
 基础
基础
- 安装
- 优势
- 极其简单的部署方式
可以直接编译成机器码
不依赖其他库
直接运行即可部署
- 静态类型语言
编译的时候就可以检查出隐藏的错误(go build xx.go)
- 语言层面的并发
天生的并发基因支持
充分利用多核

- 强大的标准库
runtime系统调度机制
高效的GC垃圾回收
丰富的标准库

- 简单易学
25个关键字
C语言简介
面向对象
跨平台
- 大厂领军
facebook(平滑升级grace)
腾讯 百度 京东 小米 七牛 滴滴 阿里巴巴
语言对比:

编译和运行速度较好
适合做什么:


缺点:

# 1. hello go
先随便创建一个文件hello.go
package main //程序的报名
import "fmt" //导包
import ( //到多个包
"fmt"
"time"
)
func main(){ //这里的{ 必须与函数名同行,不然会报错(强制了代码风格)
fmt.Println("hello go") //有无分号都可以,建议不加
}
2
3
4
5
6
7
8
9
10
11
go run hello.go 编译+运行
go build hello.go 编译
生成可执行文件./hello运行
- 第一行代码package main定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。
- 下一行**import "fmt"**告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。
- 下一行func main()是程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。
# 2.变量
func main(){
//法1
var a int //变量默认为0
//法2
var b int = 100
//法3:在初始化时,可以省去数据类型,通过值自动匹配当前变量的数据类型
var c = 100
//如何看类型?
fmt.printf("type of a= %T\n",a) //格式化输出T
//法4:省略var,直接自动匹配
e:=100
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
注意:以上的4种方法定义成员变量没有问题,但是在定义成员变量的时候(全局变量),法4不能使用。即法4只能用在定义成员变量
//定义多个变量
var xx,yy int = 100,200
var x,y=1,"s"
var{
vv int =100
jj bool=true
}
2
3
4
5
6
7
8
数字怎么转字符串?
fmt.Printf(strconv.Itoa(num))
# 3. 常量
func main(){
//常量 只读,不能进行修改
const length int = 10
}
2
3
4
5
定义枚举类型
package main
import "fmt"
const(
SHANGHAI=0
BEIJING=2
)
func main(){
}
2
3
4
5
6
7
8
9
10
11
12
13
14
在const()中,有一个iota标识符
在 golang 中,一个方便的习惯就是使用iota标示符,它简化了常量用于增长数字的定义,给以上相同的值以准确的分类
const (
CategoryBooks = iota // 0
CategoryHealth // 1
CategoryClothing // 2
)
2
3
4
5
- iota和表达式
iota可以做更多事情,而不仅仅是 increment。更精确地说,iota总是用于 increment,但是它可以用于表达式,在常量中的存储结果值。
type Allergen int
const (
IgEggs Allergen = 1 << iota // 1 << 0 which is 00000001
IgChocolate // 1 << 1 which is 00000010
IgNuts // 1 << 2 which is 00000100
IgStrawberries // 1 << 3 which is 00001000
IgShellfish // 1 << 4 which is 00010000
)
2
3
4
5
6
7
8
9
10
这个工作是因为当你在一个const组中仅仅有一个标示符在一行的时候,它将使用增长的iota取得前面的表达式并且再运用它,。在 Go 语言的spec (opens new window)中, 这就是所谓的隐性重复最后一个非空的表达式列表.
如果你对鸡蛋,巧克力和海鲜过敏,把这些 bits 翻转到 “on” 的位置(从左到右映射 bits)。然后你将得到一个 bit 值00010011,它对应十进制的 19。
fmt.Println(IgEggs | IgChocolate | IgShellfish)
// output:
// 19
type ByteSize float64
const (
_ = iota // ignore first value by assigning to blank identifier
KB ByteSize = 1 << (10 * iota) // 1 << (10*1)
MB // 1 << (10*2)
GB // 1 << (10*3)
TB // 1 << (10*4)
PB // 1 << (10*5)
EB // 1 << (10*6)
ZB // 1 << (10*7)
YB // 1 << (10*8)
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
当你在把两个常量定义在一行的时候会发生什么?
Banana 的值是什么? 2 还是 3? Durian 的值又是?
const (
Apple, Banana = iota + 1, iota + 2
Cherimoya, Durian
Elderberry, Fig
)
// Apple: 1
// Banana: 2
// Cherimoya: 2
// Durian: 3
// Elderberry: 3
// Fig: 4
2
3
4
5
6
7
8
9
10
11
12
# 4. 函数
函数返回值
可以返回一个值,也可以返回多个值
package main
import (
"fmt"
)
func main() {
f1 := foo1()
fmt.Println("foo1 res=", f1)
f2 := foo2()
fmt.Println("foo2 res=", f2)
f3a, f3b := foo3()
fmt.Println("foo3a res=", f3a, "foo3b res=", f3b)
f4a, f4b := foo4()
fmt.Println("foo4a res=", f4a, "foo4b res=", f4b)
}
// 只有一个匿名返回值
func foo1() int {
return 1
}
// 只有一个有名返回值,有名返回值如果不赋值,则默认为0
func foo2() (res int) {
return res
}
// 定义多个匿名返回值
func foo3() (int, string) {
return 1, "s"
}
// 定义多个有名返回值
func foo4() (num int, s string) {
num = 1
s = "ggg"
return num, s
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 5. 导包相关
init函数
首先我们看一个例子:init函数:
init 函数可在package main中,可在其他package中,可在同一个package中出现多次。
main函数
main 函数只能在package main中。
执行顺序
golang里面有两个保留的函数:init函数(能够应用于所有的package)和main函数(只能应用于package main)。这两个函数在定义时不能有任何的参数和返回值。
虽然一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。
go程序会自动调用init()和main(),所以你不需要在任何地方调用这两个函数。每个package中的init函数都是可选的,但package main就必须包含一个main函数。
程序的初始化和执行都起始于main包。
如果main包还导入了其它的包,那么就会在编译时将它们依次导入。有时一个包会被多个包同时导入,那么它只会被导入一次(例如很多包可能都会用到fmt包,但它只会被导入一次,因为没有必要导入多次)。
当一个包被导入时,如果该包还导入了其它的包,那么会先将其它包导入进来,然后再对这些包中的包级常量和变量进行初始化,接着执行init函数(如果有的话),依次类推。
等所有被导入的包都加载完毕了,就会开始对main包中的包级常量和变量进行初始化,然后执行main包中的init函数(如果存在的话),最后执行main函数。下图详细地解释了整个执行过程:
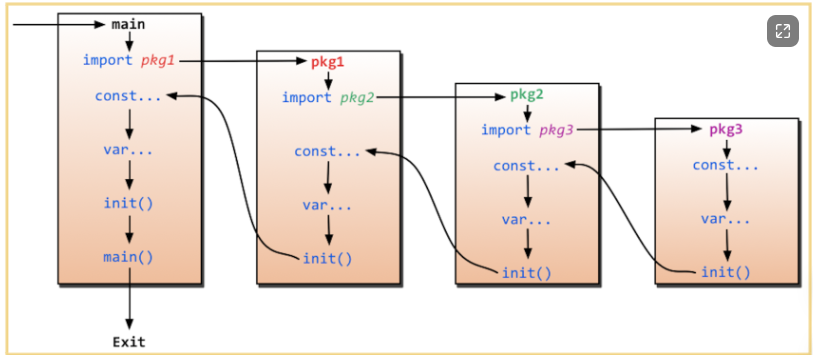
首先我们看一个例子:
代码结构:

Lib1.go
package InitLib1
import "fmt"
func init() {
fmt.Println("lib1")
}
2
3
4
5
6
7
Lib2.go
package InitLib2
import "fmt"
func init() {
fmt.Println("lib2")
}
2
3
4
5
6
7
main.go
package main
import (
"fmt"
_ "GolangTraining/InitLib1" //匿名导包,因为直接导包,编译器要求直接使用才行。我们的需求可能是不使用包,但是调用对应包的init函数,就可以用匿名函数
_ "GolangTraining/InitLib2"
)
func init() {
fmt.Println("libmain init")
}
func main() {
fmt.Println("libmian main")
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
lib1
lib2
libmain init
libmian main
2
3
4
输出的顺序与我们上面图给出的顺序是一致的
那我们现在就改动一个地方,Lib1包导入Lib2,main包不管
package InitLib1
import (
"fmt"
_ "GolangTraining/InitLib2"
)
func init() {
fmt.Println("lib1")
}
2
3
4
5
6
7
8
9
10
输出
lib2
lib1
libmain init
libmian main
2
3
4
main包以及Lib1包都导入了Lib2,但是只出现一次,并且最先输出,
说明如果一个包会被多个包同时导入,那么它只会被导入一次,而先输出lib2是因为main包中导入Lib1时,Lib1又导入了Lib2,会首先初始化Lib2包的东西
有名导包:
import myfmt "fmt" //程序中使用别名 import . "fmt" //直接把fmt中所有的方法导入到本包中,可以直接调用(不建议使用,防止多个方法产生歧义)1
2
总结导包的几种方式
import "fmt"
import . "fmt"
import my "fmt"
import _ "fmt"
2
3
4
# 6.指针
函数如果使用参数,该变量可称为函数的形参。
形参就像定义在函数体内的局部变量。
调用函数,可以通过两种方式来传递参数:
值传递:
值传递是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
默认情况下,Go 语言使用的是值传递,即在调用过程中不会影响到实际参数。
以下定义了 swap() 函数:
/* 定义相互交换值的函数 */
func swap(x, y int) int {
var temp int
temp = x /* 保存 x 的值 */
x = y /* 将 y 值赋给 x */
y = temp /* 将 temp 值赋给 y*/
return temp;
}
2
3
4
5
6
7
8
9
10
11
12
# 引用传递(指针传递)
我们都知道,变量是一种使用方便的占位符,用于引用计算机内存地址。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
以下实例演示了变量在内存中地址:
package main
import "fmt"
func main() {
var a int = 10
fmt.Printf("变量的地址: %x\n", &a )
}
2
3
4
5
6
7
8
9
10
11
12
变量的地址: 20818a220
现在我们已经了解了什么是内存地址和如何去访问它。接下来我们将具体介绍指针。
引用传递是指在调用函数时将实际参数的地址传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
引用传递指针参数传递到函数内,以下是交换函数 swap() 使用了引用传递:
/* 定义交换值函数*/
func swap(x *int, y *int) {
var temp int
temp = *x /* 保持 x 地址上的值 */
*x = *y /* 将 y 值赋给 x */
*y = temp /* 将 temp 值赋给 y */
}
2
3
4
5
6
7
package main
import "fmt"
func main() {
/* 定义局部变量 */
var a int = 100
var b int= 200
fmt.Printf("交换前,a 的值 : %d\n", a )
fmt.Printf("交换前,b 的值 : %d\n", b )
/* 调用 swap() 函数
* &a 指向 a 指针,a 变量的地址
* &b 指向 b 指针,b 变量的地址
*/
swap(&a, &b)
fmt.Printf("交换后,a 的值 : %d\n", a )
fmt.Printf("交换后,b 的值 : %d\n", b )
}
func swap(x *int, y *int) {
var temp int
temp = *x /* 保存 x 地址上的值 */
*x = *y /* 将 y 值赋给 x */
*y = temp /* 将 temp 值赋给 y */
}
以上代码执行结果为:
交换前,a 的值 : 100
交换前,b 的值 : 200
交换后,a 的值 : 200
