
 go数据结构的内存实现
go数据结构的内存实现
# Basic types

变量 i 的类型为 int,在内存中表示为一个32位单词。(所有这些图片都显示了一个32位的内存布局; 在当前的实现中,只有指针在64位的机器上变大ーー int 仍然是32位ーー尽管实现可以选择使用64位。)
由于显式转换,变量 j 的类型为 int32。尽管 i 和 j 具有相同的内存布局,但它们具有不同的类型: 赋值 i = j 是一个类型错误,必须使用显式转换写入: i = int (j)。
变量 f 具有 float 类型,当前实现将其表示为32位浮点值。它具有与 int32相同的内存占用,但是内部布局不同。
# Structs and pointers
现在情况开始好转了。可变字节类型为[5]字节,数组为5个字节。它的内存表示就是那5个字节,一个接一个,就像 C 数组一样。类似地,素数是一个由4整数组成的数组。
Go 与 C 类似,但与 Java 不同,它让程序员可以控制什么是指针,什么不是指针。例如,此类型定义:
type Point struct { X,Y int }
定义一个名为 Point 的简单结构类型,在内存中表示为两个相邻的 int。
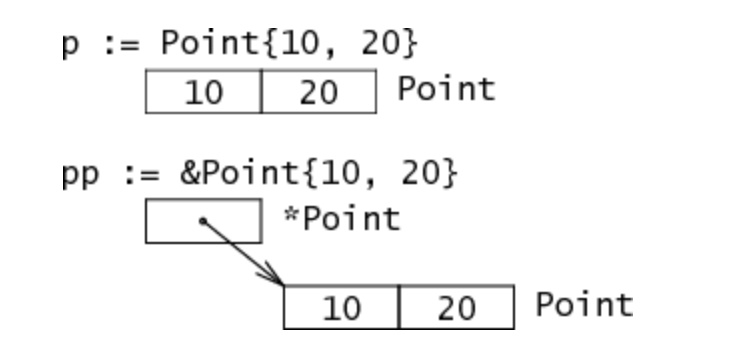
复合数据类型 Point {10,20}表示一个初始化的 Point。获取组合文字的地址表示指向新分配和初始化的 Point 的指针。前者是存储器中的两个单词,后者是指向存储器中的两个单词的指针。
结构中的字段在内存中并排布置。

Rect1, a struct with two Point fields, is represented by two Points—four ints—in a row. Rect2, a struct with two *Point fields, is represented by two *Points.
# strings
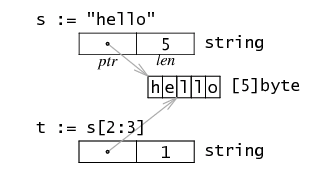
(灰色箭头表示实现中存在但在程序中不能直接看到的指针。)
字符串在内存中表示为一个2字结构,其中包含一个指向字符串数据的指针和一个长度。因为字符串是不可变的,所以多个字符串共享相同的存储空间是安全的,所以切片 s 会产生一个新的2字结构,指针和长度可能不同,但仍然引用相同的字节序列。这意味着可以在不进行分配或复制的情况下进行切片,从而使字符串切片与传递显式索引一样高效。
(顺便说一句,在 Java 和其他语言中有一个众所周知的陷阱,当你切割一个字符串来保存一小块时,对原始字符串的引用会将整个原始字符串保存在内存中,即使仍然只需要一小部分。这个也抓到你了。另一种选择是让字符串切片变得非常昂贵(包括分配和复制) ,以至于大多数程序都会避免这种做法。)
# slices

切片是对数组的一个部分的引用。在内存中,它是一个3字结构,包含指向第一个元素的指针、切片的长度和容量。
像切片字符串一样,切片数组不会产生副本: 它只会创建一个新结构,其中包含不同的指针、长度和容量。
在本例中,复合数据 [] int {2,3,5,7,11}将创建一个包含五个值的新数组,然后设置slice x 的字段来描述该数组。slice x [1:3]不分配更多的数据: 它只是写入一个新的片结构的字段来引用同一个后台存储。在这个例子中,长度是2,即 y [0] ,y [1]是唯一有效的索引;但容量是4, y [0:4]是一个有效的片表达式。
因为切片是多字结构,而不是指针,所以切片操作不需要分配内存,甚至不需要为通常可以保存在堆栈上的切片头分配内存。这种表示使得切片的使用成本与传递 C 中的显式指针和长度对一样低廉。 Go 最初将切片表示为指向上面所示结构的指针,但是这样做意味着每个切片操作都分配了一个新的内存对象。即使使用快速分配器,也会为垃圾收集器创建大量不必要的工作,我们发现,就像上面的字符串一样,程序避免了切片操作,而更倾向于传递显式索引。在大多数情况下,删除间接和分配使得切片的成本足够低,可以避免传递显式索引。
# new and make
Go 有两个数据结构创建函数: new 和 make。这种区别是一个常见的早期混淆点,但似乎很快就变得自然。最基本的区别是 new (T)返回一个 * T 指针类型,一个 Go 程序可以隐式取消引用的指针(图中的黑色指针) ,而 make (T,args)返回一个普通的 T,而不是一个指针。通常 T 中有一些隐式指针(图中的灰色指针)。New 返回一个指向零内存的指针,而 make 返回一个复杂结构。

make 只能用来分配及初始化类型为数组、slice、map、chan 的数据。 new 可以分配任意类型的数据; new 分配返回的是指针,即类型*Type。
更深入可以参考:Go语言make和new关键字的区别及实现原理 (opens new window)