能是因为脏页在刷新到磁盘时可能会给数据库带来性能开销,导致数据库操作抖动。
如果间断出现这种现象,就需要调大 Buffer Pool 空间或 redo log 日志的大小。
中文文档:
buffer pool (opens new window)
change pool (opens new window)
Adaptive Hash Index (opens new window)
揭开 Buffer Pool 的面纱 (opens new window)
https://www.modb.pro/db/412019 (opens new window)
官方文档: