openStack在华为云的应用
openStack在华为云的应用
# 一.OpenStack简介
# 1. 云计算和虚拟化的区别
- 虚拟化
将物理机通过一定的技术进行虚拟化,分割成逻辑上互相隔离的服务器。主要是提升物理机的资源利用率。环境隔离,降低隔离损耗,提升运行效率。对特定的硬件做一些虚拟化。
更加聚焦于硬件
- 云计算
聚焦的是服务。按需使用。多租户隔离。
两者关系:云计算的基础是虚拟化
# 2. openStack是一个云操作系统
类比windows、linux操作系统。
操作系统的功能
- 抽象资源
资源隔离。例如将网络、cpu等进行抽象,然后对供给上层的软件进行使用。
同样的OpenStack可以将物理机中网络资源、cpu资源、存储资源等进行封装,以统一接口api的方式提供给上层
- 资源分配与负载调度
一般一些软件也是由操作系统来进行资源的分配。
云上会跑很多应用软件,而OpenStack会负责这些软件之间如何进行调度。
- 应用生命周期管理
安装软件、卸载软件。OpenStack也具有相似的功能,如创建虚拟机,关闭虚拟机等。
- 系统运维
监控系统的资源使用了多少
- 人机交互
通过界面进行操作。
将各个物理机的计算资源、网络资源、存储资源进行抽象,形成一个操作系统,提供上层服务。
# 3. OpenStack的定位
OpenStack是一个云计算系统的控制面
是什么事控制面?一个复杂的系统,可以抽象为两个层次---控制面:执行面
例如计算机系统中:
cpu就是控制面,而网卡磁盘就是执行面
人的大脑是控制面,人的四肢就是执行面。
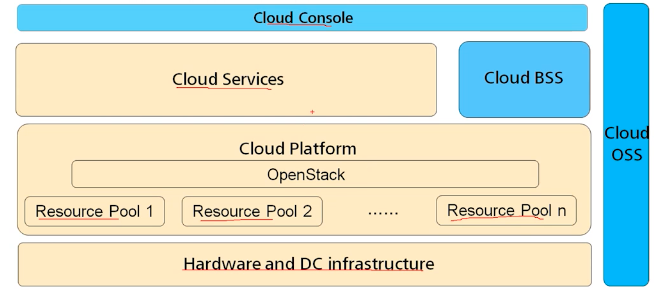
最底层为硬件设施。需要向上进行抽象虚拟,变为Resource Pool即资源池,也就是一个个虚拟出来的虚拟机。OpenStack就相当于一个控制面来操控这些资源,并进一步进行抽象向上层提供统一的api。
OpenStack特性
开源:
灵活:可插拔,提供插件。

可扩展

从一台机器可逐渐扩展到1000台机器
因为由很多相互独立的组件构成,是一个无中心化、无状态的架构
# 4. 项目分层

# 5. 各个组件之间的关系
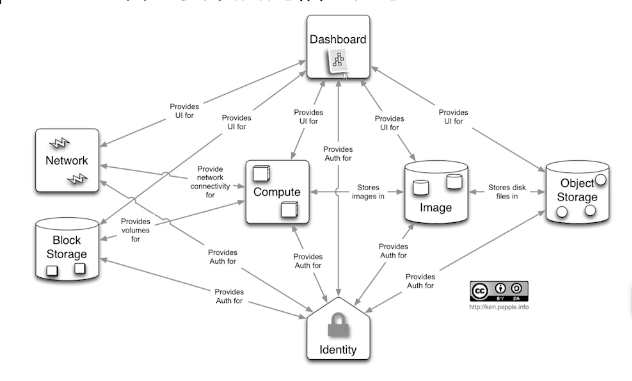
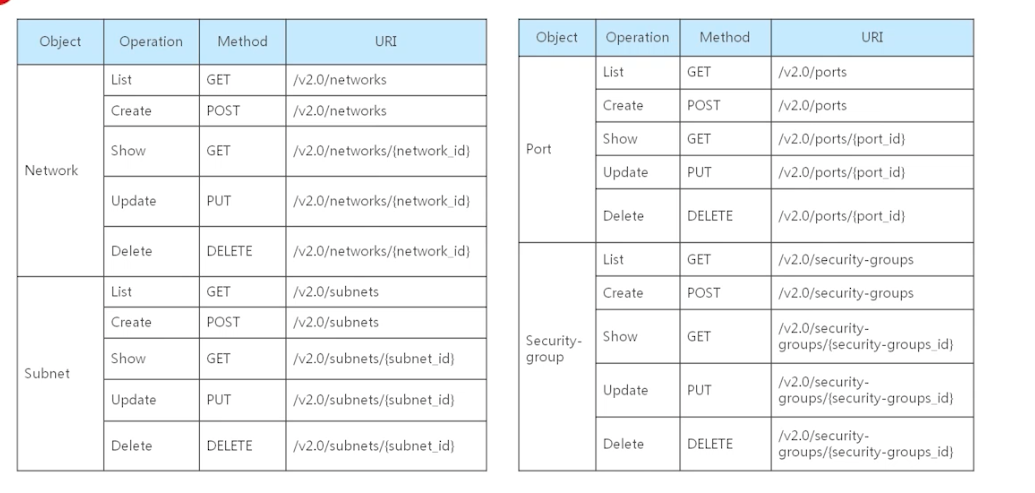
network提供网络服务,提供存储服务,虚拟机需要操作系统,image提供镜像服务,镜像本身存储在对象存储里面,另外,各个组角之间需要通过identity进行鉴权,dashboard通过rest api与各个组件进行交互

# 二.核心组件详解
# 1. Nova
Nova是什么
OpenStack中提供计算资源服务的项目
负责:
虚拟机生命周期管理
其他计算资源生命周期管理
不负责
承载虚拟机的物理主机自身的管理·
全面的系统状态监控
Nova是OpenStack事实上最核心的项目
# ①逻辑架构

- 如果调用API执行一个打开虚拟机的指令。api接收到指令后,会直接调用通过message【默认rabbitmq】下发指令到compute,然后通过Hypervisor去执行打开虚拟机的任务。
什么是Hypervisor? Hypervisor(虚拟机监控器),也被称为虚拟化管理程序,是一种软件、固件或硬件,它允许在单个物理计算机上运行多个虚拟操作系统实例。它的主要功能是管理和分配计算机资源,以便虚拟机可以在同一台物理机上同时运行,而彼此之间相互隔离。
Hypervisor 有两种主要类型:
- Type 1 Hypervisor(裸金属Hypervisor):这种1类型的Hypervisor直接在物理硬件上运行,无需操作系统。它们被认为是更接近硬件的虚拟化解决方案。Type 1 Hypervisor通常用于服务器虚拟化场景,允许在单个物理服务器上运行多个虚拟机。一些著名的Type 1 Hypervisor包括VMware vSphere/ESXi、Microsoft Hyper-V、Xen等。
- Type 2 Hypervisor(主机Hypervisor):这种类型的Hypervisor运行在一个操作系统之上,也被称为主机操作系统。它通过在宿主操作系统内部创建虚拟机,允许用户在宿主操作系统中运行多个虚拟机。这种虚拟化方法通常用于开发和测试环境,以及个人计算机上的虚拟化。一些著名的Type 2 Hypervisor包括Oracle VirtualBox、VMware Workstation、Parallels Desktop等。
Hypervisor 的主要目标之一是在物理资源之间实现隔离,使虚拟机之间不会相互干扰。它们能够分配和管理处理器、内存、存储和网络等资源,使多个虚拟机能够共享同一台物理机的资源,同时保持相对的隔离性和性能。虚拟化技术和Hypervisor对于数据中心的资源优化、快速部署以及灾难恢复等方面具有重要意义。
- 如果调用API属于一个创建虚拟机的指令,这个时候肯可能就比较麻烦了。
这时候指令会先下发到conductor,调用Schedule服务选择对应的机器(例如比较空闲,资源较多)。然后将选择的机器给到compute,conpute调用外界的服务,如Glance和Cinder提供相应的镜像,调用neutron获得网络服务,这些调用外部组件都是通过http来进行调用的。
引入整个服务也是需要将数据存入到一个统一的DB的,openStack默认的Db是mysql数据库。所以各个组件调用数据库是通过sql进行调用的。
# ②物理部署

