
 负载均衡
负载均衡
# 概念
负载均衡 指的是将用户请求分摊到不同的服务器上处理,以提高系统整体的并发处理能力以及可靠性。负载均衡服务可以有由专门的软件或者硬件来完成,一般情况下,硬件的性能更好,软件的价格更便宜
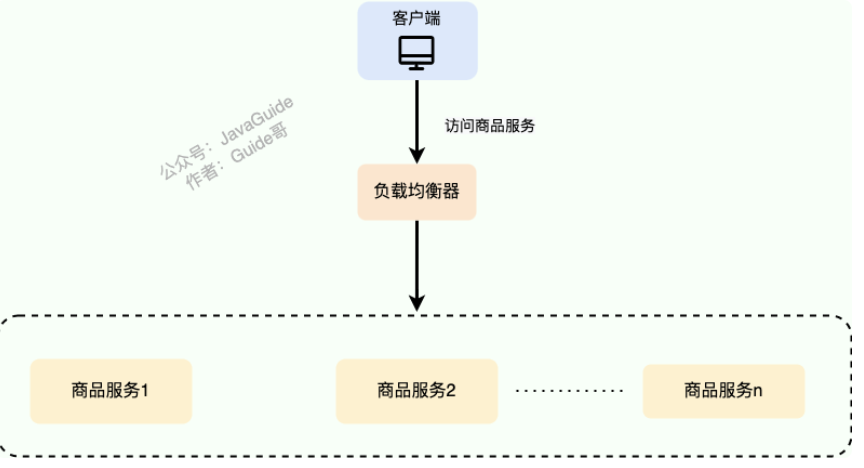
负载均衡是一种比较常用且实施起来较为简单的提高系统并发能力和可靠性的手段,不论是单体架构的系统还是微服务架构的系统几乎都会用到。
# 服务器负载均衡
主要应用在系统外部请求和网关层之间,可以使用软件或硬件完成
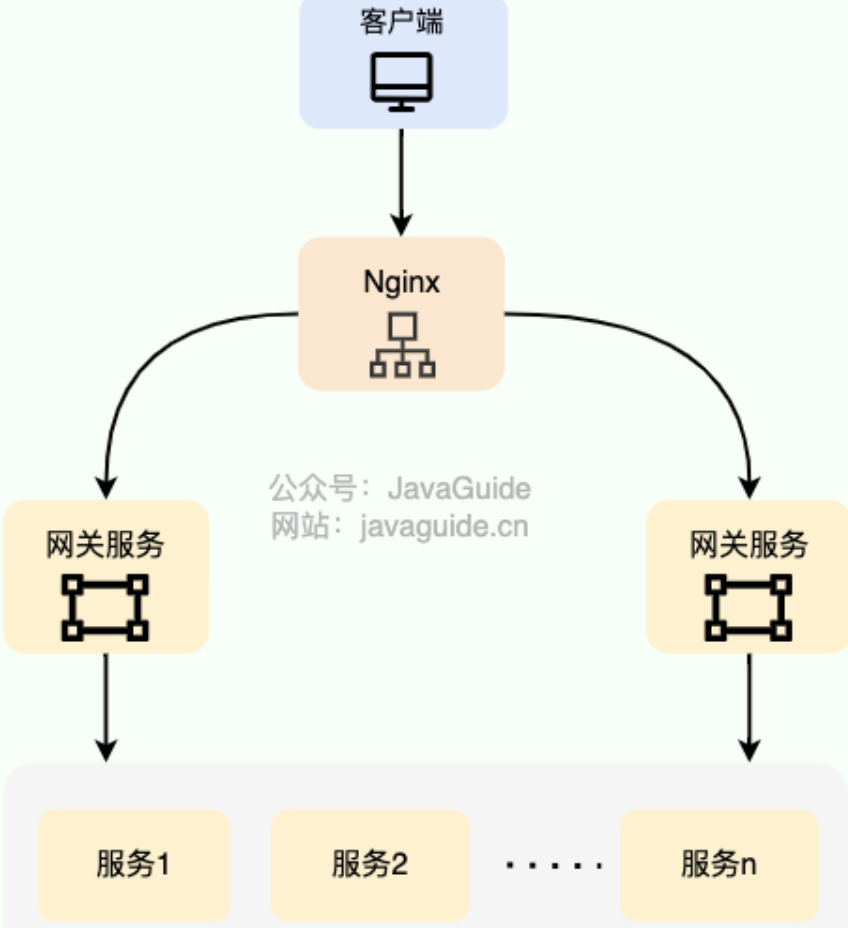
硬件负载均衡 通过专门的硬件设备实现负载均衡的功能(比如F5、A10、Array)
优点就是性能强大且稳定。
但是硬件服务器的价格太过于昂贵。所以一般使用软件负载均衡,是在合适不过的。
那么什么是F5负载均衡器呢,通俗的讲就是将客户端请求量通过F5负载到各个服务器,增加吞吐量,从而降低服务器的压力,他不同于交换机、路由器这些网络基础设备,而是建立在现有网络结构上用来增加网络带宽和吞吐量的的硬件设备

软件负载均衡(LVS、Nginx、HAProxy)
根据OSI模型,服务端的负载均衡还可以分为:
- 二层负载均衡
- 三层负载均衡
- 四层负载均衡(常见)
- 七层负载均衡(常见)
# 常见层次

四层负载均衡 工作在 OSI 模型第四层,也就是传输层,这一层的主要协议是 TCP/UDP,负载均衡器在这一层能够看到数据包里的源端口地址以及目的端口地址,会基于这些信息通过一定的负载均衡算法将数据包转发到后端真实服务器。
七层负载均衡 工作在 OSI 模型第七层,也就是应用层,这一层的主要协议是 HTTP 。这一层的负载均衡比四层负载均衡路由网络请求的方式更加复杂,它会读取报文的数据部分(比如说我们的 HTTP 部分的报文),然后根据读取到的数据内容(如 URL、Cookie)做出负载均衡决策。
七层负载均衡比四层负载均衡会消耗更多的性能,不过,也相对更加灵活,能够更加智能地路由网络请求,比如说你可以根据请求的内容进行优化如缓存、压缩、加密。
简单来说,四层负载均衡性能更强,七层负载均衡功能更强!
一般我们使用LSV(Linux Virtual Server 虚拟服务器, Linux 内核的 4 层负载均衡)做四层负载均衡,使用nginx做七层负载均衡
# linux内核
# nginx
# 客户端负载均衡
客户端负载均衡 主要应用于系统内部的不同的服务之间,可以使用现成的负载均衡组件来实现。
在客户端负载均衡中,客户端会自己维护一份服务器的地址列表,发送请求之前,客户端会根据对应的负载均衡算法来选择具体某一台服务器处理请求。
客户端负载均衡器和服务运行在同一个进程或者说 Java 程序里,不存在额外的网络开销。不过,客户端负载均衡的实现会受到编程语言的限制,比如说 Spring Cloud Load Balancer 就只能用于 Java 语言。
Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱即用的客户端负载均衡实现。Dubbo 属于是默认自带了负载均衡功能,Spring Cloud 是通过组件的形式实现的负载均衡,属于可选项,比较常用的是 Spring Cloud Load Balancer(官方,推荐) 和 Ribbon(Netflix,已被启用)。
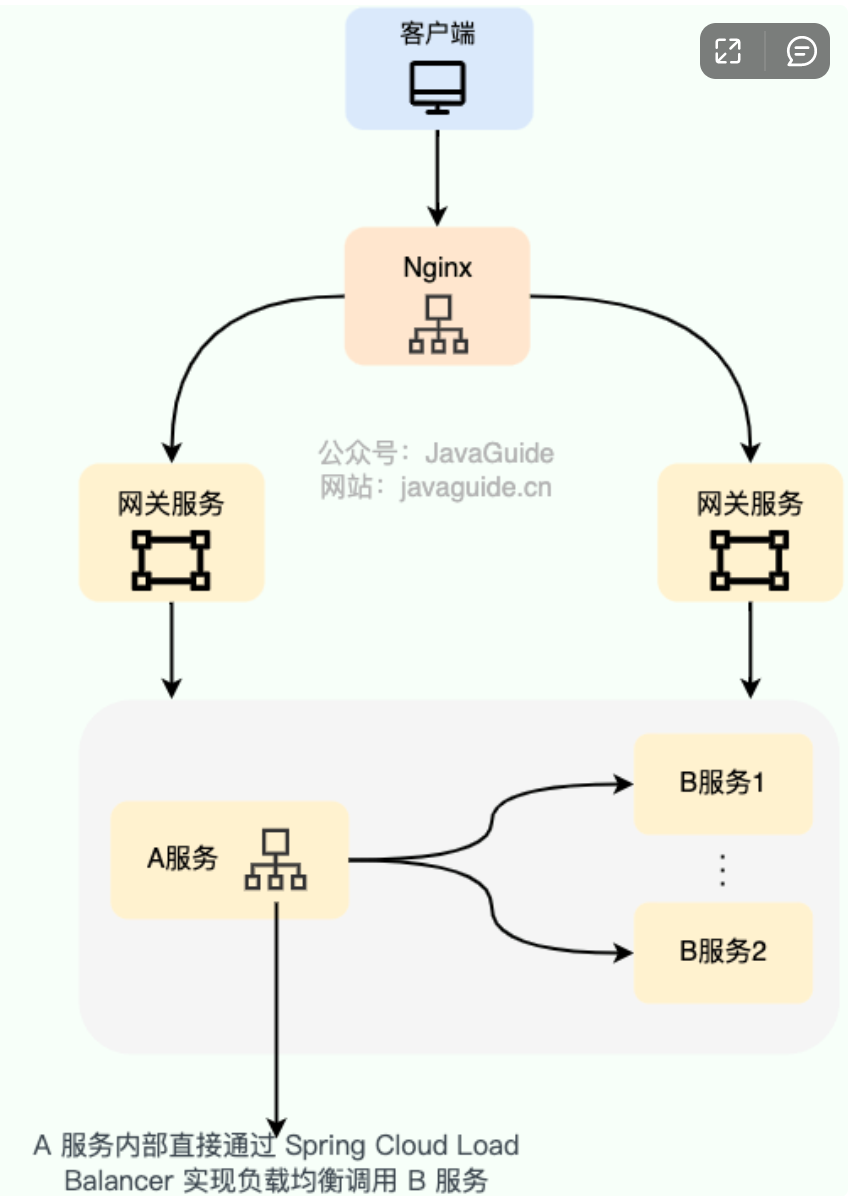
注意上图:不要将客户端理解为简单的前端应用。在微服务架构中,任何调用服务的一方都可以看做是客户端,客户端调用的服务可能做了集群,所以这里可以用负载均衡来分发流量
# 常见的负载均衡算法
# 随机法
如果没有配置权重的话,所有的服务器被访问到的概率都是相同的。如果配置权重的话,权重越高的服务器被访问的概率就越大。
未加权重的随机算法适合于服务器性能相近的集群,其中每个服务器承载相同的负载。加权随机算法适合于服务器性能不等的集群,权重的存在可以使请求分配更加合理化。
不过,随机算法有一个比较明显的缺陷:部分机器在一段时间之内无法被随机到,毕竟是概率算法,就算是大家权重一样, 也可能会出现这种情况。
# 轮询法
轮询法是挨个轮询服务器处理,也可以设置权重。
如果没有配置权重的话,每个请求按时间顺序逐一分配到不同的服务器处理。如果配置权重的话,权重越高的服务器被访问的次数就越多。
未加权重的轮询算法适合于服务器性能相近的集群,其中每个服务器承载相同的负载。加权轮询算法适合于服务器性能不等的集群,权重的存在可以使请求分配更加合理化
# 一致性hash法(源地止hash法)
相同参数的请求总是发到同一台服务器处理,比如同个 IP 的请求。
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
https://developer.huawei.com/consumer/cn/forum/topic/0203810951415790238 (opens new window)
# 最小连接法
当有新的请求出现时,遍历服务器节点列表并选取其中活动连接数最小的一台服务器来响应当前请求。活动连接数可以理解为当前正在处理的请求数。
最小连接法可以尽可能最大地使请求分配更加合理化,提高服务器的利用率。不过,这种方法实现起来也最复杂,需要监控每一台服务器处理的请求连接数。
# 七层负载均衡
七层负载均衡:就是可以根据访问用户的 HTTP 请求头、URL 信息将请求转发到特定的主机。
- DNS 重定向
- HTTP 重定向
- 反向代理
# DNS解析
DNS 解析是比较早期的七层负载均衡实现方式,非常简单。
DNS 解析实现负载均衡的原理是这样的:在 DNS 服务器中为同一个主机记录配置多个 IP 地址,这些 IP 地址对应不同的服务器。当用户请求域名的时候,DNS 服务器采用轮询算法返回 IP 地址,这样就实现了轮询版负载均衡。

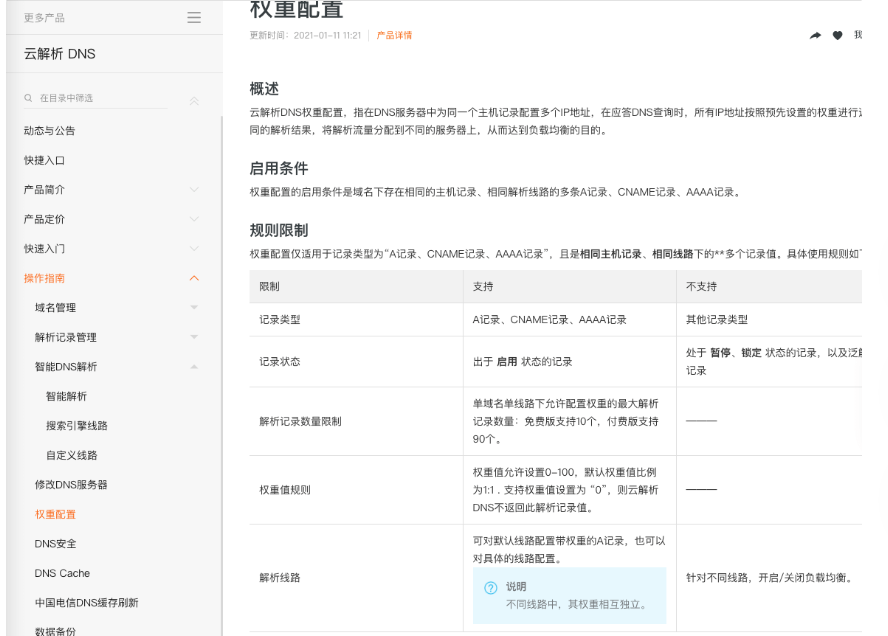
现在的 DNS 解析几乎都支持 IP 地址的权重配置,这样的话,在服务器性能不等的集群中请求分配会更加合理化。像我自己目前正在用的阿里云 DNS 就支持权重配置。
# 反向代理
客户端将请求发送到反向代理服务器,由反向代理服务器去选择目标服务器,获取数据后再返回给客户端。对外暴露的是反向代理服务器地址,隐藏了真实服务器 IP 地址。反向代理“代理”的是目标服务器,这一个过程对于客户端而言是透明的。
Nginx 就是最常用的反向代理服务器,它可以将接收到的客户端请求以一定的规则(负载均衡策略)均匀地分配到这个服务器集群中所有的服务器上。
反向代理负载均衡同样属于七层负载均衡。
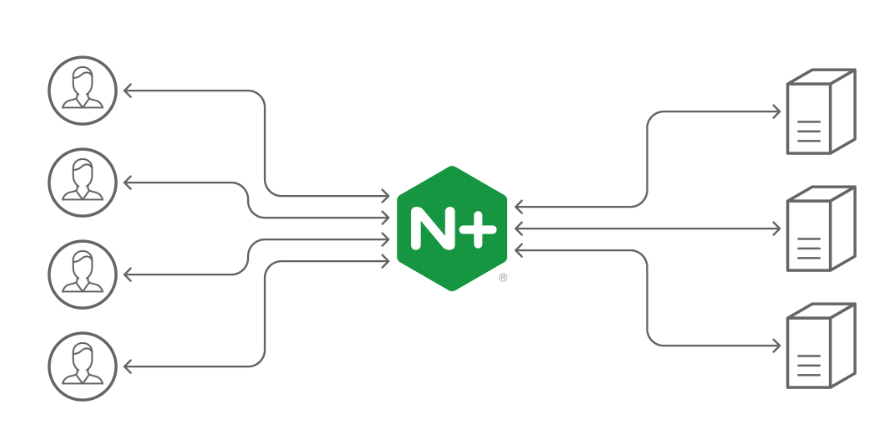
# HTTP重定向
HTTP 负载均衡是基于 HTTP 重定向实现的。HTTP 负载均衡属于七层负载均衡。
HTTP 重定向原理是:根据用户的 HTTP 请求计算出一个真实的服务器地址,将该服务器地址写入 HTTP 重定向响应中,返回给浏览器,由浏览器重新进行访问。
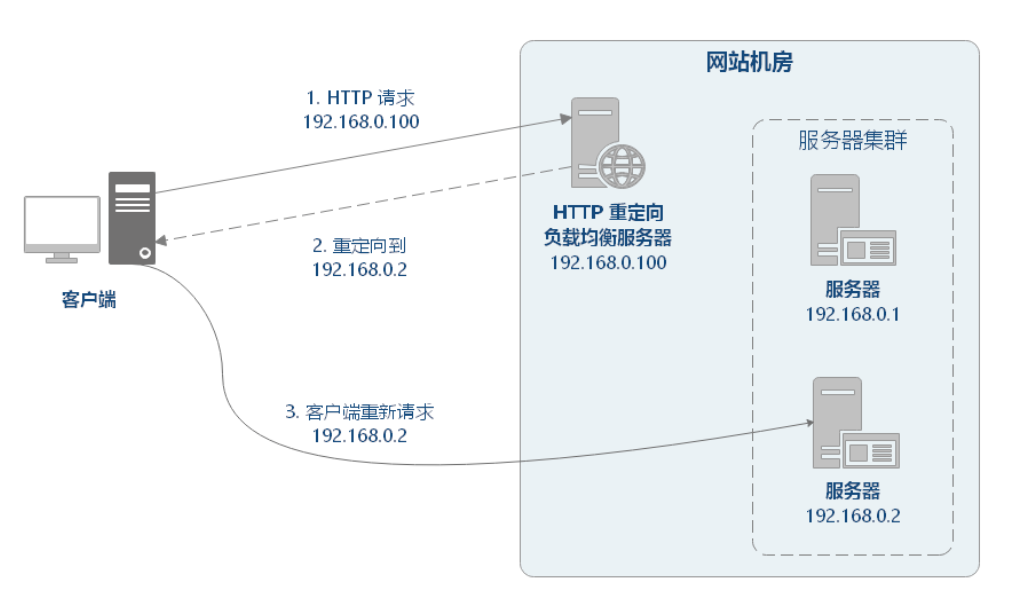
# 四层负载均衡
https://mp.weixin.qq.com/s/bZMxLTECOK3mjdgiLbHj-g (opens new window)
四层负载均衡:基于 IP 地址和端口进行请求的转发。
- 修改 IP 地址
- 修改 MAC 地址
# ip地址
IP 负载均衡是在网络层通过修改请求目的地址进行负载均衡。

如上图所示,IP 均衡处理流程大致为:
客户端请求 192.168.137.10,由负载均衡服务器接收到报文。
负载均衡服务器根据算法选出一个服务节点 192.168.0.1,然后将报文请求地址改为该节点的 IP。
真实服务节点收到请求报文,处理后,返回响应数据到负载均衡服务器。
负载均衡服务器将响应数据的源地址改负载均衡服务器地址,返回给客户端。
IP 负载均衡在内核进程完成数据分发,较反向代理负载均衡有更好的从处理性能。但是,由于所有请求响应都要经过负载均衡服务器,集群的吞吐量受制于负载均衡服务器的带宽。
# 修改 MAC 地址
数据链路层负载均衡是指在通信协议的数据链路层修改 mac 地址进行负载均衡。
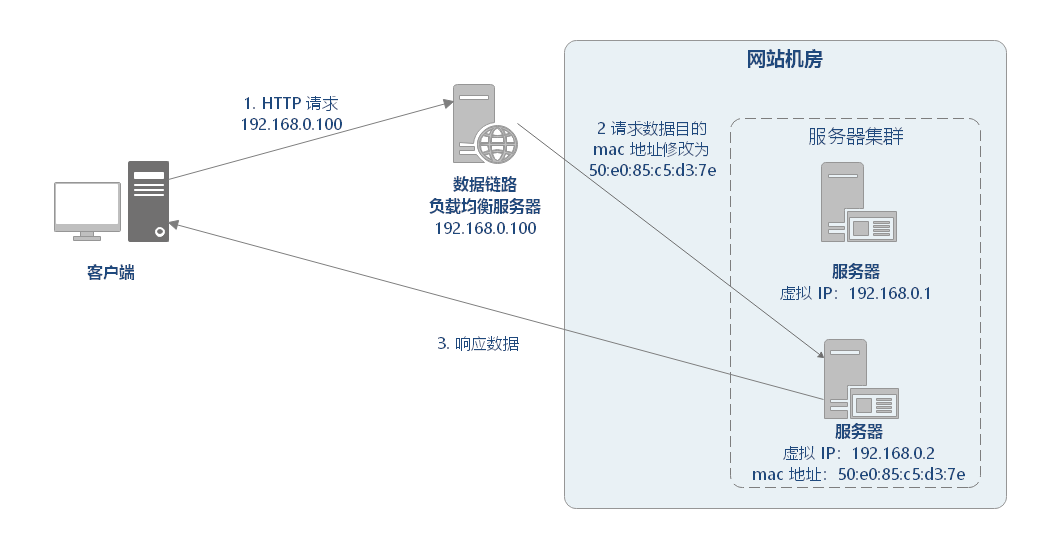
在 Linux 平台上最好的链路层负载均衡开源产品是 LVS (Linux Virtual Server)。LVS 是基于 Linux 内核中 netfilter 框架实现的负载均衡系统。netfilter 是内核态的 Linux 防火墙机制,可以在数据包流经过程中,根据规则设置若干个关卡(hook 函数)来执行相关的操作。
LVS 的工作流程大致如下:
当用户访问 www.sina.com.cn (opens new window) 时,用户数据通过层层网络,最后通过交换机进入 LVS 服务器网卡,并进入内核网络层。
进入 PREROUTING 后经过路由查找,确定访问的目的 VIP 是本机 IP 地址,所以数据包进入到 INPUT 链上
IPVS 是工作在 INPUT 链上,会根据访问的 vip+port 判断请求是否 IPVS 服务,如果是则调用注册的 IPVS HOOK 函数,进行 IPVS 相关主流程,强行修改数据包的相关数据,并将数据包发往 POSTROUTING 链上。
POSTROUTING 上收到数据包后,根据目标 IP 地址(后端服务器),通过路由选路,将数据包最终发往后端的服务器上。
开源 LVS 版本有 3 种工作模式,每种模式工作原理截然不同,说各种模式都有自己的优缺点,分别适合不同的应用场景,不过最终本质的功能都是能实现均衡的流量调度和良好的扩展性。主要包括三种模式:DR 模式、NAT 模式、Tunnel 模式。
# 客户端负载均衡怎么做?
我们上面也说了,客户端负载均衡可以使用现成的负载均衡组件来实现。
Netflix Ribbon 和 Spring Cloud Load Balancer 就是目前 Java 生态最流行的两个负载均衡组件。
Ribbon 是老牌负载均衡组件,由 Netflix 开发,功能比较全面,支持的负载均衡策略也比较多。 Spring Cloud Load Balancer 是 Spring 官方为了取代 Ribbon 而推出的,功能相对更简单一些,支持的负载均衡也少一些。
Ribbon 支持的 7 种负载均衡策略:
● RandomRule :随机策略。
● RoundRobinRule(默认) :轮询策略
● WeightedResponseTimeRule :权重(根据响应时间决定权重)策略
● BestAvailableRule :最小连接数策略
● RetryRule:重试策略(按照轮询策略来获取服务,如果获取的服务实例为 null 或已经失效,则在指定的时间之内不断地进行重试来获取服务,如果超过指定时间依然没获取到服务实例则返回 null)
● AvailabilityFilteringRule :可用敏感性策略(先过滤掉非健康的服务实例,然后再选择连接数较小的服务实例)
● ZoneAvoidanceRule :区域敏感性策略(根据服务所在区域的性能和服务的可用性来选择服务实例)
Spring Cloud Load Balancer 支持的 2 种负载均衡策略:
● RandomLoadBalancer :随机策略
● RoundRobinLoadBalancer(默认) :轮询策略
# 手写负载均衡算法
# 基础
public interface LoadBalance<N extends Node> {
N select(List<N> nodes, String ip);
}
2
3
4
public abstract class BaseLoadBalance<N extends Node> implements LoadBalance<N> {
@Override
public N select(List<N> nodes, String ip) {
if (CollectionUtil.isEmpty(nodes)) {
return null;
}
// 如果 nodes 列表中仅有一个 node,直接返回即可,无需进行负载均衡
if (nodes.size() == 1) {
return nodes.get(0);
}
return doSelect(nodes, ip);
}
protected abstract N doSelect(List<N> nodes, String ip);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Node implements Comparable<Node> {
protected String url;
protected Integer weight;
protected Integer active;
// ...
}
2
3
4
5
6
7
8
9
10
11
12
# 随机算法
public class RandomLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final Random random = new Random();
@Override
protected N doSelect(List<N> nodes, String ip) {
// 在列表中随机选取一个节点
int index = random.nextInt(nodes.size());
return nodes.get(index);
}
}
2
3
4
5
6
7
8
9
10
11
# 随机加权算法
public class WeightRandomLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final Random random = ThreadLocalRandom.current();
@Override
protected N doSelect(List<N> nodes, String ip) {
int length = nodes.size();
AtomicInteger totalWeight = new AtomicInteger(0);
for (N node : nodes) {
Integer weight = node.getWeight();
totalWeight.getAndAdd(weight);
}
if (totalWeight.get() > 0) {
int offset = random.nextInt(totalWeight.get());
for (N node : nodes) {
// 让随机值 offset 减去权重值
offset -= node.getWeight();
if (offset < 0) {
// 返回相应的 Node
return node;
}
}
}
// 直接随机返回一个
return nodes.get(random.nextInt(length));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 轮询法
public class RoundRobinLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final AtomicInteger position = new AtomicInteger(0);
@Override
protected N doSelect(List<N> nodes, String ip) {
int length = nodes.size();
// 如果位置值已经等于节点数,重置为 0
position.compareAndSet(length, 0);
N node = nodes.get(position.get());
position.getAndIncrement();
return node;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 加权轮询法
public class WeightRoundRobinLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
/**
* 60秒
*/
private static final int RECYCLE_PERIOD = 60000;
/**
* Node hashcode 到 WeightedRoundRobin 的映射关系
*/
private ConcurrentMap<Integer, WeightedRoundRobin> weightMap = new ConcurrentHashMap<>();
/**
* 原子更新锁
*/
private AtomicBoolean updateLock = new AtomicBoolean();
@Override
protected N doSelect(List<N> nodes, String ip) {
int totalWeight = 0;
long maxCurrent = Long.MIN_VALUE;
// 获取当前时间
long now = System.currentTimeMillis();
N selectedNode = null;
WeightedRoundRobin selectedWRR = null;
// 下面这个循环主要做了这样几件事情:
// 1. 遍历 Node 列表,检测当前 Node 是否有相应的 WeightedRoundRobin,没有则创建
// 2. 检测 Node 权重是否发生了变化,若变化了,则更新 WeightedRoundRobin 的 weight 字段
// 3. 让 current 字段加上自身权重,等价于 current += weight
// 4. 设置 lastUpdate 字段,即 lastUpdate = now
// 5. 寻找具有最大 current 的 Node,以及 Node 对应的 WeightedRoundRobin,
// 暂存起来,留作后用
// 6. 计算权重总和
for (N node : nodes) {
int hashCode = node.hashCode();
WeightedRoundRobin weightedRoundRobin = weightMap.get(hashCode);
int weight = node.getWeight();