交换后,b 的值 : 100
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
二级指针:
二级指针一般用于保存一级指针
a:=10
var p *int = &a
var pp **int = &p
2
3
# 7.defer语句
defer语句被用于预定对一个函数的调用。可以把这类被defer语句调用的函数称为延迟函数。
defer作用:
- 释放占用的资源
- 捕捉处理异常
- 输出日志
如果一个函数中有多个defer语句,它们会以LIFO(后进先出)的顺序执行。stack
func Demo(){
defer fmt.Println("1")
defer fmt.Println("2")
defer fmt.Println("3")
defer fmt.Println("4")
}
func main() {
Demo()
}
2
3
4
5
6
7
8
9
4
3
2
1
2
3
4
另外defer是在return执行后执行的
func main() {
foo()
}
func foo() int{
deferfunc()
return returnfunc()
}
func deferfunc() int {
fmt.Println("defer exec")
return 0
}
func returnfunc() int{
fmt.Println("return exec")
return 0
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
return exec
defer exec
2
# 8. 数组
//固定长度数组
func main() {
var arr [10]int //定义数组,未初始化
for i := 0; i < len(arr); i++ {
fmt.Println(arr[i])
}
myArr := [10]int{1, 3, 5}
for index, value := range myArr {
fmt.Println("index=", index, " value = ", value)
}
fmt.Printf("type = %T\n", myArr)
//type = [10]int
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
对于定长的数组,如果创建出来的数组长度为10,则其的type类型为[10]int;如果其长度为15,则type类型为[15]int。那么这样就会出现一个问题,那么对于函数的传参如果要传递数组怎么办呢?可能其长度不一样,则传入的类型不一样,会报错。
这个时候,就可以使用go中的变长数组了
# 9.动态数组slice
func main() {
arr := []int{3, 45, 2} //定义动态数组
fmt.Println(arr)
fmt.Printf("type is %T\n", arr)
swap(arr, 0, len(arr)-1)
fmt.Println(arr)
fmt.Printf("main arr addr = %X\n", &arr)
}
func swap(arr []int, a int, b int) { //结果可以看出slice是引用传递
temp := arr[a]
arr[a] = arr[b]
arr[b] = temp
fmt.Printf("swap arr addr = %X\n", &arr)
}
[3 45 2]
type is []int
swap arr addr = &[2 2D 3]
[2 45 3]
main arr addr = &[2 2D 3]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
声明动态数组的几种方式
func main() {
//动态数组的声明方式
//1.声明slice,并初始化赋值
slice1 := []int{3, 4, 5}
fmt.Println("slice1 = ", slice1)
//2.声明了slice,但是并没有分配内存空间,这是slice是不可用的
var slice2 []int
fmt.Println("slice2 = ", slice2)
if slice2 == nil {
fmt.Println("slice2 = ", slice2)
}
//3.声明slice,并为其分配3大小的内存空间