- 无中心结构,水平可以扩展
- 一般nova-api、nova-Schedule、nova-conduct合并部署在控制节点上
- 通过部署多个控制节点实现HA和负载均衡
- 通过增加控制价节点和计算节点实现简单方面的系统扩容【用户的请求先来到负载均衡器当中,然后在根据算法发送对具体的控制器。后面若要加更多的控制器,很方便】
# ③核心概念1
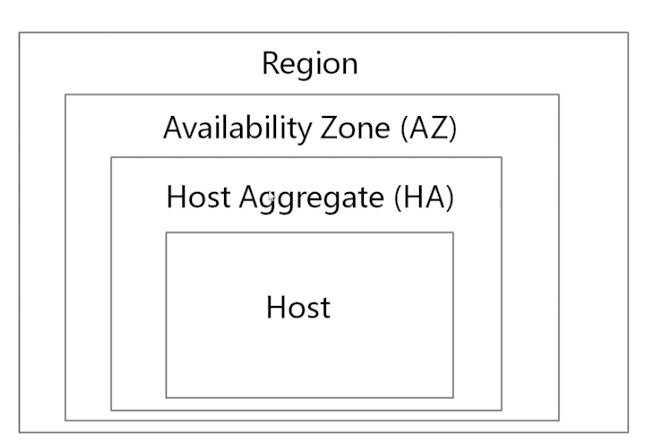
region区域:就相当于我们一些云计算资源就放在不同的区域,如华北区、西南区等等。
Availability zone(AZ): 可用分区。一个可用分区中的机器用相同的电力输入或者网络是相通的,那么他们的可用性是相同的。那么我们把一个region中可用性相同的一群机器叫做一个可用分区。一个区域有多个可用分区。
可用区是指在同一地域内,电力和网络互相独立的物理区域。例如,华北1(青岛)地域支持2个可用区,包括青岛 可用区B和青岛 可用区C。同一可用区内实例之间的网络延时更小,其用户访问速度更快。
Host Aggregate(HA): 主机组。规格相似的主机放在一个组里面。如cpu比较强的一群主机归到一个主机组中。
Host:主机
以上还可以具体参考阿里的描述: 地域和可用区 (opens new window)
有了这几个指标过后,我们如果要通过nova创建一个虚拟机,那么我们就要决定在哪个区域创建,在该区域的哪个可用分区中创建。用户只需要关注以上两个指标。对于云厂商来说,还要关注主机组和主机