if (weight < 0) {
weight = 0;
}
// 检测当前 Node 是否有对应的 WeightedRoundRobin,没有则创建
if (weightedRoundRobin == null) {
weightedRoundRobin = new WeightedRoundRobin();
// 设置 Node 权重
weightedRoundRobin.setWeight(weight);
// 存储 url 唯一标识 identifyString 到 weightedRoundRobin 的映射关系
weightMap.putIfAbsent(hashCode, weightedRoundRobin);
weightedRoundRobin = weightMap.get(hashCode);
}
// Node 权重不等于 WeightedRoundRobin 中保存的权重,说明权重变化了,此时进行更新
if (weight != weightedRoundRobin.getWeight()) {
weightedRoundRobin.setWeight(weight);
}
// 让 current 加上自身权重,等价于 current += weight
long current = weightedRoundRobin.increaseCurrent();
// 设置 lastUpdate,表示近期更新过
weightedRoundRobin.setLastUpdate(now);
// 找出最大的 current
if (current > maxCurrent) {
maxCurrent = current;
// 将具有最大 current 权重的 Node 赋值给 selectedNode
selectedNode = node;
// 将 Node 对应的 weightedRoundRobin 赋值给 selectedWRR,留作后用
selectedWRR = weightedRoundRobin;
}
// 计算权重总和
totalWeight += weight;
}
// 对 weightMap 进行检查,过滤掉长时间未被更新的节点。
// 该节点可能挂了,nodes 中不包含该节点,所以该节点的 lastUpdate 长时间无法被更新。
// 若未更新时长超过阈值后,就会被移除掉,默认阈值为60秒。
if (!updateLock.get() && nodes.size() != weightMap.size()) {
if (updateLock.compareAndSet(false, true)) {
try {
// 遍历修改,即移除过期记录
weightMap.entrySet().removeIf(item -> now - item.getValue().getLastUpdate() > RECYCLE_PERIOD);
} finally {
updateLock.set(false);
}
}
}
if (selectedNode != null) {
// 让 current 减去权重总和,等价于 current -= totalWeight
selectedWRR.decreaseCurrent(totalWeight);
// 返回具有最大 current 的 Node
return selectedNode;
}
// should not happen here
return nodes.get(0);
}
protected static class WeightedRoundRobin {
// 服务提供者权重
private int weight;
// 当前权重
private AtomicLong current = new AtomicLong(0);
// 最后一次更新时间
private long lastUpdate;
public long increaseCurrent() {
// current = current + weight;
return current.addAndGet(weight);
}
public long decreaseCurrent(int total) {
// current = current - total;
return current.addAndGet(-1 * total);
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
// 初始情况下,current = 0
current.set(0);
}
public AtomicLong getCurrent() {
return current;
}
public void setCurrent(AtomicLong current) {
this.current = current;
}
public long getLastUpdate() {
return lastUpdate;
}
public void setLastUpdate(long lastUpdate) {
this.lastUpdate = lastUpdate;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
# 最小活跃数
public class LeastActiveLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final Random random = new Random();
@Override
protected N doSelect(List<N> nodes, String ip) {
int length = nodes.size();
// 最小的活跃数
int leastActive = -1;
// 具有相同“最小活跃数”的服务者提供者(以下用 Node 代称)数量
int leastCount = 0;
// leastIndexs 用于记录具有相同“最小活跃数”的 Node 在 nodes 列表中的下标信息
int[] leastIndexs = new int[length];
int totalWeight = 0;
// 第一个最小活跃数的 Node 权重值,用于与其他具有相同最小活跃数的 Node 的权重进行对比,
// 以检测是否“所有具有相同最小活跃数的 Node 的权重”均相等
int firstWeight = 0;
boolean sameWeight = true;
// 遍历 nodes 列表
for (int i = 0; i < length; i++) {
N node = nodes.get(i);
// 发现更小的活跃数,重新开始
if (leastActive == -1 || node.getActive() < leastActive) {
// 使用当前活跃数更新最小活跃数 leastActive
leastActive = node.getActive();
// 更新 leastCount 为 1
leastCount = 1;
// 记录当前下标值到 leastIndexs 中
leastIndexs[0] = i;
totalWeight = node.getWeight();
firstWeight = node.getWeight();
sameWeight = true;
// 当前 Node 的活跃数 node.getActive() 与最小活跃数 leastActive 相同
} else if (node.getActive() == leastActive) {
// 在 leastIndexs 中记录下当前 Node 在 nodes 集合中的下标
leastIndexs[leastCount++] = i;
// 累加权重
totalWeight += node.getWeight();
// 检测当前 Node 的权重与 firstWeight 是否相等,
// 不相等则将 sameWeight 置为 false
if (sameWeight && i > 0
&& node.getWeight() != firstWeight) {
sameWeight = false;
}
}
}
// 当只有一个 Node 具有最小活跃数,此时直接返回该 Node 即可
if (leastCount == 1) {
return nodes.get(leastIndexs[0]);
}
// 有多个 Node 具有相同的最小活跃数,但它们之间的权重不同
if (!sameWeight && totalWeight > 0) {
// 随机生成一个 [0, totalWeight) 之间的数字