var slice3 []int = make([]int, 3)
fmt.Println("slice3 = ", slice3)
}
slice1 = [3 4 5]
slice2 = []
slice2 = []
slice3 = [0 0 0]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
一般声明用第三种方式。
nil可以看一个slice是否被分配了内存
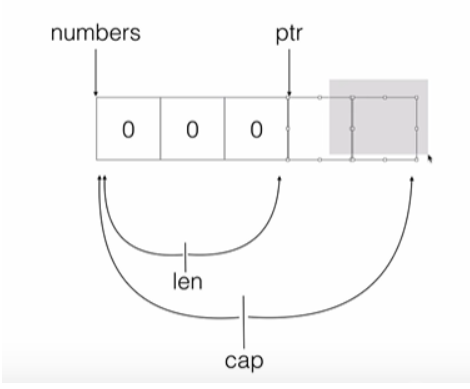
- 切片的追加
func main() {
//1. 创建一个slice,初始化长度为5,容量为10
arr := make([]int, 5, 7)
fmt.Printf("arr len=%d,arr cap=%d,arr = %v\n", len(arr), cap(arr), arr)
//arr len=5,arr cap=10,arr = [0 0 0 0 0]
//2. 使用append函数,其中arr1和arr其实指向的是同一个内存空间,因为其cap和len不一样,所以展示的结果不一样
arr1 := append(arr, 6)
fmt.Printf("arr len=%d,arr cap=%d,arr = %v\n", len(arr), cap(arr), arr)
fmt.Printf("arr1 len=%d,arr1 cap=%d,arr1 = %v\n", len(arr1), cap(arr1), arr1)
//arr len=5,arr cap=7,arr = [0 0 0 0 0]
//arr1 len=6,arr1 cap=7,arr1 = [0 0 0 0 0 6]
//3. 当append函数追加超过容量时,会扩大为原来的两倍
arr = append(arr, 6)
fmt.Printf("arr len=%d,arr cap=%d,arr = %v\n", len(arr), cap(arr), arr)
arr = append(arr, 7)
fmt.Printf("arr len=%d,arr cap=%d,arr = %v\n", len(arr), cap(arr), arr)
arr = append(arr, 8)
fmt.Printf("arr len=%d,arr cap=%d,arr = %v\n", len(arr), cap(arr), arr)
//arr len=6,arr cap=7,arr = [0 0 0 0 0 6]
//arr len=7,arr cap=7,arr = [0 0 0 0 0 6 7]
//arr len=8,arr cap=14,arr = [0 0 0 0 0 6 7 8]
//append(arr, 7)
//append(arr, 8)
}
//长度>1024的时候,扩充为原来的1/4,并不总是双倍
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
其中2点:

两个变量指向的是同一内存空间,下面代码可以证明
arr[1] = 3
fmt.Printf("arr len=%d,arr cap=%d,arr = %v\n", len(arr), cap(arr), arr)
fmt.Printf("arr1 len=%d,arr1 cap=%d,arr1 = %v\n", len(arr1), cap(arr1), arr1)
//arr len=5,arr cap=7,arr = [0 3 0 0 0]
//arr1 len=6,arr1 cap=7,arr1 = [0 3 0 0 0 6]
2
3
4
5
6
结果发现两者展示结果都发生了改变,表示他们指向的是同一个内存空间
- slice的截取
类似python
package main
import "fmt"
func main() {
/* 创建切片 */
numbers := []int{0,1,2,3,4,5,6,7,8}
printSlice(numbers)
/* 打印原始切片 */
fmt.Println("numbers ==", numbers)
/* 打印子切片从索引1(包含) 到索引4(不包含)*/
fmt.Println("numbers[1:4] ==", numbers[1:4])
/* 默认下限为 0*/
fmt.Println("numbers[:3] ==", numbers[:3])
/* 默认上限为 len(s)*/