# ④核心概念2

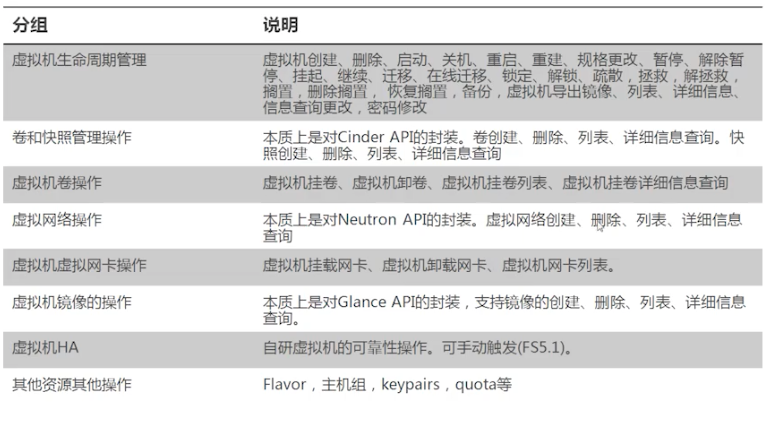
# ⑤典型操作
# 2.Cinder

统一接口:将各种存储硬件设备进行抽象,并向上提供统一的接口
按需分配:租户用多少,就分多少
块存储
持久化
# ①逻辑架构

当nova发送一条指令来了过后,cinder-api会将指令处理后传递。
Api->scheduler->volume->driver.
最后由存储后台去执行相应的命令。所以看来OPenstack聚焦于控制,而不是执行。这也决定了OPenstack不会成为执行性能的瓶颈。
# ②Cinder典型组网(SAN存储)
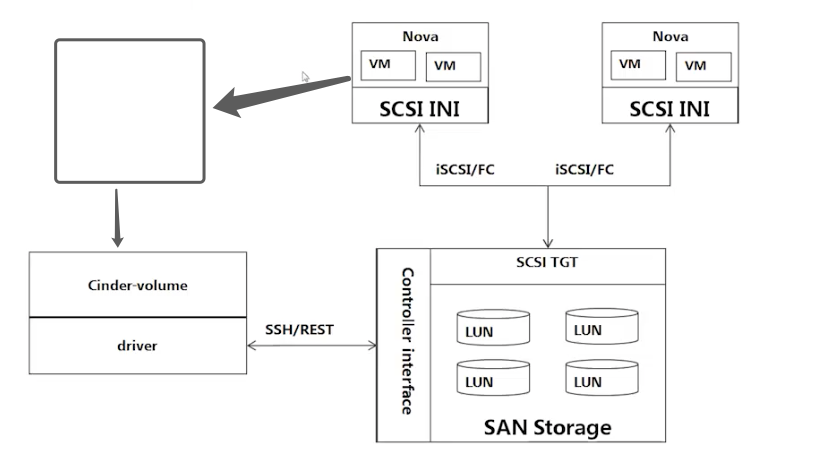
nova发送存储的指令后,会一步一的到达driver,最后driver将命令发送给真正的存储设备,由存储设备进行执行,并最终映射给nova虚拟机。
# ③物理部署

组件内部是通过rabbitmq进行交互,外部是通过rest api进行交互
# ④典型的操作

# 3.neutron
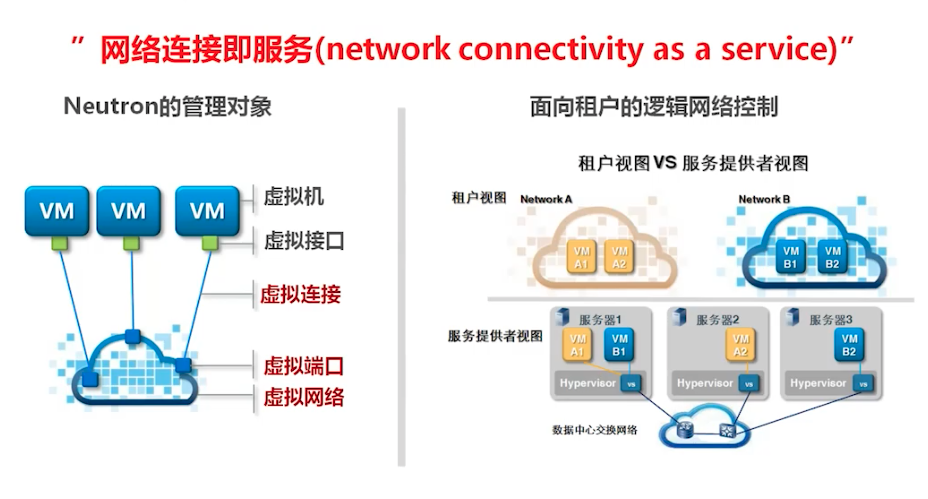
租户视图:只需要关心创建的某一个虚拟机处于哪一个网络中
服务提供者视图:
不同物理机上的虚拟机怎么连接到同一个网络中
相同物理机上的虚拟机怎么做到网络隔离
# ①逻辑架构

