
 微服务之雪崩问题
微服务之雪崩问题
# 微服务的高内聚和低耦合
首先提一下微服务的一个划分原则:高内聚和低耦合。 高内聚:相关度比较高的部分尽可能的集中,不要分散。 低耦合:两个相关的模块尽可能降低依赖。
应该说,模块化、低耦合一直以来都是软件设计追求的目标,独立部署的微服务使模块之间的依赖关系更加清晰,也更加隔离,使系统易于开发、维护,代表了正确的技术方向。但需要注意的是低耦合的两个微服务之间还是存在着一定的请求调用关系,否则就是零耦合了。既然请求调用关系很多时候避免不了,那么当一个复杂系统划分了很多微服务后,服务间请求调用链在一定程度上将增加系统维护、问题排查的复杂性。
# 服务调用链
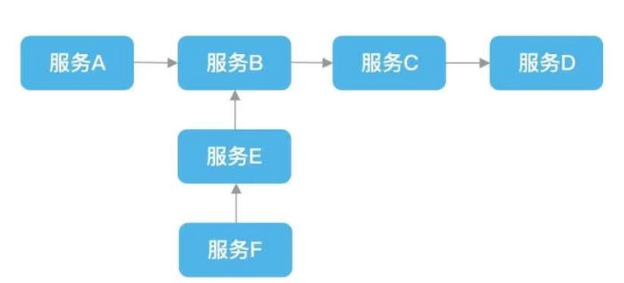 如上图,服务间存在多个内部调用,这里形成两条请求链路,一是服务 A => 服务 B => 服务 C => 服务 D,二是服务 F => 服务 E => 服务 B。可以看到服务 B 是两条调用链间的交界点,同时也依赖了其他多个服务。
如上图,服务间存在多个内部调用,这里形成两条请求链路,一是服务 A => 服务 B => 服务 C => 服务 D,二是服务 F => 服务 E => 服务 B。可以看到服务 B 是两条调用链间的交界点,同时也依赖了其他多个服务。
# 级联故障和雪崩
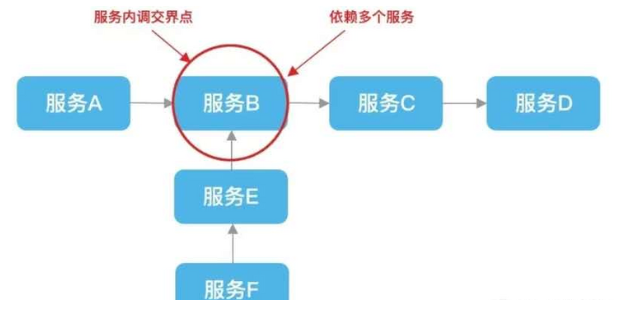
服务 B 作为服务 A 和服务 F 的两个流量入口必经之处,可能是一个公共服务,但它也依赖了其他多个服务。假设服务 C 或服务 D 其中一个有问题,在没有熔断措施的情况下,就会出现级联故障,系统逐渐崩盘,最终导致雪崩。
一种常见的情况是服务 D 所依赖的外部接口出现了故障但自己没有做任何控制或防护措施,因此扩散到了所有调用它的服务,自然也就包含服务 B。以这个例子来讲,其实外部接口出现故障并不是最大的问题,最大的问题很可能是服务 D 没有针对外部接口调用设置 timeout 超时,从而造成上层大量请求等待堆积,请求数得不到释放,系统负载过高最终导致服务崩溃。不过光有 timeout 超时机制是不够的,下文会提到更进一步的措施。
# 应对措施
在我看来,分布式微服务系统要避免雪崩,由单个微服务来分析可以从两个方面考虑:一是微服务自身的高可用及抗压能力,要能抗住流量洪峰;二是当该微服务所直接依赖的其他微服务出现故障时,自己能否优雅地处理。有点类似于人人做好自己(其实第二个方面的要求已经不光是做好自己了,还要求当与自己有密切关系的其他人疯了后不要让自己也跟着疯了,尽量降低对自己的影响),社会自然就稳定的道理。
# 服务限流
从提升微服务自身素质这一点来讲,每个微服务首先应尽量保证自身健壮性、稳定性。如果你的微服务是要应对高并发的,有三把利器用来保护系统:缓存、降级和限流。缓存的目的是提升系统访问速度及吞吐量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性能时需要暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页)等,因此需有一种手段来限制这些场景的并发/请求量,即限流。
限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误页或告知资源没有了)、排队或等待(比如秒杀、评论、下单)、降级(返回兜底数据或默认数据,如商品详情页库存默认有货)。
一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池、线程池)、限制瞬时并发数(如 Nginx 的 limit_conn 模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如 Nginx 的 limit_req 模块,限制每秒的平均速率)。其他还有如限制远程接口调用速率、限制消息队列的消费速率,另外还可以根据网络连接数、网络流量、CPU 或内存负载等来限流。
# 服务熔断
从另一个方面来讲,微服务自身是完善稳定了,但如果其依赖的其他微服务出现不可控的故障时,就可以顺其自然,放任不管了吗?
这就涉及到熔断机制了,熔断这一概念来源于电子工程中的断路器(Circuit Breaker)。熔断机制是应对雪崩效应的一种微服务链路保护机制。我们在各种场景下都会接触到熔断这两个字。高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。股票交易中,如果股票指数过高,也会采用熔断机制,暂停股票的交易。
同样,在微服务架构中,熔断机制也是起着类似的作用。在互联网系统中,当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断。当请求调用链中的某个微服务不可用或者响应时间太长时,会进行服务的降级,开启熔断状态,熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,关闭熔断状态,恢复正常的请求调用。
# 服务降级
服务降级其实可以分为两种性质的降级:
- 从自身流量保护角度。比如当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常高效运行,我们可以将一些不重要或不紧急的服务或任务进行服务的延迟使用或暂停使用,亦或是对服务中的某个模块进行阉割或者替换为简单实现版本。
- 从优雅应对所依赖的服务故障角度。与上面服务熔断相对应,当服务所依赖的其他服务发生故障时,会开启熔断状态,比如后续对该服务接口的调用不再经过网络,执行本地的默认方法或者对上层返回友好的错误提示等,达到服务降级的效果。