fmt.Println("numbers[4:] ==", numbers[4:])
numbers1 := make([]int,0,5)
printSlice(numbers1)
/* 打印子切片从索引 0(包含) 到索引 2(不包含) */
number2 := numbers[:2]
printSlice(number2)
/* 打印子切片从索引 2(包含) 到索引 5(不包含) */
number3 := numbers[2:5]
printSlice(number3)
}
func printSlice(x []int){
fmt.Printf("len=%d cap=%d slice=%v\n",len(x),cap(x),x)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
len=9 cap=9 slice=[0 1 2 3 4 5 6 7 8]
numbers == [0 1 2 3 4 5 6 7 8]
numbers[1:4] == [1 2 3]
numbers[:3] == [0 1 2]
numbers[4:] == [4 5 6 7 8]
len=0 cap=5 slice=[]
len=2 cap=9 slice=[0 1]
len=3 cap=7 slice=[2 3 4]
2
3
4
5
6
7
8
注意,切片的返回值和上面append一样,都是指向的同一个内存空间
注意这里切片cap和len的改变

其中numbers的cap因为最前面少了2,所以cap也减少了2
# map
定义方式
//方式1
var mymap1 map[string]string
mymap1 = make(map[string]string, 5)
mymap1["java"] = "1"
fmt.Println(mymap1)
//方式2
mymap2 := make(map[string]int)
//方式3
mymap3 := map[string]string{
"java": "1",
"c++": "2",
}
2
3
4
5
6
7
8
9
10
11
12
13
14
map的基本使用
func main() {
myMap := make(map[string]string)
//新增
myMap["java"] = "1"
myMap["go"] = "2"
//修改
myMap["java"] = "2"
//遍历
for key, value := range myMap {
fmt.Println("key=", key, " value=", value)
}
fmt.Println("===================")
//删除
delete(myMap, "go")
for key, value := range myMap {
fmt.Println("key=", key, " value=", value)
}
}
key= java value= 2
key= go value= 2
===================
key= java value= 2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 结构体
type关键字用于定义自定义类型别名,以及其他复杂类型的声明。struct关键字用于定义结构体类型,用于组织和管理相关的字段数据。
type myint int
func main() {
var name myint = 10
fmt.Printf("type is %T\n", name)
}
//type is main.myint
2
3
4
5
6
7
8
type student struct {
name string
id int
}
func main() {
//创建结构体1
mystu1 := student{
id: 2,
name: "zj",
}
//创建结构体2
var mystu2 student
mystu2.id = 1
mystu2.name = "z"
fmt.Println(mystu1)
fmt.Println(mystu2)
//{zj 2}
//{z 1}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 类
封装
type student struct {
name string
id int
}
func (this *student) SetName(name string) {
