
 LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder
# 背景
对于netty应用,当一串数据来到时,是以一串字节流传递过来的,但是我们并不知道这一串的字节流什么是开头什么是结尾,所以我们需要在客户端和服务端制定相应的协议。当数据到来时,根据相应的协议进行 “拆包”。
之所以netty的拆包能做到如此强大,就是因为netty将具体如何拆包抽象出一个decode方法,不同的拆包器实现不同的decode方法,就能实现不同协议的拆包。这篇文章中要讲的就是通用拆包器LengthFieldBasedFrameDecoder,如果你还在自己实现人肉拆包,不妨了解一下这个强大的拆包器,因为几乎所有和长度相关的二进制协议都可以通过TA来实现。
# 用法
# 1. 基于长度的拆包

上面这类数据包协议比较常见的,前面几个字节表示数据包的长度(不包括长度域),后面是具体的数据。拆完之后数据包是一个完整的带有长度域的数据包(之后即可传递到应用层解码器进行解码),创建一个如下方式的LengthFieldBasedFrameDecoder即可实现这类协议
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 4);
其中 1.第一个参数是 maxFrameLength 表示的是包的最大长度,超出包的最大长度netty将会做一些特殊处理,后面会讲到 2.第二个参数指的是长度域的偏移量lengthFieldOffset,在这里是0,表示无偏移 3.第三个参数指的是长度域长度lengthFieldLength,这里是4,表示长度域的长度为4
以上是一个最简单的拆包构造方法,但是一般正常的netty应用的制定的协议不会有这么简单的,一般很少用。
# 2. 基于长度的截断拆包
如果我们的应用层解码器不需要使用到长度字段,那么我们希望netty拆完包之后,是这个样子:

长度域被截掉,我们只需要指定另外一个参数就可以实现,这个参数叫做 initialBytesToStrip,表示netty拿到一个完整的数据包之后向业务解码器传递之前,应该跳过多少字节
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 4, 0, 4);
前面三个参数的含义和上文相同,第四个参数我们后面再讲,而这里的第五个参数就是initialBytesToStrip,这里为4,表示获取完一个完整的数据包之后,忽略前面的四个字节,应用解码器拿到的就是不带长度域的数据包
# 3. 基于偏移长度的拆包
下面这种方式二进制协议是更为普遍的,前面几个固定字节表示协议头,通常包含一些magicNumber,protocol version 之类的meta信息,紧跟着后面的是一个长度域,表示包体有多少字节的数据

只需要基于第一种情况,调整第二个参数既可以实现
new LengthFieldBasedFrameDecoder(Integer.MAX, 4, 4);
lengthFieldOffset 是4,表示跳过4个字节之后的才是长度域
# 4.基于可调整长度的拆包
有些时候,二进制协议可能会设计成如下方式

即长度域在前,header在后,这种情况又是如何来调整参数达到我们想要的拆包效果呢?
1.长度域在数据包最前面表示无偏移,lengthFieldOffset 为 0 2.长度域的长度为3,即lengthFieldLength为3 2.长度域表示的包体的长度略过了header,这里有另外一个参数,叫做 lengthAdjustment,包体长度调整的大小,长度域的数值表示的长度加上这个修正值表示的就是带header的包,这里是 12+2,header和包体一共占14个字节
最后,代码实现为
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 3, 2, 0);
# 5.基于偏移可调整长度的截断拆包
更变态一点的二进制协议带有两个header,比如下面这种

拆完之后,HDR1 丢弃,长度域丢弃,只剩下第二个header和有效包体,这种协议中,一般HDR1可以表示magicNumber,表示应用只接受以该magicNumber开头的二进制数据,rpc里面用的比较多
我们仍然可以通过设置netty的参数实现
1.长度域偏移为1,那么 lengthFieldOffset为1 2.长度域长度为2,那么lengthFieldLength为2 3.长度域表示的包体的长度略过了HDR2,但是拆包的时候HDR2也被netty当作是包体的的一部分来拆,HDR2的长度为1,那么 lengthAdjustment 为1 4.拆完之后,截掉了前面三个字节,那么 initialBytesToStrip 为 3
最后,代码实现为
new LengthFieldBasedFrameDecoder(Integer.MAX, 1, 2, 1, 3);
# 6.基于偏移可调整变异长度的截断拆包
前面的所有的长度域表示的都是不带header的包体的长度,如果让长度域表示的含义包含整个数据包的长度,比如如下这种情况