int offsetWeight = random.nextInt(totalWeight);
// 循环让随机数减去具有最小活跃数的 Node 的权重值,
// 当 offset 小于等于0时,返回相应的 Node
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexs[i];
// 获取权重值,并让随机数减去权重值
offsetWeight -= nodes.get(leastIndex).getWeight();
if (offsetWeight <= 0) {
return nodes.get(leastIndex);
}
}
}
// 如果权重相同或权重为0时,随机返回一个 Node
return nodes.get(leastIndexs[random.nextInt(leastCount)]);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
# 源地址hash
public class IpHashLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
@Override
protected N doSelect(List<N> nodes, String ip) {
if (StrUtil.isBlank(ip)) {
ip = "127.0.0.1";
}
int length = nodes.size();
int index = hash(ip) % length;
return nodes.get(index);
}
public int hash(String text) {
return HashUtil.fnvHash(text);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 一致性hash
public class ConsistentHashLoadBalance<N extends Node> extends BaseLoadBalance<N> implements LoadBalance<N> {
private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<>();
@SuppressWarnings("unchecked")
@Override
protected N doSelect(List<N> nodes, String ip) {
// 分片数,这里设为节点数的 4 倍
Integer replicaNum = nodes.size() * 4;
// 获取 nodes 原始的 hashcode
int identityHashCode = System.identityHashCode(nodes);
// 如果 nodes 是一个新的 List 对象,意味着节点数量发生了变化
// 此时 selector.identityHashCode != identityHashCode 条件成立
ConsistentHashSelector<N> selector = (ConsistentHashSelector<N>) selectors.get(ip);
if (selector == null || selector.identityHashCode != identityHashCode) {
// 创建新的 ConsistentHashSelector
selectors.put(ip, new ConsistentHashSelector<>(nodes, identityHashCode, replicaNum));
selector = (ConsistentHashSelector<N>) selectors.get(ip);
}
// 调用 ConsistentHashSelector 的 select 方法选择 Node
return selector.select(ip);
}
/**
* 一致性哈希选择器
*/
private static final class ConsistentHashSelector<N extends Node> {
/**
* 存储虚拟节点
*/
private final TreeMap<Long, N> virtualNodes;
private final int identityHashCode;
/**
* 构造器
*
* @param nodes 节点列表
* @param identityHashCode hashcode
* @param replicaNum 分片数
*/
ConsistentHashSelector(List<N> nodes, int identityHashCode, Integer replicaNum) {
this.virtualNodes = new TreeMap<>();
this.identityHashCode = identityHashCode;
// 获取虚拟节点数,默认为 100
if (replicaNum == null) {
replicaNum = 100;
}
for (N node : nodes) {
for (int i = 0; i < replicaNum / 4; i++) {
// 对 url 进行 md5 运算,得到一个长度为16的字节数组
byte[] digest = md5(node.getUrl());
// 对 digest 部分字节进行 4 次 hash 运算,得到四个不同的 long 型正整数
for (int j = 0; j < 4; j++) {
// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算
// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算
// h = 2, h = 3 时过程同上
long m = hash(digest, j);
// 将 hash 到 node 的映射关系存储到 virtualNodes 中,
// virtualNodes 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构
virtualNodes.put(m, node);
}
}
}
}
public N select(String key) {
// 对参数 key 进行 md5 运算
byte[] digest = md5(key);
// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,
// 寻找合适的 Node
return selectForKey(hash(digest, 0));
}
private N selectForKey(long hash) {
// 查找第一个大于或等于当前 hash 的节点
Map.Entry<Long, N> entry = virtualNodes.ceilingEntry(hash);
// 如果 hash 大于 Node 在哈希环上最大的位置,此时 entry = null,
// 需要将 TreeMap 的头节点赋值给 entry
if (entry == null) {
entry = virtualNodes.firstEntry();
}
// 返回 Node
return entry.getValue();
}
}
/**
* 计算 hash 值
*/
public static long hash(byte[] digest, int number) {
return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
/**
* 计算 MD5 值
*/
public static byte[] md5(String value) {
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new IllegalStateException(e.getMessage(), e);
}
md5.reset();
byte[] bytes = value.getBytes(StandardCharsets.UTF_8);
md5.update(bytes);
return md5.digest();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
https://www.cnblogs.com/vivotech/p/14859041.html (opens new window)