this.name=name
}
func (this *student) GetName() string {
return this.name
}
2
3
4
5
6
7
8
9
10
11
12
13
注意,其中的结构名、方法名、成员名首字母大写,表示是对外开放的,小写则是私有的。结构体中的方法传递,默认是值传递,所以我们在方法中需要加上指针。
继承
type human struct {
id int
name string
}
func (this *human) SetName(name string) {
this.name = name
}
func (this *human) GetName() string {
return this.name
}
type superHuman struct {
human //继承,这里表示superHuman继承了human
level int
}
func (this *superHuman) SetName(name string) { //重写父类的方法
this.name = "superName" + name
}
func fly() { //新增方法
fmt.Println("superHuman fly")
}
func main() {
sh1 := superHuman{human{1, "zj"}, 1}
fmt.Println(sh1)
sh1.SetName("zjj")
fmt.Println(sh1)
//{{1 zj} 1}
//{{1 superNamezjj} 1}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
多态
接口定义
package main
import "fmt"
// 如何定义一个接口
type AnimalIF interface {
Sleep()
GetColor() string
GetType() string
}
// 如何定义接口的实现类。必须重写所有的接口的方法,才能使实现接口,否则就是一个普通的类
type Dog struct {
color string
t string
}
func (this *Dog) Sleep() {
fmt.Println("dog is sleeping")
}
func (this *Dog) GetColor() string {
return "Dog color"
}
func (this *Dog) GetType() string {
return "Dog type"
}
// 如何定义接口的实现类。必须重写所有的接口的方法,才能使实现接口,否则就是一个普通的类
type Cat struct {
color string
t string
}
func (this *Cat) Sleep() {
fmt.Println("cat sleep")
}
func (this *Cat) GetColor() string {
return "cat color"
}
func (this *Cat) GetType() string {
return "cat type"
}
func main() {
//接口变量指向实现的地址(注意,接口变量本质是指针,所以需要指向地址)
var animal1 AnimalIF = &Dog{"green", "dog"}
animal1.Sleep()
fmt.Println(animal1.GetColor())
fmt.Println(animal1.GetType())
var animal2 AnimalIF = &Cat{"blue", "cat"}
animal2.Sleep()
fmt.Println(animal2.GetColor())
fmt.Println(animal2.GetType())
//dog is sleeping
//Dog color
//Dog type
//cat sleep
//cat color
//cat type
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
# go中的“object”
其实在go中所有的类型如int 、string、float、struct等都实现了一个空接口interface{}。类似于java中的Object
空接口类型可以体现在函数参数中。
type student struct {
}
func main() {
foo(1)
foo("1")