# ②网络虚拟化原理
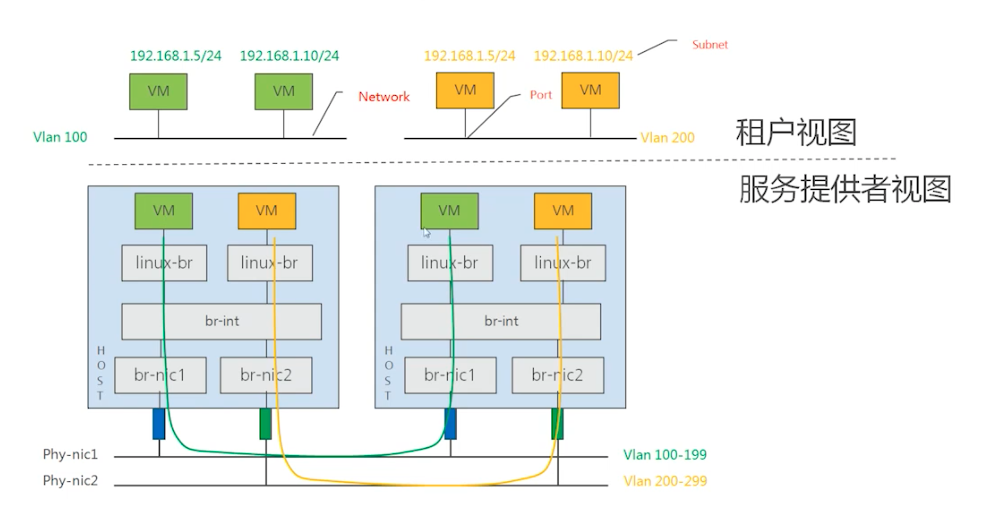
# ③物理部署示例
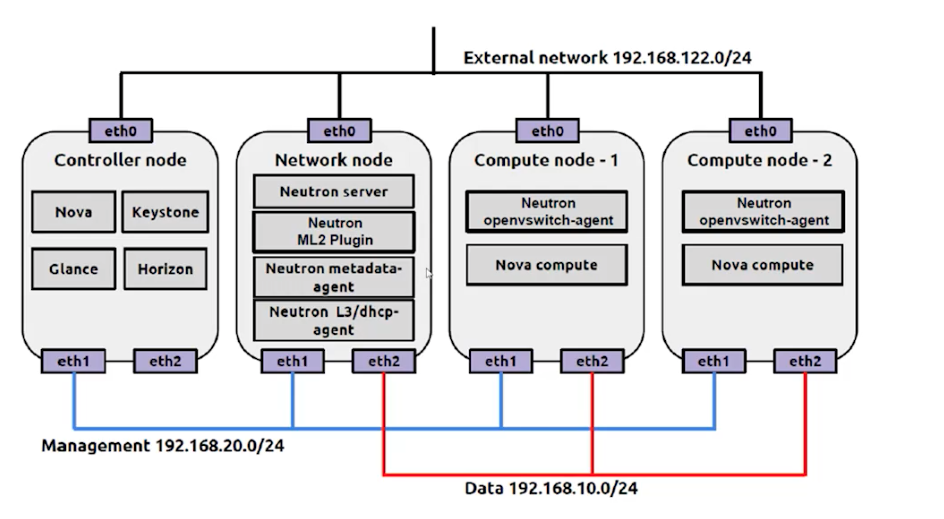
# ④典型操作