其中长度域字段的值为16, 其字段长度为2,HDR1的长度为1,HDR2的长度为1,包体的长度为12,1+1+2+12=16,又该如何设置参数呢?
这里除了长度域表示的含义和上一种情况不一样之外,其他都相同,因为netty并不了解业务情况,你需要告诉netty的是,长度域后面,再跟多少字节就可以形成一个完整的数据包,这里显然是13个字节,而长度域的值为16,因此减掉3才是真是的拆包所需要的长度,lengthAdjustment为-3
new LengthFieldBasedFrameDecoder(Integer.MAX, 1, 2, -3, 3);
这里的六种情况是netty源码里自带的六中典型的二进制协议,相信已经囊括了90%以上的场景,如果你的协议是基于长度的,那么可以考虑不用字节来实现,而是直接拿来用,或者继承他,做些简单的修改即可
# 总结
# maxFrameLength
一般为Integer.MAX_VALUE,指定帧的最大长度
# lengthFieldOffset
长度字段的偏移量位置
# lengthFieldLength
长度字段占用的大小
# lengthAdjustment
长度补偿。 实际的长度字段应该表示,长度字段所比表示的长度为长度数据字段后的长度。
- 但是我们一般长度字段可能表示的是整个数据包的长度,例如:

此时长度字段表示的长度为15byte。指定的数据如图所示:
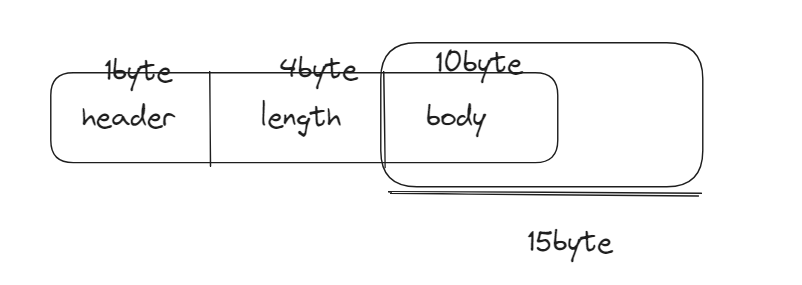
可以看到实际读的时候会多出5byte,所以我们的 lengthAdjustment = -5
- 有时候我们的length字段后面可能还有header字段,我们也想要获取,如:
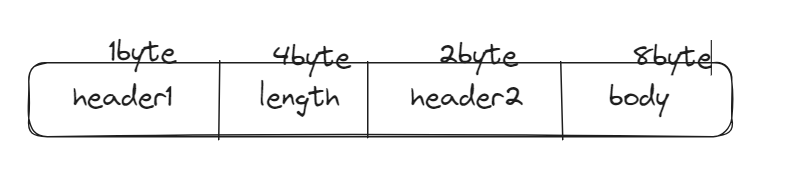
此时字段length表示的长度为15byte,实际情况如下:
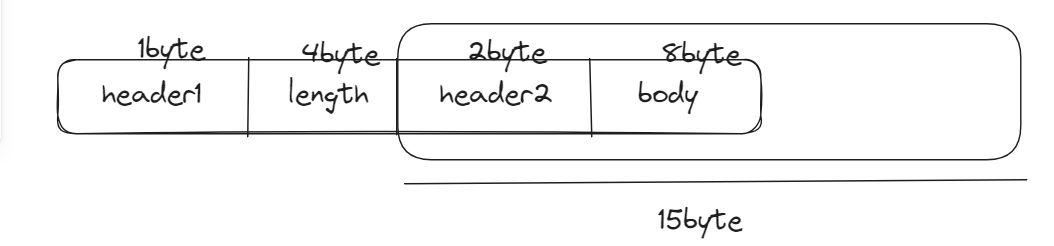
我们需要读取的是header2+body=10byte,所以我们lengthAdjustment 为-5byte就对了
# initialBytesToStrip
跳过多少字节