foo(1.1)
foo(student{})
}
func foo(arg interface{}) { //形参是空接口
fmt.Printf("arg=%v,type is %T\n", arg, arg)
t, f := arg.(string) //判断空接口是什么类型
if f {
fmt.Println("type is string")
} else {
fmt.Println("type is ", t)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# pair
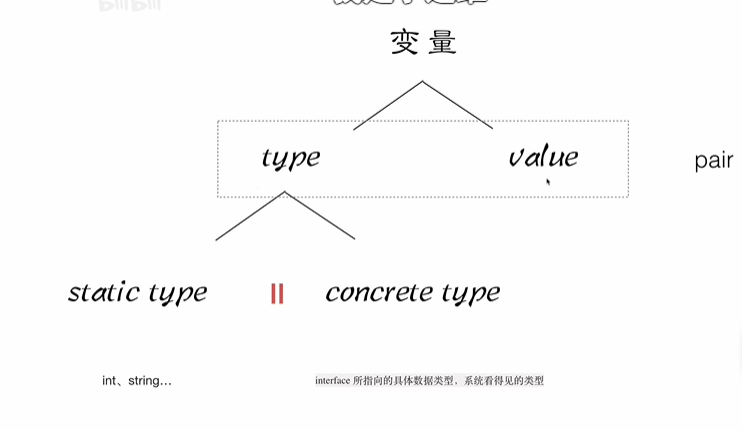
如图,在变量中,总有一个pair,分别是type和value
func main() {
//pair type:int value 3
var a int = 3
var alltype=interface{} = a
key, value := alltype.(int)
fmt.Println(key, " ", value)
//3 true
}
2
3
4
5
6
7
8
9
10
可以看到a即使传递给了alltype这个全类型,其中的pair也会进行传递

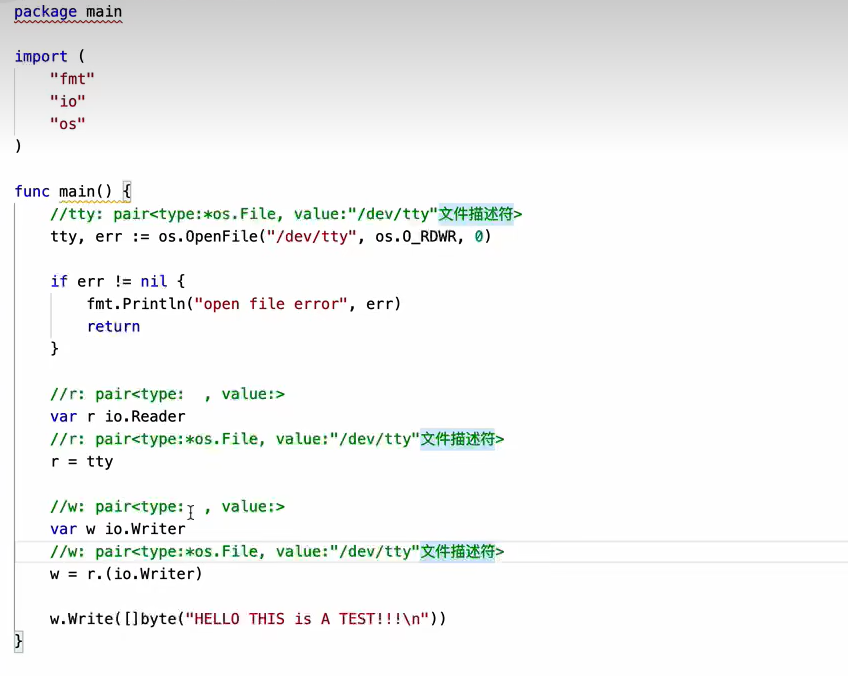


反射

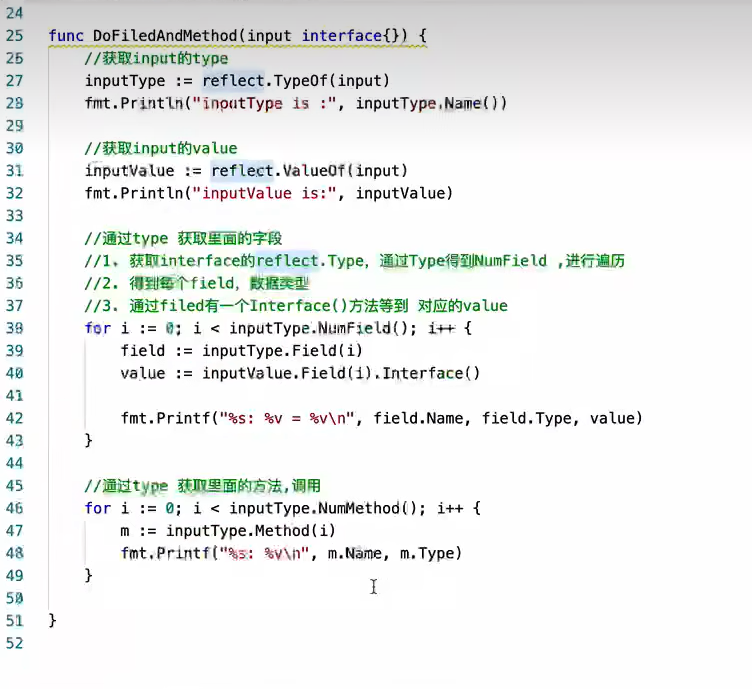
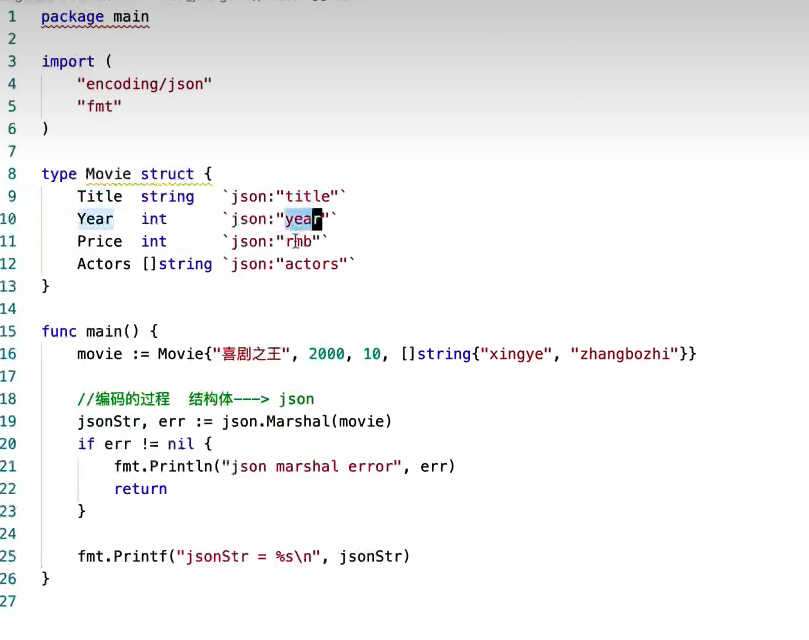
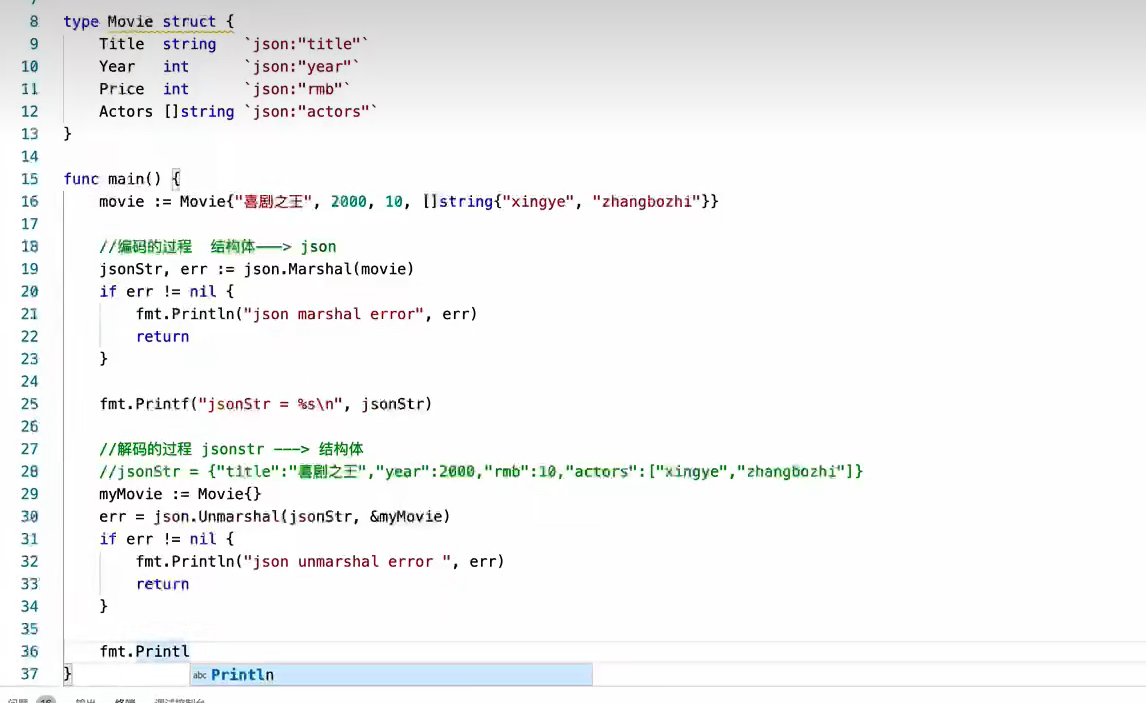
结构体标签

标签需要通过反射来获取
json标签作用
# select语句
官方解释:一个select语句用来选择哪个case中的发送或接收操作可以被立即执行。它类似于switch语句,但是它的case涉及到channel有关的I/O操作。即select就是用来监听和channel有关的IO操作,当 IO 操作发生时,触发相应的动作。
要点:
如果有一个或多个IO操作可以完成,则Go运行时系统会随机的选择一个执行,否则的话,如果有default分支,则执行default分支语句,如果连default都没有,则select语句会一直阻塞,直到至少有一个IO操作可以进行
所有channel表达式都会被求值、所有被发送的表达式都会被求值。求值顺序:自上而下、从左到右.
用法:
- 使用 select 实现 timeout 机制
timeout := make (chan bool, 1)
go func() {
time.Sleep(1e9) // sleep one second
timeout <- true
}()
select {
case <- timeout:
fmt.Println("timeout!")
}
2
3
4
5
6
7
8
9
- 使用 select 语句来检测 chan 是否已经满了
ch2 := make (chan int, 1)
ch2 <- 1
select {
case ch2 <- 2:
default:
fmt.Println("channel is full !")
}
2
3
4
5
6
7
- for-select
package main
import (
"fmt"
"time"
)
func main() {
var errChan = make(chan int)
//定时2s
ticker := time.NewTicker(2 * time.Second)
defer ticker.Stop()
go func(a chan int) {
//5s发一个信号
time.Sleep(time.Second * 5)
errChan <- 1
}(errChan)
LOOP:
for {
select {
case <-ticker.C: {
fmt.Println("Task still running")
}
case res, ok := <-errChan:
if ok {
fmt.Println("chan number:", res)
break LOOP
}
}
}
fmt.Println("end!!!")
}
//输出结果:
//Task still running
//Task still running
//chan number: 1
//end!!!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37